In un sistema dotato di un singolo core di elaborazione si può eseguire al massimo un processo alla volta; gli altri processi, se ci sono, devono attendere che la cpu sia libera e possa essere nuovamente sottoposta a scheduling. L’obiettivo della multiprogrammazione è avere sempre un processo in esecuzione, in modo da massimizzare l’utilizzazione della cpu. L’idea è relativamente semplice. Un processo è in esecuzione finché non deve attendere un evento, generalmente il completamento di qualche richiesta di i/o; durante l’attesa, in un sistema di calcolo semplice, la cpu resterebbe inattiva, e tutto il tempo d’attesa sarebbe sprecato. Con la multiprogrammazione si cerca d’impiegare questi tempi d’attesa in modo produttivo: si tengono contemporaneamente più processi in memoria, e quando un processo deve attendere un evento, il sistema operativo gli sottrae il controllo della cpu per cederlo a un altro processo. Su un sistema multicore questo concetto di mantenere occupata la cpu è esteso a tutti i core di elaborazione del sistema.
Lo scheduling è una funzione fondamentale dei sistemi operativi; si sottopongono a scheduling quasi tutte le risorse di un calcolatore. Naturalmente la cpu è una delle risorse principali, e il suo scheduling è alla base della progettazione dei sistemi operativi.
Definizione: schedulazione dei processi
La schedulazione dei processi è il meccanismo attraverso il quale il sistema operativo decide quale processo deve essere eseguito dalla CPU in un dato momento. In un sistema multitasking, più processi competono tra di loro per l’utilizzo della CPU ed esiste un programma specifico (detto process scheduler) il cui ruolo è quello di assegnare la CPU a questi processi in modo efficiente, garantendo che il sistema risponda correttamente alle richieste degli utenti e ottimizzi le prestazioni.
Esistono diversi tipi di schedulazione, che variano in base a quando e come viene assegnata la CPU ai processi: a lungo, a medio e a breve termine.
2.3 - Il cambio di contesto
Ora vediamo nel dettaglio cos’è il cambio di contesto e come si effettua.
Definizione: cambio di contesto
Il cambio di contesto (in inglese context switch) è l’operazione che il sistema operativo esegue per sospendere l’esecuzione di un processo attualmente in corso e passare l’esecuzione ad un altro processo.
Le fasi principali di un cambio di contesto sono:
- Salvataggio dello stato del processo corrente: il sistema operativo salva lo stato corrente del processo (o thread) in esecuzione, inclusi i valori dei registri della CPU, il valore del Program Counter che tiene traccia dell’istruzione successiva da eseguire, lo stato di un processo e le altre informazioni necessarie per riprendere l’esecuzione in futuro. Queste informazioni sono memorizzate nel PCB del processo.
- Caricamento del nuovo contesto: il sistema operativo carica il contesto del prossimo processo da eseguire dal suo corrispettivo PCB, ripristinando i suoi valori dei registri della CPU e del Program Counter, quindi la CPU riprende l’esecuzione del nuovo processo da dove era stato interrotto l’ultima volta.
- Ripresa dell’esecuzione: la CPU riprende l’esecuzione del nuovo processo dal punto in cui era stato sospeso.
Ecco un diagramma che illustra il cambio di contesto tra due processi e :
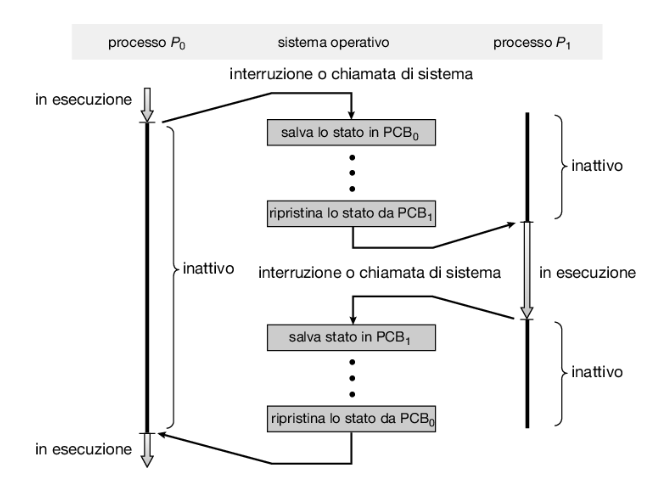
2.3.1 - Utilità e vantaggi del cambio di contesto
Il cambio di contesto serve principalmente per:
- Multitasking: dovendo gestire più processi quasi simultaneamente, la CPU esegue ogni processo per un breve intervallo di tempo e poi passa a un altro processo, servendosi proprio del cambio di contesto e garantendo che ogni processo ottenga una porzione del tempo della CPU utile alla sua esecuzione.
- Prevenzione del monopolio della CPU: in un sistema operativo multitasking, il cambio di contesto permette di sospendere temporaneamente un processo e riprendere l’esecuzione di un altro, assicurando che nessun processo monopolizzi la CPU. Questo permette a più programmi di essere eseguiti nello stesso momento senza che uno blocchi l’altro.
- Gestione dei processi bloccati: quando un processo è bloccato (cioè è nello stato
waiting, per esempio in attesa di un’operazione di I/O), il cambio di contesto consente alla CPU di passare immediatamente a un altro processo pronto per essere eseguito, ottimizzando l’utilizzo delle risorse. - Risposta a eventi esterni: il cambio di contesto può essere innescato da un interrupt (ad esempio, l’arrivo di un input da tastiera o il completamento di un’operazione di I/O) che richiede l’attenzione del sistema operativo. Quando si verifica un evento esterno, la CPU può eseguire il cambio di contesto per gestire l’evento e successivamente tornare al processo precedente.
- Supporto alla concorrenza: nei sistemi multiprocessore o multithread, il cambio di contesto consente a diversi thread o processi di essere eseguiti contemporaneamente o in sequenza sulla stessa CPU, migliorando la concorrenza tra le operazioni.
- Ottimizzazione del sistema: permette di bilanciare O-bound (che richiedono più operazioni di I/O) e processi CPU-bound (che utilizzano intensivamente la CPU), migliorando le prestazioni complessive del sistema.
2.3.2 - Costi del cambio di contesto
Il cambio di contesto è un’operazione che ha un costo in termini di tempo e risorse. Durante il tempo necessario per il cambio di contesto, nessun processo utente viene effettivamente eseguito: il cambio di contesto è puro overhead, perché il sistema esegue solo operazioni volte alla gestione dei processi e non alla computazione.
Il tempo necessario varia da sistema a sistema, dipendendo dalla velocità della memoria, dal numero di registri da copiare e dall’esistenza di istruzioni macchina appropriate (per esempio, una singola istruzione per caricare o trasferire in memoria tutti i registri). In genere si tratta di qualche millisecondo di computazione, ma la frequenza del cambio di contesto deve essere ottimizzata per evitare che un eccessivo numero di cambi riduca l’efficienza del sistema.
Ciclicità delle fasi d’elaborazione e di I/O
Il successo dello scheduling della cpu dipende dall’osservazione della seguente proprietà dei processi: l’esecuzione del processo consiste in un ciclo d’elaborazione (svolta dalla cpu) e d’attesa del completamento delle operazioni di i/o. I processi si alternano tra questi due stati. L’esecuzione di un processo comincia con una sequenza di operazioni d’elaborazione svolte dalla cpu (cpu burst), seguita da una sequenza di operazioni di i/o (i/o burst), quindi un’altra sequenza di operazioni della cpu, di nuovo una sequenza di operazioni di i/o, e così via. L’ultima sequenza di operazioni della cpu si conclude con una richiesta al sistema di terminare l’esecuzione (Figura 5.1).
Le durate delle sequenze di operazioni della cpu (dette anche “burst della cpu”) sono state misurate in molte sperimentazioni, e sebbene varino molto secondo il processo e secondo il calcolatore, la loro curva di frequenza è simile a quella illustrata nella Figura 5.2. La curva è generalmente di tipo esponenziale o iperesponenziale, con molte brevi sequenze di operazioni della cpu, e poche sequenze di operazioni della cpu molto lunghe. Un programma con prevalenza di i/o (i/o bound) produce generalmente molte sequenze di operazioni della cpu di breve durata. Un programma con prevalenza d’elaborazione (cpu bound), invece, può produrre varie sequenze di operazioni della cpu molto lunghe. Questa distribuzione può essere utile nella scelta di un appropriato algoritmo di scheduling della cpu.
Definizione: processo I/O-bound
Un processo I/O-bound è un processo che passa la maggior parte del suo tempo in attesa di operazioni di I/O, come la lettura da o la scrittura su un disco, l’attesa di dati dalla rete, o l’interazione con dispositivi come tastiere e stampanti. Il tempo di esecuzione sulla CPU è relativamente breve rispetto al tempo trascorso in attesa di I/O.
Le caratteristiche principali dei processi I/O-bound sono:
- Uso intenso di I/O: questi processi effettuano molte operazioni di input e output e, quindi, tendono a essere spesso bloccati (quindi nello stato
waiting) fino a quando le operazioni di I/O non sono completate.- Breve tempo di utilizzo della CPU: quando il processo ottiene il controllo della CPU, tende a eseguire solo un piccolo numero di calcoli prima di essere nuovamente bloccato per attendere l’I/O (ad esempio, un programma che attende frequenti input da parte dell’utente, come un editor di testo o un’applicazione interattiva, oppure un processo che trasferisce grandi quantità di dati da o verso un disco rigido).
