Definizione: architettura dei DBMS
Un DBMS è tipicamente formato da:
- Un gestore delle transazioni
- Un serializzatore
- Un gestore del ripristino
- Un gestore del buffer
- Una memoria
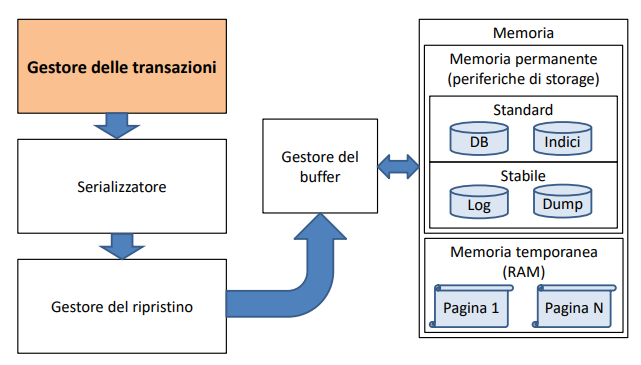
Componenti dell’architettura
Gestore delle transazioni
Definizione: gestore delle transazioni
Il gestore delle transazioni è una componente dell’architettura dei DBMS che si occupa di gestire il ciclo di vita delle transazioni inviando i comandi DML alle altre componenti dell’architettura che devono eseguire l’azione richiesta.
Serializzatore
Definizione: serializzatore
Il serializzatore è una componente dell’architettura dei DBMS che si occupa di assicurare l’isolamento di ogni transazione.
Gestore del ripristino
Definizione: gestore del ripristino
Il gestore del ripristino è una componente dell’architettura dei DBMS che si occupa di effettuare il rollback e assicurare l’atomicità e la consistenza di ogni transazione.
Gestore del buffer
Definizione: gestore del buffer
Il gestore del buffer è una componente dell’architettura dei DBMS che si occupa di assicurare la durabilità di ogni transazione.
Gestione della memoria
Suddivisione della memoria
Definizione: pagina
Definizione: caricamento delle pagine
Il caricamento delle pagine è il processo in cui una pagina viene caricata nel buffer dal gestore del buffer, prendendola dalla periferica di storage se non già presente nel buffer.
Definizione: blocchi fisici
I blocchi fisici sono porzioni di memoria in cui viene suddivisa una pagina, tipicamente di dimensioni che vanno dai ai .
Ordinamento dei record
Ottimizzazione fisica
Ricordiamo che l’ottimizzatore fisico prende in input un albero di parsificazione modificato dall’ottimizzatore logico e corrispondente ad un’interrogazione DML. L’ottimizzatore si basa innanzitutto sui metodi di accesso, cioè deve scegliere come accedere ai dati richiesti Tutti i DBMS possono presentare più modalità di accesso ai dati
Esistono tre grandi categorie di metodi di accesso:
- Metodo di accesso sequenziale/seriale
- Metodo d’accesso tabellare
- Metodo d’accesso diretto
Metodo d’accesso sequenziale/seriale
Definizione: metodo d'accesso sequenziale
L’accesso sequenziale implica l’ordinamento su un attributo, ad esempio, nella tavola STUDENTE, posso decidere di ordinare sulla matricola o sul nome e le tuple vengono caricate nelle pagine seguendo l’ordinamento
Definizione: metodo d'accesso seriale
L’accesso seriale implica l’assenza di ordinamenti e le tuple sono caricate nelle pagine così come arrivano dal file system
Come fa l’ottimizzatore fisico a valutare il vantaggio dell’uso di queste tecniche al posto di altre? Immaginiamo una selezione:
Consideriamo un’organizzazione dei dati secondo un accesso seriale.Avremo un’organizzazione a pagine da Pagina 1 a pagina N: il DBMS, non può far altro che leggere le pagine una dopo l’altra
Dal momento che MATR è chiave, avremo un’unica tupla (record) che sarà contenuta in una determinata pagina.Il metodo è essenzialmente una scansione delle pagine una dopo l’altra
Il DBMS deve calcolare il costo a priori dell’accesso. Esistono dei modelli statistici per il calcolo del costo Il modello statistico più semplice è di considerare una distribuzione di probabilità che dica la probabilità di trovare il record nella pagina Il costo medio è quindi:
dove è il numero di pagine lette e è la probabilità che la tupla sia nella pagina .
Occorre però disporre della distribuzione di probabilità, che nella maggior parte dei casi non è disponibile. Si utilizza l’ipotesi della distribuzione uniforme: la tupla ha la stessa probabilità di trovarsi in una qualsiasi pagina.
In questo caso la formula si semplifica (per ogni , ) e diventa
Il costo della ricerca con successo è quindi (N+1)/2 (circa la metà delle pagine), mentre il costo della ricerca con insuccesso è N
Se utilizzo un’organizzazione ordinata (ordinamento su un attributo), cambia solo il costo della ricerca con insuccesso, infatti non ho bisogno di scorrere tutte le pagine, ma mi arresto quando ho superato il valore richiesto
Il costo della ricerca (sequenziale) con insuccesso è uguale a quello della ricerca con successo: (N+1)/2
Cosa succede se effettuo una selezione su un attributo non chiave?
In questo caso, devo scorrere tutte le pagine: costo
Stesso discorso per le ricerche di range (<, >, between)
Osservazione: Gli accessi sequenziali e seriali hanno costi che sono dell’ordine del numero delle pagine (nel miglior caso: metà delle pagine). Questa organizzazione è troppo costosa se pensiamo a sistemi informativi con migliaia di pagine per le tabelle
Metodo d’accesso tabellare
E’ il metodo di accesso più importante, in quanto si avvale degli indici • Gli indici sono uno degli aspetti più importanti nella progettazione fisica di un DB • Bisogna conoscerne vantaggi e svantaggi
L’indice è una struttura separata dall’area primaria (l’area che contiene le pagine dati) • Prima di introdurre gli indici, studieremo (ripasseremo) brevemente la struttura dati B-albero • E’ la struttura utilizzata nella maggior parte dei sistemi che implementano indici accanto alle tavole primarie
Definizione: B-albero
Il B-albero è un albero semi-bilanciato di ordinamento in cui, ogni sottoalbero a sinistra di una chiave ha chiavi di ricerca strettamente inferiori alla chiave k, e ogni sottoalbero di destra ha chiavi strettamente superiori a k
Per chiave intendiamo “chiave di ricerca”, non chiave relazionale • E’ un attributo qualsiasi su cui si effettua una ricerca
Caratterizzeremo il B-albero con un parametro m che è il massimo numero di figli di un nodo (branching factor). Abbiamo quindi:
- : massimo numero di chiavi di un nodo
- : minimo numero di chiavi presenti in un nodo interno
- Se è il numero di chiavi presenti in un nodo, allora
- Nella radice:
- Nei nodi interni:
- Se un nodo non foglia ha chiavi deve avere figli
- Le foglie devono essere tutte sullo stesso livello
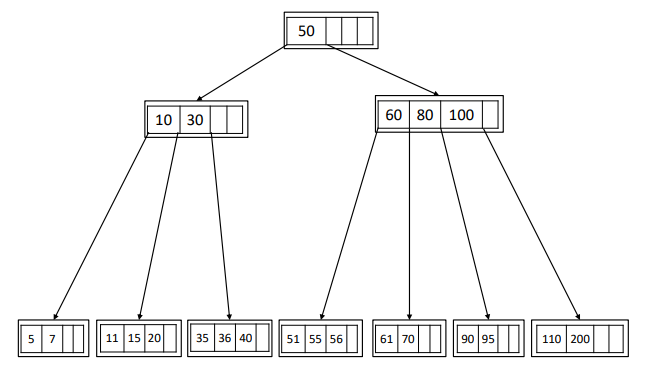
Il B-albero è un albero di ricerca, cioè data una qualsiasi chiave di ricerca all’interno di un nodo, tutte le chiavi del sottoalbero di sinistra sono minori della chiave di separazione, tutte le chiavi del sottoalbero di destra sono maggiori della chiave separatrice
Algoritmo di ricerca
- Per cercare 15 devo entrare nella radice, confronto la chiave di ricerca con le chiavi della radice (15 < 50) e scendo nel sottoalbero di sinistra
- Confronto la chiave di ricerca con le chiavi del nodo e scopro che (10 < 15 < 30) quindi entro nel secondo sottoalbero
- Dopo un certo numero di passi (numero di livelli del B-Albero) arriverò ad una foglia
Analisi quantitativa
Il dato quantitativo importante per i DBMS è il numero di livelli (nell’esempio 3) Come si fa a stimare il numero di livelli del B-albero? Il numero di livelli può essere stimato da un range molto stretto (con una tolleranza di ±1)
Il numero di livelli può essere stimato nel range:
dove è il numero di chiavi. Quindi si può dire che il numero di livelli è circa .
Considerazione su L: Consideriamo m=100 e 3 livelli (L=3), N diventa 1 milione. Questo significa che nella tecnologia attuale, con il dimensionamento standard della pagine, con soli tre livelli possiamo indicizzare un milione di chiavi (con nodi totalmente carichi) Nei sistemi DBMS, con le tecniche di bilanciamento gli indici reggono bene un carico del 70% della capacità massima (con 3 livelli si reggono bene 700mila chiavi) Per accedere ad un valore, al più movimento 3 pagine!
Proprietà dei B-alberi
Una proprietà di tutti gli alberi di ricerca è che le chiavi interne sono chiavi separatrici di due insiemi di chiavi: Questo significa che la sequenza k1 ,k,k2 è una successione di chiavi logicamente contigue
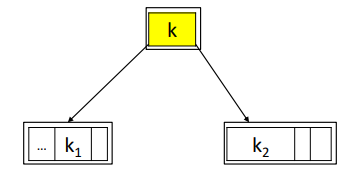
B+alberi
Si sceglie di compiere la seguente trasformazione:
- parto dalla foglia più a sinistra
- copio la chiave separatrice (che trovo risalendo l’albero) dentro la foglia di sinistra
- Copio la chiave k nel sottoalbero di sinistra
Questa scelta non altera le proprietà del B-Albero L’unico cambiamento riguarda le foglie che nel B+Albero contengono una chiave in più Ogni chiave dei nodi interni è ricopiata in una foglia
Cosa c’entra con l’area primaria?