- Obiettivo della schedulazione: i processi I/O-bound beneficiano di una schedulazione che li rimuova rapidamente dallo stato di attesa (quando l’I/O è completato) e gli assegni prontamente la CPU, per minimizzare i tempi di attesa e garantire che le operazioni di I/O siano gestite efficientemente.
Definizione: processo CPU-bound
Un processo CPU-bound è un processo che trascorre la maggior parte del suo tempo effettuando calcoli sulla CPU e richiede relativamente poche operazioni di I/O. Il tempo speso in attesa di operazioni di I/O è trascurabile rispetto al tempo di utilizzo della CPU.
Le caratteristiche principali dei processi CPU-bound sono:
- Uso intenso della CPU: Questi processi richiedono molto tempo di CPU per eseguire i loro calcoli e rimangono in esecuzione per lunghi periodi senza essere bloccati per operazioni di I/O.
- Basso utilizzo di I/O: I processi CPU-bound raramente richiedono accesso a dispositivi di input e output, quindi tendono a non essere frequentemente bloccati (es. un programma di elaborazione scientifica o di simulazione che esegue complessi calcoli matematici, oppure un software che genera immagini grafiche complesse o esegue algoritmi di compressione dati).
- Obiettivo della schedulazione: i processi CPU-bound possono richiedere quanti di tempo più lunghi, poiché tendono a utilizzare la CPU per periodi prolungati prima di completare il loro lavoro o di cedere la CPU.
Ecco una tabella riassuntiva delle differenze principali tra i due tipi di processi:
| Caratteristica | I/O-bound | CPU-bound |
|---|---|---|
| Uso principale | Predomina l’attesa per operazioni di I/O | Predomina l’uso intensivo della CPU per calcoli |
| Tempo in attesa | Passa molto tempo in attesa di I/O (stato waiting) | Passa la maggior parte del tempo eseguendo calcoli |
| Tempo sulla CPU | Utilizza la CPU solo per brevi periodi | Utilizza la CPU per lunghi periodi senza interruzioni |
| Esempi | Editor di testo, programmi di rete, trasferimenti dati | Elaborazione scientifica, rendering grafico, compressione dati |
| Schedulazione | Richiede una gestione rapida dell’I/O | Richiede tempi più lunghi di utilizzo della CPU |
Tipi di schedulazione
Definizione: schedulazione a lungo termine
La schedulazione a lungo termine è un tipo di schedulazione dei processi in cui la CPU decide quali processi devono essere prelevati dalla coda dei processi per essere spostati nella memoria principale (RAM) nella coda dei processi pronti. Il suo scopo è quello di controllare il grado di multiprogrammazione, cioè il numero di processi che possono essere mantenuti in memoria e pronti per essere eseguiti contemporaneamente.
Definizione: schedulazione a medio termine
La schedulazione a medio termine è un tipo di schedulazione dei processi responsabile del cosiddetto swapping dei processi, cioè dello spostamento temporaneo di processi in stato
waitingdalla RAM a una memoria secondaria (per esempio su disco) per liberare memoria e fare spazio ad altri processi.
Definizione: schedulazione a breve termine
La schedulazione a breve termine (o schedulazione della CPU) è un tipo di schedulazione dei processi ed è l’unica schedulazione realmente necessaria in un sistema operativo, poiché decide quale processo tra quelli nello stato
readydovrà essere eseguito dalla CPU attraverso l’uso di diversi algoritmi di schedulazione. Questo processo avviene molto frequentemente (nell’ordine dei millisecondi).Può essere effettuata anche sospendendo un processo in esecuzione, cioè nello stato
running, per sottrargli la CPU e assegnarla a un altro processo ritenuto più opportuno: in questo caso si dice che è con prelazione, altrimenti è senza prelazione.
Schedulazione con e senza prelazione
Definizione: schedulazione con e senza prelazione
La schedulazione a breve termine si dice con prelazione (in inglese preemptive) se lo scheduler può sospendere un processo in esecuzione, cioè nello stato
running, per sottrargli la CPU e assegnarla a un altro processo ritenuto più opportuno, altrimenti si dice senza prelazione (in inglese non-preemptive).In particolare, se la schedulazione a breve termine si attiva solo quando:
- un processo passa dallo stato
runningallo statowaiting(per esempio, richiesta di I/O o invocazione di wait() per la terminazione di uno dei processi figli) o- un processo termina, allora la schedulazione è senza prelazione.
Se, invece, si attiva anche:
- per forzare il passaggio di un processo dallo stato
runningallo statoready(per esempio, quando si verifica un segnale d’interruzione) o- in seguito al passaggio di un processo dallo stato
waitingallo statoready(per esempio, al completamento di un’operazione di I/O) per sottrargli la CPU, allora la schedulazione è con prelazione.
Sfortunatamente lo scheduling con prelazione può portare a race condition quando i dati sono condivisi tra diversi processi. Si consideri il caso in cui due processi condividono dati; mentre uno di questi aggiorna i dati si ha la sua prelazione in favore dell’esecuzione dell’altro. Il secondo processo può, a questo punto, tentare di leggere i dati che sono stati lasciati in uno stato incoerente dal primo processo.
La capacità di prelazione si ripercuote anche sulla progettazione del kernel del sistema operativo. Durante l’elaborazione di una chiamata di sistema, il kernel può essere impegnato in attività per conto di un processo; tali attività possono comportare la necessità di modifiche a importanti dati del kernel, come le code di i/o. Se si ha la prelazione del processo durante tali modifiche e il kernel (o un driver di dispositivo) deve leggere o modificare gli stessi dati, si può avere il caos. Come verrà discusso nel Paragrafo 6.2, i kernel dei sistemi operativi possono essere progettati con o senza prelazione. Un kernel senza prelazione attenderà che una chiamata di sistema venga completata o che un processo si blocchi in attesa di terminare l’i/o prima di eseguire un cambio di contesto. Questo schema garantisce che la struttura del kernel sia semplice, poiché il kernel non può esercitare la prelazione su un processo mentre le sue strutture dati si trovano in uno stato incoerente. Sfortunatamente, questo modello d’esecuzione non è adeguato alle elaborazioni in tempo reale, in cui i task devono essere conclusi entro un intervallo fissato di tempo. I requisiti di scheduling per sistemi real-time sono descritti nel Paragrafo 5.6. Un kernel con prelazione richiede meccanismi come i lock mutex per prevenire le race condition quando si accede a strutture dati condivise del kernel. La maggior parte dei sistemi operativi moderni è interamente con prelazione durante l’esecuzione in modalità kernel
Poiché le interruzioni si possono, per definizione, verificare in ogni istante e il kernel non può sempre ignorale, le sezioni di codice eseguite per effetto delle interruzioni devono essere protette da un uso simultaneo. Il sistema operativo deve ignorare raramente le interruzioni, altrimenti si potrebbero perdere dati in ingresso, o si potrebbero sovrascrivere dati in uscita. Per evitare che più processi accedano in modo concorrente a tali sezioni di codice, queste disattivano le interruzioni al loro inizio e le riattivano alla fine. Le sezioni di codice che disabilitano le interruzioni si verificano tuttavia raramente e, in genere, non contengono molte istruzioni.
Dispatcher
Un altro elemento coinvolto nella funzione di scheduling della cpu è il dispatcher; si tratta del modulo che passa effettivamente il controllo della cpu al processo scelto dallo scheduler a breve termine.
Definizione: dispatcher
Il dispatcher è il componente del kernel che attua concretamente la decisione presa dallo scheduler, realizzando concretamente la schedulazione a breve termine. In particolare:
- effettua i cambi di contesto trasferendo il controllo della CPU al processo selezionato,
- passa la CPU in modalità utente se il processo non è un processo di sistema e
- salta all’istruzione corretta del nuovo processo (tramite il program counter).
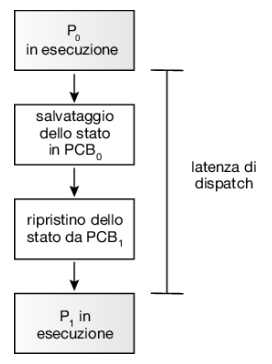
Poiché si attiva a ogni cambio di contesto, il dispatcher dovrebbe essere quanto più rapido è possibile. Il tempo richiesto dal dispatcher per fermare un processo e avviare l’esecuzione di un altro è noto come latenza di dispatch:
2.1 - Code di schedulazione
Per la gestione dei processi, il sistema operativo usa una serie di strutture dati dette code di schedulazione.
Definizione: code di schedulazione
Le code di schedulazione (in inglese scheduling queues) sono strutture di dati utilizzate dal sistema operativo per gestire i processi in diverse fasi del loro ciclo di vita, determinando quale processo deve essere eseguito, aspettare o bloccarsi, basandosi su determinati algoritmi di schedulazione.
Ogni coda generalmente viene memorizzata come una lista concatenata, con un’intestazione della coda contenente i puntatori al primo PCB della lista che a sua volta comprende un campo puntatore che indica il successivo processo contenuto nella coda e così via:
Le principali code di schedulazione sono la coda dei processi (job queue), la coda dei processi pronti (ready queue o run queue), la coda dei dispositivi (device queue) e la coda dei processi bloccati (waiting queue).
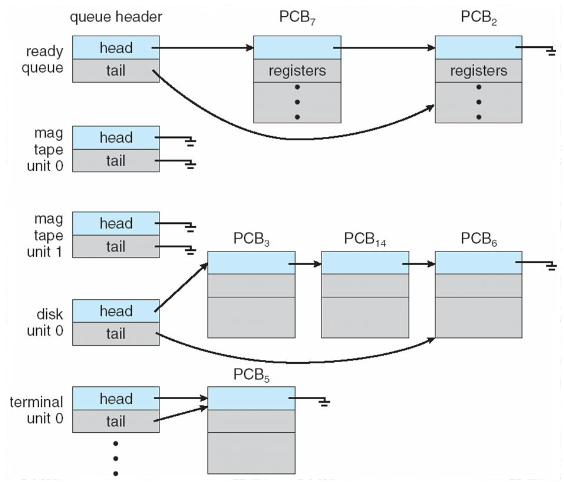
Vediamo le definizioni delle varie code di schedulazione.
Definizione: coda dei processi ( job queue)
La coda dei processi (job queue) è una coda di schedulazione che contiene tutti i processi esistenti nel sistema operativo, indipendentemente dallo stato in cui si trovano. Non appena un processo viene creato, viene aggiunto a questa coda.
Definizione: coda dei processi pronti ( ready queue o run queue)
La coda dei processi pronti (ready queue o run queue) è una coda di schedulazione che contiene tutti i processi che sono pronti per l’esecuzione (cioè nello stato
ready) e in attesa che la CPU sia disponibile. Lo schedulatore a breve termine sceglie i processi da questa coda per essere eseguiti. Questa coda è una delle più attive e importanti, poiché determina quali processi avranno accesso alla CPU.
Definizione: coda dei dispositivi ( device queue)
La coda dei dispositivi (device queue) è una coda di schedulazione propria di ogni dispositivo di I/O nel sistema operativo. Quando un processo richiede un’operazione di I/O, entra nella coda del dispositivo corrispondente e rimane bloccato finché l’operazione non viene completata. Dopo che l’I/O è completato, il processo può ritornare nella coda dei processi pronti. Per esempio, se un processo sta aspettando che venga completata la lettura da disco, sarà nella coda del disco fino al termine dell’operazione.
Definizione: coda dei dispositivi ( device queue)
La coda dei dispositivi (device queue) è una coda di schedulazione propria di ogni dispositivo di I/O nel sistema operativo. Quando un processo richiede un’operazione di I/O, entra nella coda del dispositivo corrispondente e rimane bloccato finché l’operazione non viene completata. Dopo che l’I/O è completato, il processo può ritornare nella coda dei processi pronti. Per esempio, se un processo sta aspettando che venga completata la lettura da disco, sarà nella coda del disco fino al termine dell’operazione.
Definizione: coda dei processi bloccati ( waiting queue)
La coda dei processi bloccati (waiting queue) è una coda di schedulazione che contiene processi che sono bloccati in attesa di un evento (cioè nello stato
waiting), come l’input da un dispositivo o il completamento di una richiesta di I/O. Quando l’evento atteso si verifica, il processo ritorna nella coda dei processi pronti. È simile alla coda dei dispositivi, ma può anche includere processi in attesa di altri tipi di eventi non legati ai dispositivi di I/O.
2.2 - Algoritmi di schedulazione
Definizione: algoritmo di schedulazione
Un algoritmo di schedulazione è un algoritmo che definisce le regole secondo cui il sistema operativo effettua la schedulazione a breve termine, ossia come assegna la CPU ai processi pronti all’esecuzione (cioè quelli nello stato
readyelencati nella coda dei processi pronti). È un componente fondamentale del dispatcher del kernel e influisce su tempo di risposta (responsiveness), utilizzo della CPU, throughput ed equità tra processi.
Esistono vari algoritmi di schedulazione utilizzati per determinare quale processo deve essere eseguito dalla CPU in un dato momento. I vari algoritmi di schedulazione hanno caratteristiche diverse che li rendono più adatti a determinati scenari (interattivi, in tempo reale, ecc.), e la scelta dell’algoritmo giusto dipende dai requisiti specifici del sistema.
2.2.1 - Parametri di performance della schedulazione
Alcuni criteri utilizzati per valutare le prestazioni di un algoritmo di schedulazione includono:
- Tempo di attesa: il tempo che un processo trascorre nella coda dei processi pronti prima di essere eseguito.
- Tempo di turnaround: il tempo totale che un processo impiega dal momento in cui viene creato fino a quando termina (inclusi i tempi di attesa e di esecuzione).
- Tempo di risposta: il tempo che intercorre tra la creazione di un processo e il primo istante in cui il processo inizia a essere eseguito.
- Throughput: il numero di processi completati in un dato intervallo di tempo.
Diversi algoritmi di scheduling della cpu hanno proprietà differenti e possono favorire una particolare classe di processi. Prima di scegliere l’algoritmo da usare in una specifica situazione occorre considerare le caratteristiche dei diversi algoritmi.
Per il confronto tra gli algoritmi di scheduling della cpu sono stati suggeriti molti criteri. Le caratteristiche usate per tale confronto possono incidere in modo rilevante sulla scelta dell’algoritmo migliore. Di seguito si riportano alcuni criteri.
- Utilizzo della cpu. La cpu deve essere più attiva possibile. Teoricamente, l’utilizzo della cpu può variare dallo 0 al 100 per cento. In un sistema reale dovrebbe variare dal 40 per cento, per un sistema con poco carico, al 90 per cento, per un sistema con carico elevato. (L’utilizzo della cpu può essere ottenuto utilizzando il comando top su sistemi Linux, macos e unix).
- Throughput. La cpu è attiva quando si svolge del lavoro. Una misura del lavoro svolto è data dal numero dei processi completati nell’unità di tempo: tale misura è detta produttività (throughput). Per processi di lunga durata il suo valore può essere di un processo all’ora, mentre per brevi transazioni è possibile avere un throughput di 10 processi al secondo.
- Tempo di completamento. Dal punto di vista di uno specifico processo, il criterio più importante è il tempo necessario per eseguire il processo stesso. L’intervallo che intercorre tra la sottomissione del processo e il completamento dell’esecuzione è chiamato tempo di completamento (turnaround time), ed è la somma dei tempi passati nell’attesa dell’ingresso in memoria, nella ready queue, durante l’esecuzione nella cpu e nelle operazioni di i/o.
- Tempo d’attesa. L’algoritmo di scheduling della cpu non influisce sul tempo impiegato per l’esecuzione di un processo o di un’operazione di i/o; influisce solo sul tempo d’attesa nella ready queue. Il tempo d’attesa è la somma degli intervalli d’attesa passati in questa coda.
- Tempo di risposta. In un sistema interattivo il tempo di completamento può non essere il miglior criterio di valutazione: spesso accade che un processo emetta dati abbastanza presto, e continui a calcolare i nuovi risultati mentre quelli precedenti sono in fase di output per l’utente. Quindi, un’altra misura di confronto è data dal tempo che intercorre tra la effettuazione di una richiesta e la prima risposta prodotta. Questa misura è chiamata tempo di risposta, ed è data dal tempo necessario per iniziare la risposta, ma non dal suo tempo necessario per completare l’output.
È auspicabile aumentare al massimo utilizzo e produttività della cpu, mentre il tempo di completamento, il tempo d’attesa e il tempo di risposta si devono ridurre al minimo. Nella maggior parte dei casi si ottimizzano i valori medi; tuttavia in alcune circostanze è più opportuno ottimizzare i valori minimi o massimi, anziché i valori medi; per esempio, per garantire che tutti gli utenti ottengano un buon servizio, possiamo voler ridurre il massimo tempo di risposta.
Per i sistemi interattivi, come i sistemi desktop e laptop, alcuni analisti suggeriscono che sia più importante ridurre al minimo la varianza del tempo di risposta anziché il tempo medio di risposta. Un sistema il cui tempo di risposta sia ragionevole e prevedibile può essere considerato migliore di un sistema mediamente più rapido, ma molto variabile. Tuttavia, è stato fatto poco sugli algoritmi di scheduling della cpu al fine di ridurre al minimo la varianza.
Nell’analizzare i diversi algoritmi di scheduling della cpu dobbiamo esemplificarne il funzionamento. Una descrizione approfondita richiederebbe il ricorso a molti processi, ognuno dei quali costituito da parecchie centinaia di sequenze di operazioni della cpu e di sequenze di operazioni di i/o. Per motivi di semplicità, negli esempi si considera una sola sequenza di operazioni della cpu (la cui durata è espressa in millisecondi) per ogni processo. La misura di confronto adottata è il tempo d’attesa medio. Meccanismi di valutazione più raffinati sono trattati nel Paragrafo 5.8.
First-Come, First-Served (FCFS)
Il più semplice algoritmo di scheduling della cpu è l’algoritmo di scheduling in ordine d’arrivo (scheduling first-come, first-served o fcfs). Con questo schema la cpu si assegna al processo che la richiede per primo. La realizzazione del criterio fcfs si basa su una coda fifo. Quando un processo entra nella ready queue, si collega il suo pcb all’ultimo elemento della coda. Quando la cpu è libera, viene assegnata al processo che si trova alla testa della coda, rimuovendolo da essa. Il codice per lo scheduling fcfs è semplice sia da scrivere sia da capire.