L’area primaria è l’elenco delle pagine della tabella. Immaginiamo che i numeri riportati siano le matricole degli studenti: con il B+Albero abbiamo tutte le chiavi di ricerca nelle foglie. L’indice viene arricchito dai RID abbinati a ciascuna chiave Esempio: per la chiave 35 avrò il RID che punta al record nell’area primaria corrispondente allo studente con matricola 35 Le foglie dell’indice contengono i data entry k*, cioè l’informazione abbinata alla chiave di ricerca della locazione della tupla cercata: sono coppie <k, RID>
Infine le foglie sono tutte linkate tra di loro
Dal punto di vista strutturale, nodi interni e foglie sono simili: un nodo interno ha j chiavi e j+1 link (PID) ai figli Una foglia ha j chiavi e j puntatori (RID) ai record nell’area primaria più un puntatore (PID) alla foglia contigua (quindi j+1 link in tutto)
Immaginiamo questa selezione
Il DBMS sa che c’è l’indice sul campo MATR, prende il valore (56) e lo confronta con la radice, dato che 56 > 50 scende nel sottoalbero di destra (56 < 60) e successivamente nel sottoalbero di sinistra Trova il valore nella foglia e utilizza il RID per accedere al record: In tutto sono stati necessari L + 1 accessi a pagine
Nei sistemi informativi reali, con centinaia di migliaia di chiavi di ricerca, in genere gli indici hanno 2/3 livelli
Immaginiamo quest’altra selezione
La strategia è la seguente:
- Si parte dal valore minimo, la ricerca di 53 viene effettuata come nel caso di ricerca puntuale
- Non trovo 53 ma trovo 55 che è il primo valore utile maggiore di 53
- Basta scandire sequenzialmente le foglie sino a che non si raggiunge la foglia che può contenere il valore massimo (61) sfruttando i link alle foglie contigue
Ricerca di range di valori:
- Si parte dalla radice e si raggiunge il valore minimo
- Da quel punto in poi si scandiscono sequenzialmente le foglie fino a quella che potenzialmente contiene il valore massimo
- Tramite i RID si risale alle tuple di interesse nell’area primaria
Perché gli indici?
- L’indice è una struttura separata rispetto all’area primaria
- Posso costruire diversi indici sulla stessa area primaria: – Indice su matricola – Indice su città – Indici su più attributi (ad esempio coppie)
- Un DB administrator crea un indice quando il carico di lavoro in termini di interrogazioni è tale per cui il costo di accesso all’indice riduce notevolmente i tempi di risposta rispetto alla scansione sequenziale
Indici su tutto?
- È vero che l’indice sveltisce molto le interrogazioni, ma appesantisce le modifiche – Le inserzioni/cancellazioni modificano gli indici – Le modifiche ai valori possono modificare gli indici
- Non ha senso, ad esempio, definire indici su attributi molto movimentati dagli update
Caratterizzazione degli indici:
- Indice primario: indice definito sullo stesso attributo chiave su cui sono ordinati fisicamente i record
- Indice clusterizzato: indice su un attributo non chiave (possibili valori ripetuti) su cui i record sono ordinati fisicamente
- Indici secondari: indici su un attributo qualunque su cui i record non sono ordinati fisicamente
- In una tabella c’è al più un indice primario o clusterizzato (ma non entrambi) e zero o più indici secondari
Data entry:
- Un indice clusterizzato può essere fuso con l’area primaria, ovvero l’organizzazione dell’area primaria è effettuata come un B+Albero
- Alcune pagine conterranno delle indicizzazioni, altre pagine conterranno le tuple
- Le foglie del B+Albero diventano le pagine dati vere e proprie
- L’indice può essere definito, ovviamente, solo su un attributo
- In questo caso il costo di accesso è esattamente L
Tipi diversi di data entry <k,*>:
- <k, tupla>: il data entry è la tupla stessa (caso tipico dell’indice clusterizzato)
- <k, RID>: il data entry è puntatore al record nell’area primaria (caso tipico dell’indice primario)
- <k, lista_di_RID>: il data entry è una lista di puntatori a record che condividono la stessa chiave k (caso tipico negli indici secondari)
Quando definire gli indici? Consideriamo un esempio
- STUDENTI(MATR,Nome,DataNascita,Genere,Indirizzo)
- ESAMI(MATR,Corso,Voto,DataEsame) Ricordiamo che, se è vero che un indice favorisce le interrogazioni, ha comunque un costo di mantenimento per le inserzioni, cancellazioni e update Esistono delle euristiche generali per capire se conviene o meno definire un indice
Euristiche/consigli:
- Evitare gli indici su tabelle di poche pagine: Una tabella relazionale di poche pagine (~10 pagine) non ha esigenza di indici, perché le memorie sono tali per cui queste tabelle possono essere caricate interamente nei buffer
- Evitare indici su attributi volatili (ad esempio, Saldo del conto corrente)
- Evitare indici su chiavi poco selettive: Il fattore di selettività dell’indice è dato dal rapporto:
L’euristica suggerisce di definire un indice su se
Esempio:
- STUDENTI(MATR,Nome,DataNascita,Genere,Indirizzo)
- ESAMI(MATR,Corso,Voto,DataEsame) Un indice sulla chiave MATR ha un’altissima selettività quindi va bene. Può aver senso mettere un indice sulle date di nascita. Non ha nessun senso mettere un indice sul genere (solo due valori possibili): il DBMS non userà mai l’indice sul genere
- Evitare indici su chiavi con valori sbilanciati: Bisogna fare attenzione alla distribuzione dei valori
- Se c’è un grosso squilibrio nella distribuzione dei valori di una chiave gli indici su quella chiave saranno poco efficienti
- Ricordiamo infatti che l’ipotesi su cui si basano gli indici è quella della distribuzione uniforme
- Limitare il numero di indici: Quanti indici definire?