Un aspetto negativo è che il tempo medio d’attesa per l’algoritmo fcfs è spesso abbastanza lungo. Si consideri il seguente insieme di processi, che si presenta al momento 0, con la durata della sequenza di operazioni della cpu espressa in millisecondi:
| Processo | Durata della sequenza |
|---|---|
Se i processi arrivano nell’ordine e sono serviti in ordine fcfs, si ottiene il risultato illustrato nel seguente diagramma di Gantt, un diagramma a barre che illustra una data pianificazione includendo i tempi d’inizio e fine di ogni processo partecipante.

Il tempo d’attesa è 0 millisecondi per il processo P1, 24 millisecondi per il processo P2e 27 millisecondi per il processo P3. Quindi, il tempo d’attesa medio è (0 + 24 + 27)/3 = 17 millisecondi. Se i processi arrivassero nell’ordine P2, P3, P1, i risultati sarebbero quelli illustrati nel seguente diagramma di Gantt:

Il tempo di attesa medio è ora di (6 + 0 + 3)/3 = 3 millisecondi. Si tratta di una notevole riduzione. Quindi, il tempo medio d’attesa in condizioni di fcfs non è in genere minimo, e può variare grandemente all’aumentare della variabilità dei cpu burst dei vari processi.
Si considerino inoltre le prestazioni dello scheduling fcfs in una situazione dinamica. Si supponga di avere un processo con prevalenza d’elaborazione e molti processi con prevalenza di i/o. Via via che i processi fluiscono nel sistema si può verificare la seguente situazione. Il processo con prevalenza d’elaborazione occupa la cpu. Durante questo periodo tutti gli altri processi terminano le proprie operazioni di i/o e si spostano nella ready queue, nell’attesa della cpu. Mentre i processi si trovano nella ready queue, i dispositivi di i/o sono inattivi. Successivamente il processo con prevalenza d’elaborazione termina la propria sequenza di operazioni della cpu e passa a una fase di i/o. Tutti i processi con prevalenza di i/o, caratterizzati da sequenze di operazioni della cpu molto brevi, sono eseguiti rapidamente e tornano alle code di i/o, lasciando inattiva la cpu. Il processo con prevalenza d’elaborazione torna nella ready queue e riceve il controllo della cpu; così, finché non termina l’esecuzione del processo con prevalenza d’elaborazione, tutti i processi con prevalenza di i/o si trovano nuovamente ad attendere nella ready queue. Si ha un effetto convoglio, tutti i processi attendono che un lungo processo liberi la cpu, il che causa una riduzione dell’utilizzo della cpu e dei dispositivi rispetto a quella che si avrebbe se si eseguissero per primi i processi più brevi.
L’algoritmo di scheduling fcfs è senza prelazione; una volta che la cpu è assegnata a un processo, questo la trattiene fino al momento del rilascio, che può essere dovuto al termine dell’esecuzione o alla richiesta di un’operazione di i/o. L’algoritmo fcfs risulta particolarmente problematico nei sistemi in time-sharing, dove è importante che ogni utente disponga della cpu a intervalli regolari. Permettere a un solo processo di occupare la cpu per un lungo periodo condurrebbe a risultati disastrosi.
Shortest Job First
Un criterio diverso di scheduling della cpu è l’algoritmo di scheduling per brevità (shortest-job-first, sjf). Questo algoritmo associa a ogni processo la lunghezza della successiva sequenza di operazioni della cpu. Quando è disponibile, si assegna la cpu al processo che ha la più breve lunghezza della successiva sequenza di operazioni della cpu. Se due processi hanno le successive sequenze di operazioni della cpu della stessa lunghezza si applica lo scheduling fcfs. Si noti che sarebbe più appropriato il termine shortest next cpu burst, infatti lo scheduling si esegue esaminando la lunghezza della successiva sequenza di operazioni della cpu del processo e non la sua lunghezza totale. Tuttavia, poiché è comunemente usato ed è presente nella maggior parte dei libri di testo, anche qui si fa uso del termine sjf.
Come esempio si consideri il seguente insieme di processi, con la durata della sequenza di operazioni della cpu espressa in millisecondi:
| Processo | Durata della sequenza |
|---|---|
Con lo scheduling sjf questi processi si ordinerebbero secondo il seguente diagramma di Gantt.
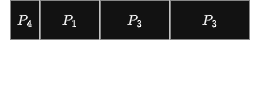
Il tempo d’attesa è di 3 millisecondi per il processo P1, di 16 millisecondi per il processo P , di 9 millisecondi per il processo P e di 0 millisecondi per il processo P . Quindi, il tempo d’attesa medio è di (3 + 16 + 9 + 0)/4 = 7 millisecondi. Usando lo scheduling fcfs, il tempo d’attesa medio sarebbe di 10,25 millisecondi.
Si può dimostrare che l’algoritmo di scheduling sjf è ottimale, nel senso che rende minimo il tempo d’attesa medio per un dato insieme di processi. Spostando un processo breve prima di un processo lungo, il tempo d’attesa per il processo breve diminuisce più di quanto aumenti il tempo d’attesa per il processo lungo. Di conseguenza, il tempo d’attesa medio diminuisce.
Predizione del CPU burst
Sebbene sia ottimale, l’algoritmo sjf non si può realizzare a livello dello scheduling della cpu a breve termine, poiché non esiste alcun modo per sapere a priori esattamente quanto ci metterà la CPU a eseguire un processo, cioè la lunghezza del CPU-burst. Un possibile approccio a questo problema consiste nel tentare di predire il suo valore; è probabile, infatti, che sia simile alle precedenti. Quindi, calcolando un valore approssimato della lunghezza, si può scegliere il processo con la più breve fra tali lunghezze previste.
La lunghezza della successiva sequenza di operazioni della cpu generalmente si stima calcolando la media esponenziale delle lunghezze misurate delle precedenti sequenze di operazioni della cpu. La media esponenziale si definisce con la formula seguente. Siano:
- : la durata stimata dell’-esimo processo
- : la durata reale dell’-esimo processo.
- : la stima della durata dell’-esimo processo;
- , con , il parametro di smorzamento, allora:
Questa formula significa che la stima della durata dell’-esimo processo è una combinazione del valore più recente osservato e della stima precedente , che incorpora tutta la storia passata. Non è una media aritmetica semplice: i pesi non sono uguali, ma regolati da , infatti:
- Se , allora e l’ultima osservazione è ignorata. L’algoritmo assume che il comportamento recente sia poco affidabile o transitorio.
- Se , allora e conta solo l’ultimo burst. Tutta la storia precedente viene scartata. In pratica, controlla il compromesso tra stabilità e reattività.
Si chiama “media esponenziale” perché espandendo ricorsivamente la formula si ottiene:
I burst più vecchi contribuiscono sempre meno, con un decadimento esponenziale.
Questo evita di dover memorizzare tutta la storia.
Prelazione
L’algoritmo sjf può essere sia con prelazione sia senza prelazione. La scelta si presenta quando alla ready queue arriva un nuovo processo mentre un altro processo è ancora in esecuzione. Il nuovo processo può richiedere una sequenza di operazioni della cpu più breve di quella che resta al processo correntemente in esecuzione. Un algoritmo sjf con prelazione sostituisce il processo attualmente in esecuzione, mentre un algoritmo sjf senza prelazione permette al processo correntemente in esecuzione di portare a termine la propria sequenza di operazioni della cpu. (Lo scheduling sjf con prelazione è talvolta chiamato scheduling shortest-remaining-time-first).
Come esempio, si considerino i quattro processi seguenti, dove la durata delle sequenze di operazioni della cpu è data in millisecondi:
| Processo | Istante d’arrivo | Durata della sequenza |
|---|---|---|
Se i processi arrivano alla ready queue nei momenti indicati e richiedono i tempi di cpu illustrati, dallo scheduling sjf con prelazione risulta la sequenza indicata dal seguente diagramma di Gantt.

Abbiamo quindi:
| Processo | Istante d’arrivo | Durata della sequenza | Completamento |
|---|---|---|---|
All’istante 0 si avvia il processo , poiché è l’unico che si trova nella coda. All’istante 1 arriva il processo . Il tempo necessario per completare il processo (7 millisecondi) è maggiore del tempo richiesto dal processo (4 millisecondi), perciò si effettua la prelazione del processo sostituendolo col processo . Il tempo d’attesa medio per questo esempio è
millisecondi. Con uno scheduling sjf senza prelazione si otterrebbe un tempo d’attesa medio di 7,75 millisecondi.
(Spiegazione formula: si sottrae dal tempo di completamento il tempo di arrivo e il tempo di durata della sequenza)
Priority Scheduling
L’algoritmo sjf è un caso particolare del più generale algoritmo di scheduling con priorità: si associa una priorità a ogni processo e si assegna la cpu al processo con priorità più alta; i processi con priorità uguali si ordinano secondo uno schema fcfs. Un algoritmo sjf è semplicemente un algoritmo con priorità in cui la priorità (p) è l’inverso della lunghezza (prevista) della successiva sequenza di operazioni della cpu. A una maggiore lunghezza corrisponde una minore priorità, e viceversa.