- Non ci sono indicazioni di carattere generale
- Gli indici selettivi favoriscono le interrogazioni ma la loro manutenzione costa
- Un’indicazione di massima è di limitarsi al massimo a 4/5 indici per relazioni corpose
- Definire indici su chiavi relazionali ed esterne: Un indice su una chiave è sempre consigliato Analogamente si consiglia di definire indici su chiavi esterne, perché spesso ci sarà bisogno del join. Esempio: In ESAMI, Matr non è chiave relazionale (la chiave è MATR, Corso) ma si consiglia ugualmente di definire un indice
- Gli indici velocizzano le scansioni ordinate:
- Quando consideriamo le foglie del B+Albero, i valori delle chiavi sono sempre ordinati per definizione
- Di conseguenza, se si vuole esplorare l’area dati secondo l’ordine della chiave indicizzata k è sufficiente eseguire una scansione sequenziale delle foglie
- L’indice ha anche come impiego il reperimento delle tuple dell’area primaria secondo l’ordine della chiave indicizzata
- Conoscere a fondo il DBMS:
- Si raccomanda di scegliere gli indici conoscendo a fondo le strategie di ottimizzazione del DBMS
- È l’ottimizzatore del DBMS a scegliere se utilizzare o meno l’indice e ogni DBMS ha la sua strategia
Ottimizzatore fisico:
- Ottimizzazione delle interrogazioni per selezione
- Ottimizzazione dei join
L’ottimizzatore ha due fasi
- L’ottimizzatore logico lavora sull’albero di parsificazione
- L’ottimizzatore fisico considera l’albero prodotto dall’ottimizzazione logica e scegliere gli algoritmi da abbinare ai nodi operativi Esistono più algoritmi per ogni tipo di nodo operativo
Ottimizzazione delle selezioni
Per semplicità trascuriamo la presenza di OR nel predicato di selezione. Consideriamo la seguente selezione:
Esempio: STUDENTI(MATR*,Nome*,DataNascita*,Genere,Indirizzo) (dove * = attributi con indice)
Alcuni predicati sono risolubili con l’indice (Nome=‘Piero’ e DataNascita>‘1990’), altri no (Indirizzo=‘TO’)
indichiamo: : componente non risolubile (non esiste nessun indice che aiuti a risolvere il predicato) p1 …ph : predicati risolubili (su attributi con indice)
Prima strategia: Alcuni DBMS utilizzano tutti gli indici disponibili, ovvero sfruttano gli indici per ottenere gli insiemi di RID
Successivamente calcolano l’intersezione degli insiemi di RID:
L’insieme di RID viene portato in memoria centrale e filtrato in base al predicato Il costo della prima strategia è dato dal costo di accesso agli indici, mentre il costo di accesso al predicato viene ignorato, in quanto applicato su record già presenti in memoria centrale
Seconda strategia: Altri DBMS invece usano una strategia diversa:
- Considerano l’ipotesi di scansione sequenziale che costa Npage(T)
- Degli indici a disposizione scelgono quello che conviene di più, trascurando gli altri
- Calcolano quindi i costi di accesso Cp1, Cp2,…, Cph
- L’ottimizzatore sceglie la tecnica di accesso con l’indice più selettivo
- Tutte le altre condizioni vengono verificate in memoria centrale
Prestazioni a confronto:
- Alcuni benchmark mostrano che i DBMS che usano un solo indice hanno un’efficienza confrontabile con quella dei DBMS che usano tutti gli indici
- Questi ultimi hanno degli overhead maggiori dovuti all’elaborazione delle liste di RID
- In ogni caso, se il costo dell’accesso sequenziale è minore del costo con indici, gli indici non vengono usati da nessuna delle due strategie
- Se un indice non viene mai usato da un DBMS, ci sono solo costi di mantenimento senza benefici
L’operatore di join è il più critico in tutti i DBMS, perché comporta confronti tra tuple di due tavole. Esistono diverse classi di algoritmi di join:
- Il DBMS sceglie l’opportuno algoritmo di join in base alla presenza di indici, alla possibilità di caricare un operando in memoria centrale, al tipo di join e all’eventuale richiesta di avere un risultato ordinato.
- Per questi motivi, un programmatore deve delegare al DBMS l’esecuzione del join e non «simularlo» con loop annidati all’interno di un programma.
L’ottimizzatore fisico considera ovviamente anche altri operatori: • Unione e differenza insiemistica • Proiezioni • Richieste di ordinamento (order by) • Presenza del distinct
Gestione della concorrenza
Prendiamo in considerazione queste due transazioni e :
read(A) |
write(A) |
read(B) |
write(B) |
read(A) |
write(A) |
read(B) |
write(B) |
Immaginiamo che tutti i vincoli di integrità della base di dati su cui agiscono e siano rispettati.
Si vede immediatamente che le due transazioni non modificano la somma dei valori di A e B.