Occorre notare che la discussione si svolge in termini di priorità alta e priorità bassa. Generalmente le priorità sono indicate da un intervallo fisso di numeri, come da 0 a 7, oppure da 0 a 4.095. Tuttavia, non c’è un orientamento comune sull’attribuire allo 0 la priorità più alta o quella più bassa; alcuni sistemi usano numeri bassi per rappresentare priorità basse, altri usano numeri bassi per priorità alte, il che può generare confusione. In questo testo i numeri bassi indicano priorità alte. In ogni caso, la priorità viene salvata nel PCB del processo tra le informazioni della schedulazione.
Come esempio, si consideri il seguente insieme di processi, che si suppone siano arrivati al tempo 0, nell’ordine , e dove la durata delle sequenze di operazioni della cpu è espressa in millisecondi:
| Processo | Durata della sequenza | Priorità |
|---|---|---|
Usando lo scheduling con priorità, questi processi sarebbero ordinati secondo il seguente diagramma di Gantt.

Il tempo d’attesa medio è di 8,2 millisecondi.
Le priorità si possono definire sia internamente sia esternamente. Quelle definite internamente usano una o più quantità misurabili per calcolare la priorità del processo; per esempio sono stati utilizzati i limiti di tempo, i requisiti di memoria, il numero dei file aperti e il rapporto tra la lunghezza media delle sequenze di operazioni di i/o e la lunghezza media delle sequenze di operazioni della cpu. Le priorità esterne si definiscono secondo criteri esterni al sistema operativo, come l’importanza del processo, il tipo e la quantità dei fondi pagati per l’uso del calcolatore, il dipartimento che promuove il lavoro e altri fattori, spesso di ordine politico.
Lo scheduling con priorità può essere sia con prelazione sia senza prelazione. Quando un processo arriva alla ready queue, si confronta la sua priorità con quella del processo attualmente in esecuzione. Un algoritmo di scheduling con priorità con diritto di prelazione sottrae la cpu al processo attualmente in esecuzione se la priorità del processo appena arrivato è superiore. Un algoritmo senza prelazione si limita a porre l’ultimo processo arrivato alla testa della ready queue.
Un problema importante relativo agli algoritmi di scheduling con priorità è l’attesa indefinita (starvation). Un processo pronto per l’esecuzione, ma che non dispone della cpu, si può considerare bloccato nell’attesa della cpu. Un algoritmo di scheduling con priorità può lasciare processi a bassa priorità nell’attesa indefinita della cpu. In un sistema con carico elevato, un flusso costante di processi con priorità maggiore può impedire a un processo con bassa priorità di accedere alla cpu. Generalmente accade che o il processo è eseguito, alle ore 2 del mattino della domenica, quando il sistema ha finalmente ridotto il proprio carico, oppure il calcolatore, prima o poi, va in crash e perde tutti i processi a bassa priorità non terminati. Corre voce che, quando fu fermato l’ibm 7094 al mit, nel 1973, si scoprì che un processo con bassa priorità sottoposto nel 1967 non era ancora stato eseguito.
Una soluzione al problema dell’attesa indefinita dei processi con bassa priorità è costituita dall’invecchiamento (aging); si tratta di una tecnica di aumento graduale delle priorità dei processi che attendono nel sistema da parecchio tempo. Per esempio, se le priorità variano da 127 (bassa) a 0 (alta), si potrebbe incrementare di 1 ogni secondo il livello di priorità di un processo in attesa. Alla fine anche un processo con priorità iniziale 127 può ottenere la priorità massima nel sistema e quindi essere eseguito: un processo con priorità 127 impiegherebbe poco più di 2 minuti per raggiungere la priorità 0.
Un’altra opzione consiste nel combinare scheduling circolare e scheduling con priorità in modo tale che il sistema esegua il processo con la priorità più alta ed esegua processi con la stessa priorità utilizzando lo scheduling circolare. Si consideri per esempio il seguente insieme di processi, con la durata delle sequenze di operazioni della cpu espressa in millisecondi:
| Processo | Durata della sequenza | Priorità |
|---|---|---|
Utilizzando lo scheduling con priorità insieme allo scheduling circolare per processi con uguale priorità, con un quanto di tempo di 2 millisecondi, questi processi sarebbero ordinati secondo il seguente diagramma di Gantt:

In questo esempio, il processo ha la priorità più alta e verrà quindi eseguito fino al completamento. Dopo , i processi e hanno la priorità maggiore e verranno eseguiti in modalità rr. Si noti che quando il processo termina, all’istante 16, il processo è il processo con la priorità più alta e verrà quindi eseguito fino al suo completamento. Restano poi i processi e che, avendo uguale priorità, verranno eseguiti in ordine circolare fino al completamento.
Round Robin
L’algoritmo di scheduling circolare (round-robin, rr) è simile allo scheduling fcfs, ma aggiunge la capacità di prelazione in modo che il sistema possa commutare fra i vari processi. Ciascun processo riceve una piccola quantità fissata del tempo della cpu, chiamata quanto di tempo o porzione di tempo (in inglese time quantum o time slice), che varia generalmente da 10 a 100 millisecondi; la ready queue è trattata come una coda circolare. Lo scheduler della cpu scorre la ready queue, assegnando la cpu a ciascun processo per un intervallo di tempo della durata massima di un quanto di tempo.
Per implementare lo scheduling rr si gestisce la ready queue come una coda fifo. I nuovi processi si aggiungono alla fine della ready queue. Lo scheduler della cpu prende il primo processo dalla ready queue, imposta un timer in modo che invii un segnale d’interruzione alla scadenza di un intervallo pari a un quanto di tempo, e attiva il dispatcher per eseguire il processo.
A questo punto si può verificare una delle due seguenti situazioni: il processo ha una sequenza di operazioni della cpu di durata minore di un quanto di tempo, quindi il processo stesso rilascia volontariamente la cpu e lo scheduler passa al processo successivo della ready queue; oppure la durata della sequenza di operazioni è più lunga di un quanto di tempo; in questo caso il timer scade e invia un segnale d’interruzione al sistema operativo, che esegue un cambio di contesto e mette il processo alla fine della ready queue. Lo scheduler quindi seleziona il processo successivo nella ready queue.
Il tempo d’attesa medio per il criterio di scheduling rr è spesso abbastanza lungo. Si consideri il seguente insieme di processi che si presenta al tempo 0, con la durata delle sequenze di operazioni della cpu espressa in millisecondi:
| Processo | Durata della sequenza |
|---|---|
Se si usa un quanto di tempo di 4 millisecondi, il processo ottiene i primi 4 millisecondi ma, poiché richiede altri 20 millisecondi, è soggetto a prelazione dopo il primo quanto di tempo e la cpu passa al processo successivo della coda, il processo . Poiché il processo non necessita di 4 millisecondi, termina prima che il suo quanto di tempo si esaurisca, così si assegna immediatamente la cpu al processo successivo, il processo . Una volta che tutti i processi hanno ricevuto un quanto di tempo, si assegna nuovamente la cpu al processo per un ulteriore quanto di tempo. Dallo scheduling rr risulta quanto segue:

Calcoliamo ora il tempo di attesa medio per questa sequenza. resta in attesa per 6 millisecondi (10 – 4), per 4 millisecondi e per 7 millisecondi. Il tempo d’attesa medio è di 17/3 = 5,66 millisecondi
Nell’algoritmo di scheduling rr la cpu si assegna a un processo per non più di un quanto di tempo per volta (a meno che questo sia l’unico processo ready). Se la durata della sequenza di operazioni della cpu di un processo eccede il quanto di tempo, il processo viene sottoposto a prelazione e riportato nella ready queue. L’algoritmo di scheduling rr è pertanto con prelazione.
Se nella ready queue esistono n processi e il quanto di tempo è pari a q, ciascun processo ottiene 1/n-esimo del tempo di elaborazione della cpu in frazioni di, al massimo, q unità di tempo. Ogni processo non deve attendere per più di (n – 1) × q unità di tempo per il suo successivo quanto di tempo. Per esempio, dati cinque processi e un quanto di tempo di 20 millisecondi, ogni processo usa fino a 20 millisecondi ogni 100 millisecondi.
Le prestazioni dell’algoritmo rr dipendono molto dalla dimensione del quanto di tempo. Nel caso limite in cui il quanto di tempo sia molto lungo, il criterio di scheduling rr si riduce al criterio di scheduling fcfs. Se il quanto di tempo è molto breve (per esempio, un millisecondo), il criterio rr può portare a un numero elevato di cambi di contesto. Assumiamo che, per esempio, ci sia un solo processo della durata di 10 unità di tempo, se il quanto di tempo è di 12 unità, il processo impiega meno di un quanto di tempo; se però il quanto di tempo è di 6 unità, il processo richiede 2 quanti di tempo e un cambio di contesto; e se il quanto di tempo è di un’unità di tempo, occorrono nove cambi di contesto, con proporzionale rallentamento dell’esecuzione del processo:
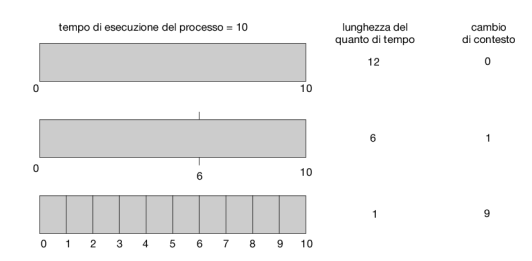
Quindi il quanto di tempo deve essere ampio rispetto alla durata del cambio di contesto; se, per esempio, questa è pari al 10 per cento del quanto di tempo, allora s’impiega in cambi di contesto circa il 10 per cento del tempo d’elaborazione della cpu. In pratica, nella maggior parte dei sistemi moderni un quanto di tempo va dai 10 ai 100 millisecondi. Il tempo richiesto per un cambio di contesto non eccede solitamente i 10 microsecondi, risultando quindi una modesta frazione del quanto di tempo.