Supponiamo ora che le due transazioni entrino in parallelo nel sistema e vengano eseguite in successione e che all’inizio A contenga il valore 1000 e B il valore 2000:
- Esecuzione :
- La prima transazione toglie da A il valore 50 e lo aggiunge a B, quindi alla fine avremo
- A = 950, B = 2050 e A + B = 3000
- La seconda transazione toglie il 10% da A e lo aggiunge a B
- A = 855, B = 2145 con A + B = 3000
- La prima transazione toglie da A il valore 50 e lo aggiunge a B, quindi alla fine avremo
- Esecuzione :
- La seconda transazione toglie il 10% da A e lo aggiunge a B
- A = 900, B = 2100 con A + B = 3000
- La prima transazione toglie da A il valore 50 e lo aggiunge a B, quindi alla fine avremo
- A = 850, B = 2150 con A + B = 3000
- La seconda transazione toglie il 10% da A e lo aggiunge a B
Supponiamo che il DBMS riceva contemporaneamente le transazioni T1 e T2: le transazioni T1 e T2 devono godere della proprietà di isolamento. Dal punto di vista del DBMS, l’esecuzione completa di T1 (isolata) seguita dall’esecuzione completa di T2 (sempre isolata) ha la proprietà di lasciare la base di dati in una situazione di consistenza. Se le riceve contemporaneamente, dal punto di vista del DBMS la scelta di eseguire la sequenza T1T2 oppure T2T1 è irrilevante
Se per il sistema informativo è importante l’ordine di esecuzione delle due transazioni, è suo compito mandarle al DBMS nell’ordine corretto. Se però il sistema informativo manda le due transazioni in parallelo al DBMS, allora il DBMS può eseguirle nell’ordine che vuole
L’esecuzione in sequenza delle transazioni è inefficiente: come sappiamo, gli accessi alla periferica sono molto costosi in termini di tempo. Dal punto di vista del DBMS una esecuzione in sequenza lascia tempi morti di elaborazione molto lunghi per via dei frequenti accessi alle periferiche (read e write). Tutti i DBMS sono stati sviluppati in modo da mandare avanti in parallelo operazioni provenienti da transazioni diverse
Problema: l’esecuzione in parallelo di due transazioni non è scontata. L’esecuzione in parallelo delle due transazioni, infatti, richiede di interfogliare le attività delle transazioni (interfogliamento: traduzione italiana del termine più noto interleaving).
Supponiamo che il DBMS esegua il seguente interfogliamento :
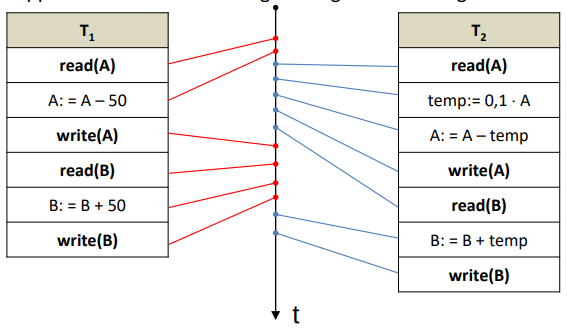
Otteniamo A = 1000, B = 2000, A + B = 3000: l’inconsistenza è dovuta al fatto che l’interfogliamento ha interferito con le due transazioni. Non è detto che l’interfogliamento di due transazioni sia sempre nocivo, ma può lasciare la base di dati in uno stato consistente.
Supponiamo che il DBMS esegua il seguente interfogliamento :
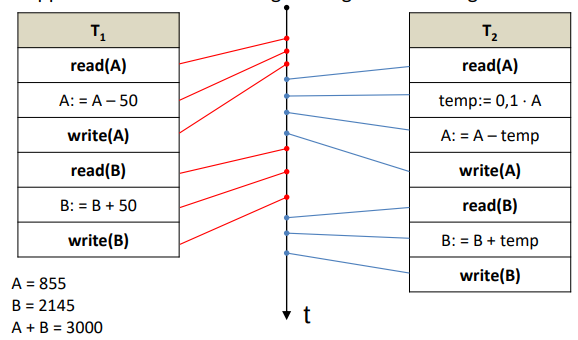
Questo interfogliamento è equivalente all’esecuzione della sequenza T1 T2
L’esecuzione interfogliata delle transazione si chiama schedulazione o storia.Una storia è la sequenza di azioni eseguite dal DBMS a fronte delle richieste da parte delle transazioni.
Consideriamo le transazioni e : Il DBMS non vede gli aggiornamenti eseguiti all’interno delle transazioni, ma vede solo gli ordini di lettura e scrittura. Descriveremo le storie T1T2 e T2T1 con questa notazione, denotando appunto solo le operazioni di lettura () o scrittura ():
Consideriamo ora le storie delle transazioni interfogliate
Definizione di view-equivalenza: Due storie ed si dicono view-equivalenti () se sono soddisfatte le seguenti condizioni:
- S ed S’ sono storie definite sullo stesso insieme di azioni (stesse azioni di read e write su stessi dati con gli stessi indici)
- Condizioni sugli input
- Se in S avviene una senza che sia stato modificato, anche in S’ deve avvenire lo stesso
- Se in una storia S una transazione scrive l’oggetto X e successivamente la transazione legge X, anche nella storia S’ deve succedere la stessa cosa:
- Condizione sullo stato: se in S una scrive per ultima l’oggetto X, anche in S’ deve scrivere per ultima l’oggetto X
Criterio di serializzabilità: Se partiamo da storie corrette (le diverse esecuzioni seriali) e abbiamo una storia interfogliata, possiamo concludere che la storia interfogliata è corretta se è view-equivalente ad una qualsiasi storia seriale
Il criterio di serializzabilità dice quindi che una storia S è corretta se è view-equivalente ad una storia seriale qualsiasi delle transazioni coinvolte da S
N.B.: date n transazioni esistono n! storie seriali
Esistono diversi metodi di gestione della concorrenza, ma si possono tutti dividere in due grosse categorie:
- Metodi ottimistici
- Metodi pessimistici
Metodi ottimistici di gestione della concorrenza
Sono metodi che lanciano le azioni delle transazioni a mano a mano che le azioni vengono richieste senza particolari controlli. Quando la transazione giunge al commit il DBMS fa un controllo per verificare che la storia è serializzabile, se non lo è forza un rollback. Sono detti ottimistici perché partono dall’assunto che le transazioni non generano conflitti nelle storie
Metodi pessimistici di gestione della concorrenza
Partono dall’assunto che ogni transazione può produrre delle storie non serializzabili I metodi non ottimistici prevengono la non serializzabilità della storia Presenteremo il metodo basato sui lock perché è il più diffuso nei DBMS
Metodo pessimistico del lock
Il DBMS mette a disposizione delle transazioni i seguenti comandi che permettono di chiedere delle autorizzazioni a compiere azioni su oggetti:
- : lock shared sull’oggetto X
- : lock exclusive sull’oggetto X
- : unlock sull’oggetto X
Possiamo assimilare l’oggetto X ad una tupla
Lock shared
Quando una transazione Ti vuole eseguire un’azione , prima di effettuare la lettura deve aver acquisito almeno il lock shared sull’oggetto X, ovvero il permesso per leggere l’oggetto X.
Il lock shared (condiviso) si chiama così perché transazioni diverse possono acquisire il lock shared sul medesimo oggetto.
Il lock shared può essere quindi concesso dal DBMS a più transazioni Esempio: la transazione può chiedere e ottenere il LS sull’oggetto X già ottenuto dalla transazione
Lock exclusive
Il lock exclusive richiede un accesso esclusivo all’oggetto X da parte di una transazione Ti
La richiesta di lock exclusive è di norma fatta da una transazione per modificare un oggetto X: questa autorizzazione deve sempre precedere una
Quando Ti ha acquisito l’autorizzazione esclusiva a scrivere l’oggetto X, nessun’altra transazione può acquisire lock sullo stesso oggetto (né né ) cioè, la transazione Ti diventa proprietaria esclusiva di X
Gestione del lock
Transazioni diverse possono lanciare attività parallele su medesimi oggetti. Come viene amministrata dal DBMS la compresenza di più lock? Il DBMS si avvale della tabella di compatibilità
| Possesso / richiesta | ||
|---|---|---|
| concede | nega | |
| nega | nega |
Ad esempio, se possiede il lock sull’oggetto X e ne fa richiesta, il DBMS concede o nega il lock a seconda dei casi elencati nella tabella di compatibilità.
Quando il DBMS non può concedere il lock, la transazione richiedente va in wait (stato di attesa). Quando una transazione non ha più bisogno di leggere/scrivere l’oggetto X, può rilasciare il lock (shared o exclusive) attraverso l’unlock. Per governare queste situazioni, il DBMS mantiene una tabella dei lock
Ecco un esempio con le transazioni da 1 a 4 e gli oggetti :
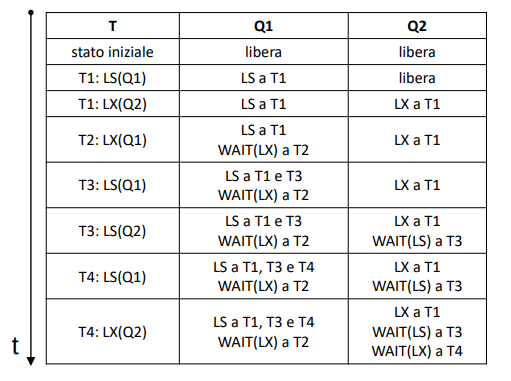
La situazione si sblocca quando la transazione T1 termina o rilascia l’oggetto (unlock). Le code delle transazioni in attesa vengono gestite con politiche FIFO
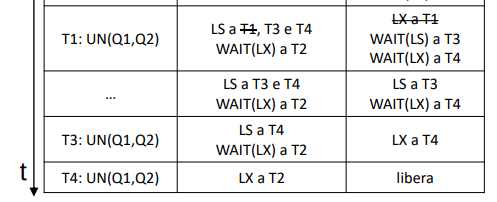
ATTENZIONE: E’ possibile aggiornare il lock da LS ad LX se una stessa transazione ne fa richiesta ed è l’unica che possiede il LS!