Anche il tempo di completamento (turnaround time) dipende dalla dimensione del quanto di tempo: com’è evidenziato nella Figura 5.6, il tempo di completamento medio di un insieme di processi non migliora necessariamente con l’aumento della dimensione del quanto di tempo. In generale, il tempo di completamento medio può migliorare se la maggior parte dei processi termina la successiva sequenza di operazioni della cpu in un solo quanto di tempo. Per esempio, dati tre processi della durata di 10 unità di tempo ciascuno e un quanto di una unità di tempo, il tempo di completamento medio è di 29 unità. Se però il quanto di tempo è di 10 unità, il tempo di completamento medio scende a 20 unità. Aggiungendo il tempo del cambio di contesto, con un piccolo quanto di tempo, il tempo di completamento medio aumenta ancora poiché sono richiesti più cambi di contesto.
Benché il quanto di tempo debba essere grande in confronto al tempo necessario al cambio di contesto, non deve essere tuttavia troppo grande. Se il quanto di tempo è molto ampio, il criterio di scheduling rr, come puntualizzato in precedenza, tende al criterio fcfs. Empiricamente si può stabilire che l’80 per cento delle sequenze di operazioni della cpu debba essere più breve del quanto di tempo.
Scheduling a code multilivello
Nello scheduling con priorità e in quello circolare tutti i processi possono essere collocati in una singola coda da cui lo scheduler seleziona il processo con la priorità più alta da eseguire. A seconda di come vengono gestite le code può essere necessaria una ricerca O(n) per determinare il processo con maggiore priorità. Nella pratica è spesso più semplice disporre di code separate per ciascuna priorità distinta e lasciare che lo scheduling con priorità si occupi semplicemente di selezionare il processo nella coda con priorità più alta, come illustrato nella Figura 5.7. Questo approccio, noto come scheduling a code multilivello, funziona bene anche quando lo scheduling con priorità è combinato con lo scheduling rr: se ci sono più processi nella coda con priorità più alta, questi vengono eseguiti in ordine circolare. Nella forma più generale di questo approccio viene assegnata una priorità statica a ciascun processo e un processo rimane nella stessa coda per tutto il suo tempo di esecuzione.
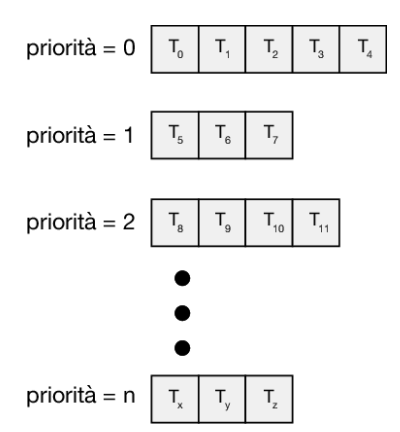
Un algoritmo di scheduling a code multilivello può anche essere utilizzato per suddividere i processi in diverse code in base al tipo di processo (Figura 5.8). Per esempio, di solito vengono divisi i processi in primo piano (interattivi) e i processi in background (batch). Questi due tipi di processi hanno requisiti diversi in termini di tempo di risposta e possono quindi avere esigenze di scheduling diverse. Inoltre, i processi in primo piano possono avere una priorità più alta (definita esternamente) rispetto ai processi in background. È possibile utilizzare code distinte per i processi in primo piano e in background e ciascuna coda potrebbe avere il proprio algoritmo di schedulazione. Per la coda in primo piano si potrebbe utilizzare, per esempio, un algoritmo rr, mentre lo scheduling della coda in background potrebbe utilizzare un algoritmo fcfs.
In questa situazione è inoltre necessario avere uno scheduling tra le code; si tratta comunemente di uno scheduling a priorità fissa con prelazione. Per esempio, la coda dei processi in foreground (in primo piano) può avere la priorità assoluta sulla coda dei processi in background.
Si consideri come esempio il seguente algoritmo di scheduling a code multilivello, in ordine di priorità:
- processi in tempo reale
- processi di sistema
- processi interattivi
- processi batch
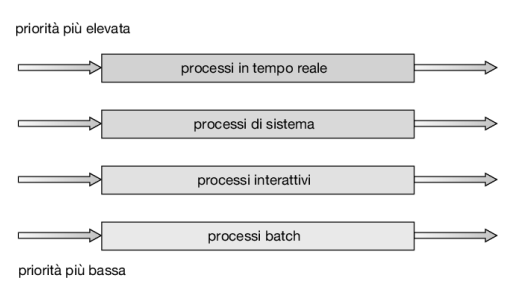
Ogni coda ha la priorità assoluta sulle code di priorità più bassa; per esempio nessun processo della coda dei processi batch può iniziare l’esecuzione finché le code per i processi di sistema, interattivi e interattivi di editing non siano tutte vuote. Se un processo interattivo di editing entrasse nella ready queue durante l’esecuzione di un processo in background, si avrebbe la prelazione su quest’ultimo.
Un’altra possibilità è definire porzioni di tempo per le code. A ogni coda si assegna una parte del tempo d’elaborazione della cpu, suddivisibile a sua volta tra i processi che la costituiscono. Nel caso foreground/background, per esempio, si può assegnare l’80 per cento del tempo d’elaborazione della cpu alla coda dei processi in foreground (in primo piano), con scheduling rr tra i suoi processi; mentre per la coda dei processi in background si riserva il 20 per cento del tempo d’elaborazione della cpu, assegnato col criterio fcfs.
Scheduling a code multilivello con retroazione
Di solito in un algoritmo di scheduling a code multilivello i processi si assegnano in modo permanente a una coda all’entrata nel sistema, e non si possono spostare tra le code. Se, per esempio, esistono code distinte per i processi che si eseguono in foreground e quelli che si eseguono in background, i processi non possono passare da una coda all’altra, poiché non possono cambiare la loro natura di processi in foreground o in background. Quest’impostazione è rigida, ma ha il vantaggio di avere un basso carico di scheduling.
Lo scheduling a code multilivello con retroazione (multilevel feedback queue scheduling), invece, permette ai processi di spostarsi fra le code. L’idea consiste nel separare i processi che hanno caratteristiche diverse in termini di cpu burst. Se un processo usa troppo tempo di elaborazione della cpu, viene spostato in una coda con priorità più bassa. Questo schema mantiene i processi con prevalenza di i/o e i processi interattivi nelle code con priorità più elevata. Inoltre, si può spostare in una coda con priorità più elevata un processo che attende troppo a lungo in una coda a priorità bassa. Questa forma di aging impedisce il verificarsi di un’attesa indefinita.
Si consideri, per esempio, uno scheduler a code multilivello con retroazione con tre code, numerate da 0 a 2, come nella Figura 5.9. Lo scheduler fa eseguire tutti i processi presenti nella coda 0; quando la coda 0 è vuota, si eseguono i processi nella coda 1; analogamente, i processi nella coda 2 si eseguono solo se le code 0 e 1 sono vuote. Un processo in ingresso nella coda 1 ha la prelazione sui processi della coda 2; un processo in ingresso nella coda 0, a sua volta, ha la prelazione sui processi della coda 1.
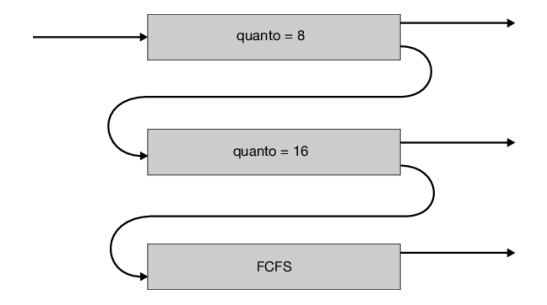
All’ingresso nella ready queue i processi vengono assegnati alla coda 0 e ottengono un quanto di tempo di 8 millisecondi; i processi che non terminano entro tale quanto di tempo, vengono spostati alla fine della coda 1. Se la coda 0 è vuota, si assegna un quanto di tempo di 16 millisecondi al processo alla testa della coda 1, ma se questo non riesce a completare la propria esecuzione, viene sottoposto a prelazione e messo nella coda 2. Se le code 0 e 1 sono vuote, si eseguono i processi della coda 2 secondo il criterio fcfs. Per evitare l’attesa indefinita, un processo in attesa da troppo tempo in una coda a priorità bassa viene gradualmente spostato in una coda con priorità più alta
Questo algoritmo di scheduling dà la massima priorità ai processi con una sequenza di operazioni della cpu della durata di non più di 8 millisecondi. I processi di questo tipo ottengono rapidamente la cpu, terminano la propria sequenza di operazioni della cpu e passano alla successiva sequenza di operazioni di i/o; anche i processi che necessitano di più di 8 ma di non più di 24 millisecondi (coda 1) vengono serviti rapidamente, anche se con una priorità inferiore. I processi più lunghi finiscono automaticamente nella coda 2 e sono serviti secondo il criterio fcfs all’interno dei cicli di cpu lasciati liberi dai processi delle code 0 e 1.
Generalmente uno scheduler a code multilivello con retroazione è caratterizzato dai seguenti parametri:
- numero di code;
- algoritmo di scheduling per ciascuna coda;
- metodo usato per determinare quando spostare un processo in una coda con priorità maggiore;
- metodo usato per determinare quando spostare un processo in una coda con priorità minore;
- metodo usato per determinare in quale coda si deve mettere un processo quando richiede un servizio.
La definizione di uno scheduler a code multilivello con retroazione costituisce il più generale criterio di scheduling della cpu, che nella fase di progettazione si può adeguare a un sistema specifico. Sfortunatamente corrisponde anche all’algoritmo più complesso; la definizione dello scheduler migliore richiede infatti particolari metodi per la selezione dei valori dei diversi parametri.
Scheduling per sistemi multiprocessore e multicore
Fin qui la trattazione ha riguardato lo scheduling della cpu in un sistema dotato di un singolo core di elaborazione. Se sono disponibili più unità d’elaborazione è possibile la distribuzione del carico (load sharing), ma il problema dello scheduling diviene proporzionalmente più complesso. Si sono sperimentate diverse possibilità e, come s’è visto nella trattazione dello scheduling di una sola cpu, “la soluzione migliore” non esiste.
Tradizionalmente, il termine multiprocessore faceva riferimento a sistemi che fornivano più processori fisici, in cui ogni processore conteneva una cpu single-core. Tuttavia, la definizione di multiprocessore si è evoluta in modo significativo e sui moderni sistemi di elaborazione il termine multiprocessore si applica ora alle seguenti architetture di sistema:
- cpu multicore.
- Core multithread.
- Sistemi numa.
- Sistemi multiprocessore eterogenei.
Nel seguito si analizzano brevemente alcuni problemi attinenti lo scheduling per sistemi multiprocessore nel contesto di queste diverse architetture. Nei primi tre casi ci concentriamo su sistemi in cui i processori sono identici – omogenei – in termini di funzionalità: si può quindi utilizzare qualsiasi cpu disponibile per eseguire qualsiasi processo presente nella coda. Nell’ultimo caso analizziamo un sistema in cui i processori non hanno le stesse capacità
Approcci allo scheduling per multiprocessori
Due strategie principali: AMP e SMP
Definizione: multiprocessing asimmetrico (AMP)
Il multiprocessing asimmetrico (detto anche AMP, dall’inglese Asymmetric Multiprocessing) è una strategia di schedulazione a breve termine in cui tutte le decisioni, l’elaborazione dell’I/O e altre attività del sistema a un solo processore detto master server, mentre gli altri processori eseguono soltanto il codice utente.
Vantaggi del multiprocessing asimmetrico
Vantaggi del multiprocessing asimmetrico:
- Riduce la necessità di condividere dati grazie all’accesso di un solo processore alle strutture dati del sistema.
Svantaggi del multiprocessing asimmetrico
Svantaggi del multiprocessing asimmetrico:
- Il master server costituisce un potenziale collo di bottiglia in grado di ridurre le prestazioni generali del sistema.
L’approccio standard oggi per supportare i multiprocessori è la multielaborazione simmetrica (smp).
Definizione: multiprocessing simmetrico (SMP)
Il multiprocessing simmetrico (detto anche SMP, dall’inglese Symmetric Multiprocessing) è una strategia di schedulazione a breve termine in cui ciascun processore è in grado di autogestirsi. Lo scheduling viene realizzato facendo in modo che lo scheduler di ciascun processore esamini la ready queue e selezioni un thread da eseguire.
Osservazione: ready queue comuni o private?
Si noti che questo approccio offre due possibili strategie per organizzare i thread da selezionare per l’esecuzione:
- tutti i thread possono trovarsi in una ready queue comune;
- ogni processore può avere una propria coda privata di thread.
La Figura 5.11 mostra un confronto tra le due strategie:
- Se viene utilizzata la prima opzione è possibile avere race condition sulla coda condivisa e occorre quindi assicurarsi che due processori distinti non scelgano di eseguire lo stesso thread e che i thread nella coda non vengano persi. Come discusso nel Capitolo 6 è possibile usare una forma di lock per proteggere la ready queue comune da questa race condition. Il lock sarebbe tuttavia molto conteso, poiché tutti gli accessi alla coda richiederebbero il possesso del lock, e l’accesso alla coda condivisa costituirebbe probabilmente un collo di bottiglia per le prestazioni.
- La seconda opzione permette a ciascun processore di schedulare i thread da una coda di esecuzione privata e pertanto non risente dei possibili problemi di prestazioni associati a una coda condivisa. Per questa ragione si tratta dell’approccio più comune sui sistemi che supportano smp. Inoltre, come descritto nel Paragrafo 5.5.4, l’uso di code di esecuzione private, una per ogni processore, può portare a un uso più efficiente della memoria cache. Vi sono anche dei problemi nell’utilizzo di code distinte per ogni processore, in particolare relativi ai diversi carichi di lavoro. Tuttavia, come vedremo, possono essere utilizzati algoritmi di bilanciamento per distribuire equamente i carichi di lavoro tra tutti i processori
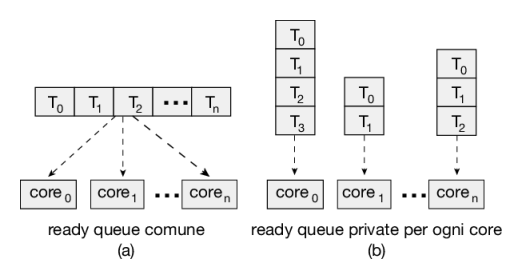
Praticamente tutti i sistemi operativi moderni supportano smp, inclusi Windows, Linux, macos e i sistemi mobili Android e ios. Nel resto di questo paragrafo discuteremo alcune questioni concernenti i sistemi smp, relativamente alla progettazione degli algoritmi di scheduling della cpu.
Processori multicore
Tradizionalmente i sistemi smp hanno reso possibile la concorrenza tra thread con l’utilizzo di diversi processori fisici. Tuttavia, la pratica recente nel progetto hardware dei calcolatori è di inserire più core di elaborazione in un unico chip fisico, dando origine a un processore multicore. Ogni core mantiene il proprio stato e appare dunque al sistema operativo come un processore fisico separato. I sistemi smp che usano processori multicore sono più veloci e consumano meno energia dei sistemi in cui ciascun processore è costituito da un singolo chip
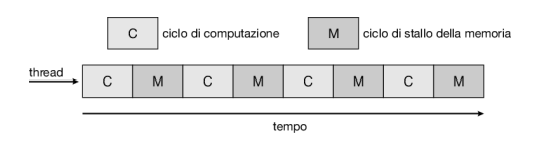
I processori multicore possono complicare i problemi relativi allo scheduling. Proviamo a vedere che cosa può succedere. Le ricerche hanno permesso di scoprire che quando un processore accede alla memoria, una quantità significativa di tempo trascorre in attesa della disponibilità dei dati. Questa situazione, nota come stallo della memoria, può verificarsi per varie ragioni, per esempio la mancanza dei dati richiesti nella cache. La Figura 5.12 mostra uno stallo della memoria. In questo scenario, il processore può trascorrere fino al 50 per cento del suo tempo attendendo che i dati siano disponibili in memoria.
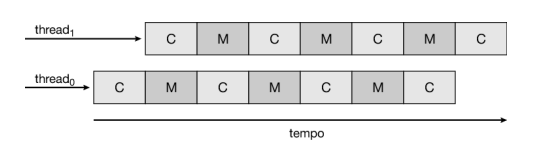
Per rimediare a questa situazione, molti dei progetti hardware recenti implementano delle unità di calcolo multithread in cui due o più thread hardware sono assegnati a un singolo core. In questo modo, se un thread è in situazione di stallo in attesa della memoria, il core può passare a eseguire un altro thread. La Figura 5.13 mostra un processore a due thread nel quale l’esecuzione dei thread 0 e 1 sono avvicendate nel tempo. Dal punto di vista del sistema operativo, ogni thread hardware mantiene il suo stato architetturale, come il puntatore alle istruzioni e il set di registri, e appare quindi come una cpu logica che è disponibile per eseguire un thread software. Questa tecnica, nota come chip multithreading (cmt), è illustrata nella Figura 5.14, dove è mostrato un processore contenente quattro core di elaborazione, ognuno dei quali contiene due thread hardware: dal punto di vista del sistema operativo sono presenti otto cpu logiche.
I processori Intel utilizzano il termine hyper-threading (noto anche come multithreading simultaneo o smt) per descrivere l’assegnazione di più thread hardware a un singolo core di elaborazione. I processori Intel contemporanei, come l’i7, supportano due thread per core, mentre il processore Oracle Sparc M7 supporta otto thread per core, con otto core per processore, fornendo così al sistema operativo 64 cpu logiche.