Politica del locking a due fasi
Se si impone alle transazioni un vincolo nell’utilizzo degli unlock, allora la politica dei lock diventa la soluzione nella gestione della concorrenza
Il vincolo è stabilito dalla politica di lock delle transazioni a due fasi detta anche two-phase lock (2PL)
Possiamo vedere il funzionamento in un grafico (X,Y) in cui nell’asse delle X abbiamo il tempo e nell’asse delle Y abbiamo il numero di lock concessi dal DBMS ad una transazione T
Ad un certo punto la transazione incomincia a rilasciare dei lock: quando una transazione inizia la fase di rilascio, da quel momento in poi non può più acquisirne
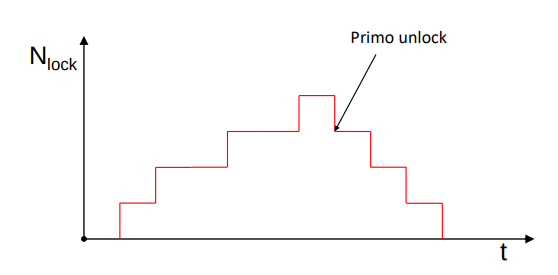
La politica si chiama “a due fasi” perché c’è una fase di acquisizione dei lock seguita da una fase di rilascio dei lock
Si può dimostrare che la politica del lock a due fasi garantisce la serializzabilità delle storie che genera
Granularità del lock
Abbiamo parlato in generale di lock di oggetti X, ma i DBMS possono avere diverse scelte:
- X può essere una tupla (soluzione più diffusa)
- X può essere un attributo (lock complessi da gestire, ma aumentano il parallelismo)
- X può essere una pagina (usati nei sistemi distribuiti: i lock diminuiscono il parallelismo, ma sono molto più facili da gestire)
- X può essere un intero file (lock usati di solito nella gestione degli indici)
Gestione del ripristino
Il gestore del ripristino affronta il problema dell’affidabilità. Il sistema deve garantire i dati a fronte di possibili guasti e anomalie:
- Guasti hardware dell’unità centrale
- Crash di sistemi
- Errori di programma
- Errori locali e condizioni di eccezione
- Rollback di transazioni forzate dal gestore della transazione e dal serializzatore
- Guasti delle periferiche di storage (Il gestore del ripristino è l’unità operativa che garantisce atomicità e consistenza e gestisce l’affidabilità a fronte di errori tranne in questi casi)
- Eventi catastrofici (Il gestore del ripristino gestisce l’affidabilità a fronte di errori tranne in questi casi)
Memoria stabile: Abbiamo distinto la memoria delle periferiche di storage in memoria standard (dove si collocano DB e indici) e memoria stabile. La memoria stabile fa da supporto al gestore del ripristino memorizzando alcune informazioni supplementari a quelle contenute alla base dati stessa. Questi record supplementari sono chiamati log, registri o giornali (file strettamente sequenziali, aggiornati attraverso scritture append)
- C’è la necessità di una robustezza maggiore per la memoria stabile rispetto alla memoria standard
- Il concetto di memoria stabile è però teorico, in quanto non esiste memoria esente da guasto
- Si può realizzare concretamente la memoria stabile approssimando la proprietà di robustezza con la metodica della duplicazione
- Il file di log è duplicato più volte, anche in luoghi geograficamente lontani
- Per rendere efficiente la gestione della memoria stabile, le informazioni da memorizzare nei log devono essere di dimensioni contenute
File di log: Il file di log è un file di tipo sequenziale con record registrati durante l’esecuzione delle transazioni
- <, start>: inizio della transazione
- : ogni volta che la transazione modifica un dato, si registra l’identificativo della transazione , l’oggetto (per esempio, la tupla) modificato, lo stato di prima della modifica (, before state) e dopo la modifica (, after state)
Le quadruple così generate entrano nel file di log nell’ordine con cui vengono prodotte le modifiche nel corso dell’elaborazione, ordine che riflette la storia delle azioni delle varie transazioni Il log è quindi una storia serializzabile corretta di modifiche della base di dati
Possiamo immaginare due situazioni:
- Transazione fallita (rollback deciso dalla transazione stessa, dal serializzatore…): si avrà quindi, nella storia, un’azione detta che disfa tutte le azioni precedentemente compiute dalla transazione , e nel log verrà memorizzato il record seguito dalla direttiva FORCE LOG
- La gestione del log avviene come per tutti gli altri dati attraverso il buffer
- La FORCE LOG richiede al gestore del ripristino un’attività di forzatura della scrittura in memoria stabile di tutte le pagine del log presenti nel buffer, al fine di garantire la coerenza della sequenza storica
- Transazione parzialmente terminata (commit): il gestore delle transazione esegue la verifica dei vincoli di integrità:
- Se un vincolo non è soddisfatto, la transazione viene abortita e si eseguono le operazioni previste per il log
- Se i vincoli sono soddisfatti, per evitare la perdita delle modifiche, si crea il record e si esegue un FORCE LOG (trasferimento in memoria stabile di tutte i record del log presenti nel buffer, fino al commit incluso)
Ripristino: Quando cade il sistema e si riprende l’attività, alcune transazioni LA = {Ti…Th} possono trovarsi in uno stadio di elaborazione non terminato (transazioni attive), altre transazioni LC = {Tj…Tk} invece possono risultare terminate (transazioni committed) In prima approssimazione, il ripristino in seguito ad un crash, avviene con due operazioni:
- : disfacimento delle transazioni non terminate per garantire la proprietà di atomicità
- : rifacimento delle transazioni in commit, a causa delle modifiche potenzialmente perse per via della politica no flush
Esempio di file di log:
<T1, START>
<T2, START>
<T2, A, BS(A), AS(A)>
<T2, COMMIT>
<T1, A, BS(A), AS(A)>
<T3,START>
<T1,COMMIT>
<T3, A, BS(A), AS(A)>
File di log presente in memoria stabile Il sistema va in crash dopo l’ultima operazione registrata nel log Vediamo come ricostruire lo stato corretto del DB
Ipotizziamo che T2 sia la prima transazione che modifica l’oggetto A La transazione T2 va in commit, ma se c’è commit nel file di log significa che le azioni di quella transazione le ritrovo interamente nel file di log Quando T1 acquisisce il lock su A, sicuramente il suo BS(A) sarà uguale all’AS(A) di T2 La transazione T3 entra nel sistema, poi la T1 va in commit e la T3 modifica l’oggetto A, ma non riesce ad andare in commit a causa del crash
Si esplora il file di log in avanti. Per ogni bisogna rendere persistente , cioè:
- Leggere la pagina che contiene X
- Modificare nel buffer la pagina
- FORCE della pagina Questo è quel che fa il REDO().
Dato che non sappiamo se le modifiche fatte nel buffer sono state trasferite nella memoria permanente, occorre fare il REDO delle transazioni andate in commit, nel nostro esempio: REDO(T2,T1)
Bisogna esplorare il log in avanti perché il rifacimento deve lasciare sulla base dati l’ultima modifica Il log dice che l’esecuzione seriale della transazione è stata T2 e poi T1 Il REDO rispetta esattamente quest’ordine se il file di log viene letto in avanti
Con l’UNDO(), al contrario, si esplora il file di log a ritroso: Per ogni bisogna ripristinare , cioè:
- Leggere la pagina che contiene X
- Modificare nel buffer la pagina
- FORCE della pagina Questo è quel che fa l’UNDO().
Leggendo a ritroso il file di log si può ricostruire sulla periferica di storage lo stato iniziale della base di dati precedente alle modifiche delle transazioni non andate a buon fine, nel nostro esempio: UNDO(T3)
Nel ripristino le transazioni in abort vengono ignorate: se c’è un abort, come visto in precedenza l’UNDO è già stato fatto, ma l’UNDO agisce sulla periferica grazie alla chiamata alla primitiva FORCE
Ciclo operativo del sistema e log:
- Nei sistemi informativi reali, c’è un momento in cui il file di log è vuoto, la base di dati si considera corretta, ed inizia un ciclo di vita dell’attività transazionale
- Il ciclo di vita dura circa 24 ore
- Quando l’attività è minima (intorno alla mezzanotte) si interrompe l’attività, si rendono persistenti tutte le modifiche delle transazioni committate, si disfano le altre e si azzera il file di log
Ripristino problematico:
- Nei grossi sistemi informativi, in un ciclo di vita il file di log può contenere anche centinaia di migliaia di record
- Se c’è una crash di sistema nel pomeriggio, quando il file di log contiene già migliaia e migliaia di tuple, il ripristino diventa estremamente costoso
- Anche se i crash non sono frequenti, possono avvenire in qualsiasi momento, anche in pieno orario di attività e bisogna ridurre al minimo i tempi necessari al ripristino
- Il ripristino richiede il blocco dell’attività transazionale, comportando, ad esempio, il blocco di tutti gli sportelli del bancomat
La soluzione al problema consiste nell’introduzione, nel file di log, di un passo detto checkpoint: Periodicamente avviene un processo di checkpoint che aggiunge un record al file di log
- Il checkpoint sospende tutte le transazioni
- Viene costruito il record di checkpoint contenete l’elenco delle transazioni che in quel momento sono attive col relativo puntatore alla posizione dello start di ognuna nel file di log
- Si esegue un FORCE LOG
- Si esegue un FORCE delle pagine delle transazioni in commit
- Viene aggiunto un flag di OK nel record di checkpoint e si esegue un nuovo FORCE LOG
- Vengono riavviate le transazioni sospese
Record di checkpoint: esempio
<T1, START>
<T2, START>
<T2, A, BF(A), AS(A)>
<T2, COMMIT>
<T1, A, BF(A), AS(A)>
<T3, START>
- Checkpoint: T1, riga 1; T3, riga 6; OK
<T1, COMMIT>
<T4, START>
<T5, START>
<T4, A, BS(A), AS(A)>
<T4, COMMIT>
<T3, A, BS(A), AS(A)>
<T5, B, BS(B), AS(B)>
- T1 e T3 sono transazioni iniziate ma non terminate, quindi vengono aggiunte alla lista di checkpoint con i relativi puntatori (in questo caso indicano le righe)
- T2 è iniziata e terminata, quindi non viene aggiunta al record
- Il record è reso persistente con una FORCE LOG
- Le modifiche di T2 vengono rese persistenti con un FORCE pagine
- Si aggiunge il flag OK
- Si esegue un nuovo FORCE LOG
Periodicità del checkpoint: il tempo che intercorre tra un checkpoint ed un altro varia in base alle tecnologie, attualmente 10/15 minuti
Ripristino con checkpoint:
- Il ripristino cerca l’ultimo checkpoint
- L’ultimo checkpoint dà l’elenco delle transazioni attive in quel momento (T1 e T3)
- Le transazioni che hanno raggiunto il commit prima del checkpoint (T2) sono già sistemate Ci possono essere:
- Transazioni iniziate prima del checkpoint e committate dopo il checkpoint (T1)
- Transazioni iniziate dopo il checkpoint e committate prima del crash (T4)
- Transazioni iniziate prima del checkpoint e non terminate (T3)
- Transazioni iniziate dopo il checkpoint e non terminate (T5)
Il gestore del ripristino recupera:
- La lista LC delle transazioni che hanno raggiunto il commit dopo l’ultimo checkpoint e (LC = {T1, T4})
- la lista LA delle transazioni ancora attive durante il crash (LA = {T3, T5}) A questo punto avviene il ripristino che prevede sempre prima l’UNDO(LA) e poi il REDO(LC)
I guasti fin qui presentati riguardano la memoria centrale. C’è poi il problema dei guasti di periferiche di storage. Abbiamo periferiche destinate a mantenere la persistenza dei dati ed altre che devono mantenere la persistenza dei log e dei dump Queste ultime sono in memoria stabile, i dati sono quindi duplicati (esempio tecniche RAID)
Tecnica di dump restore:
- La base dati viene copiata (dump) periodicamente su memoria stabile (ad esempio nastri) e il log è vuoto
- Le transazioni modificano lo stato della base dati e scrivono il file di log con relativi after state
- Se avviene un guasto alla periferica che contiene la base di dati, il recupero avviene in due passi:
- Copia del dump sulla nuova periferica (restore)
- Si legge tutto il log e si effettua il REDO(LC)