In generale, ci sono due modi per rendere un core multithread: attraverso il multithreading a grana grossa (coarse-grained) o il multithreading a grana fine (fine-grained):
- Nel multithreading coarse-grained un thread resta in esecuzione su un processore fino al verificarsi di un evento a lunga latenza, per esempio uno stallo di memoria. A causa dell’attesa introdotta dall’evento a lunga latenza, il processore deve passare a un altro thread e iniziare a eseguirlo. Tuttavia, il costo per cambiare il thread in esecuzione è alto, perché occorre ripulire la pipeline delle istruzioni prima che il nuovo thread possa iniziare a essere eseguito sull’unità di calcolo. Una volta che il nuovo thread è in esecuzione inizia a riempire la pipeline con le sue istruzioni.
- Il multithreading fine (anche detto interleaved multithreading) passa da un thread a un altro a un livello molto più fine di granularità (tipicamente al termine di un ciclo di istruzione). Tuttavia, il progetto di sistemi a multithreading fine include una logica dedicata al cambio di thread. Ne risulta così che il costo del passaggio da un thread a un altro è piuttosto basso.
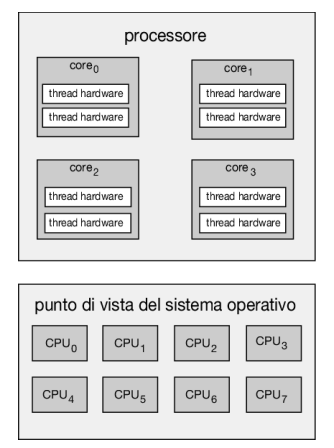
È importante notare che le risorse del core fisico (come cache e pipeline) devono essere condivise tra i suoi thread hardware e dunque un core di elaborazione può eseguire solo un thread hardware alla volta. Di conseguenza, un processore multithreaded e multicore richiede due diversi livelli di scheduling, come mostrato nella Figura 5.15, che illustra un core di elaborazione dual-threaded.
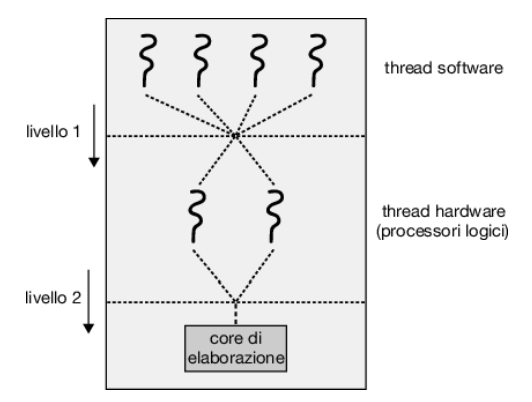
A un livello vi sono le decisioni di scheduling che devono essere prese dal sistema operativo per scegliere quale thread software eseguire su ogni thread hardware (cpu logica). Ai fini pratici, tali decisioni sono state l’obiettivo principale di questo capitolo e per questo livello di scheduling il sistema operativo può scegliere qualsiasi algoritmo, compresi quelli descritti nel Paragrafo 5.3.
Un secondo livello di scheduling specifica in che modo ciascun core decide quale thread hardware eseguire. In questa situazione è possibile adottare diverse strategie. Un approccio consiste nell’utilizzare un semplice algoritmo round-robin per assegnare un thread hardware al core di elaborazione: questo è l’approccio adottato da Ultrasparc T3. Intel Itanium, un processore dual-core con due thread hardware per core, adotta un approccio differente. In questo caso viene assegnato a ciascun thread hardware un indice dinamico di urgenza (urgency) compreso tra 0 e 7, dove 0 rappresenta l’urgenza più bassa e 7 la più alta. Itanium identifica cinque diversi eventi in grado di attivare un cambio di thread. Quando si verifica uno di questi eventi, la logica di cambio di thread confronta l’urgenza dei due thread e seleziona il thread con il valore di urgenza più alto da eseguire sul core del processore.
Si noti che i due diversi livelli di scheduling mostrati nella Figura 5.15 non sono necessariamente mutuamente esclusivi. Infatti, se lo scheduler del sistema operativo (il primo livello) viene reso consapevole della condivisione delle risorse del processore, può prendere decisioni di scheduling più efficaci. Per esempio, supponiamo che una cpu abbia due core di elaborazione e che ogni core abbia due thread hardware. Se due thread software sono in esecuzione su questo sistema, possono essere in esecuzione sullo stesso core o su core separati. Se entrambi vengono assegnati allo stesso core, devono condividere le risorse del processore e quindi è probabile che procedano più lentamente rispetto al caso in cui siano assegnati a core distinti. Se il sistema operativo è a conoscenza del livello di condivisione delle risorse del processore può programmare i thread software su processori logici che non condividono risorse.
Bilanciamento del carico
Sui sistemi smp è importante che il carico di lavoro sia distribuito equamente tra tutte le unità elaborative per sfruttare appieno i vantaggi di avere più processori. Se ciò non avvenisse, alcuni processori potrebbero restare inattivi mentre altri verrebbero intensamente sfruttati con una coda di processi in attesa. Il bilanciamento del carico tenta di ripartire il carico di lavoro uniformemente tra tutti i processori di un sistema smp. Bisogna notare che il bilanciamento è necessario, di norma, solo nei sistemi in cui ciascun processore ha una coda privata di processi eseguibili. Nei sistemi che mantengono una coda comune, il bilanciamento del carico è sovente superfluo: un processore inattivo passerà immediatamente all’esecuzione di un processo dalla coda comune dei processi eseguibili.
Il bilanciamento del carico può seguire due approcci: la migrazione push e la migrazione pull.
- La prima prevede che un processo apposito controlli periodicamente il carico di ogni processore: se identifica uno sbilanciamento, riporta il carico in equilibrio, spostando i processi dal processore saturo ad altri più liberi, o inattivi.
- La migrazione pull, invece, si ha quando un processore inattivo sottrae un processo in attesa a un processore sovraccarico.
I due tipi di migrazione non sono mutuamente esclusivi, e trovano spesso applicazione contemporanea nei sistemi con bilanciamento del carico. Lo scheduler cfs di Linux, per esempio, che vedremo nel Paragrafo 5.7.1, e lo scheduler ule dei sistemi Freebsd, si avvalgono di entrambe le tecniche.
Il concetto di “carico bilanciato” può avere significati diversi. Una prima possibilità è richiedere semplicemente che tutte le code contengano approssimativamente lo stesso numero di thread. In alternativa, il bilanciamento potrebbe richiedere un’equa distribuzione delle priorità dei thread su tutte le code. Inoltre, in determinate situazioni, potrebbe non essere sufficiente alcuna di queste strategie, poiché esse possono essere in contrasto con gli obiettivi dell’algoritmo di scheduling. (Lasciamo ulteriori considerazioni su questo argomento come esercizio).
Affinità per il processore
Si consideri che cosa accade alla memoria cache dopo che un processo è stato eseguito da uno specifico processore: i dati che il processore ha trattato più recentemente permangono nella cache e, di conseguenza, i successivi accessi alla memoria da parte del processo tendono a utilizzare spesso la memoria cache (chiamata warm cache). Si consideri ora che cosa succede se un processo si sposta su un altro processore: i contenuti della memoria cache devono essere invalidati sul processore di partenza, mentre la cache del processore di arrivo deve essere nuovamente riempita. A causa degli alti costi di svuotamento e riempimento della cache, molti sistemi smp tentano di impedire il passaggio di thread da un processore all’altro, mirando a mantenere un thread sempre sullo stesso processore e a sfruttare i vantaggi della warm cache. Si parla di predilezione per il processore (processor affinity), intendendo con ciò che un processo ha una predilezione per il processore su cui è in esecuzione.
Le due strategie per l’organizzazione della coda dei thread disponibili per lo scheduling descritte nel Paragrafo 5.5.1 hanno implicazioni sulla predilezione per il processore. Infatti, se adottiamo l’approccio di una ready queue comune, un thread può essere selezionato per l’esecuzione da qualsiasi processore e ogni volta che un thread è schedulato su un nuovo processore la cache del processore deve essere ripopolata. Con le ready queue private, distinte per ogni processore, un thread viene sempre schedulato sullo stesso processore e può quindi trarre vantaggio dal contenuto di una warm cache. In sostanza, le ready queue private forniscono la predilezione del processore gratuitamente!
La predilezione per il processore può assumere varie forme. Quando un sistema operativo si propone di mantenere un processo su un singolo processore, ma non garantisce che sarà così, si parla di predilezione debole (soft affinity). In questo caso il sistema operativo tenta di mantenere il processo su un singolo processore, ma è possibile che un processo migri da un processore all’altro. Alcuni sistemi dispongono di chiamate di sistema per realizzare la predilezione forte (hard affinity), permettendo così a un processo di specificare un sottoinsieme di processori su cui può essere eseguito. Molti sistemi supportano sia la predilezione debole sia la predilezione forte. Linux, per esempio, implementa la predilezione debole, ma fornisce anche la chiamata sched_setaffinity() per il supporto della predilezione forte, consentendo così a un thread di specificare l’insieme di cpu su cui può essere eseguito.
Anche l’architettura della memoria principale di un sistema può influenzare le questioni relative alla predilezione. La Figura 5.16 mostra un’architettura con accesso non uniforme alla memoria (numa) in cui sono presenti due chip fisici di processore, ciascuno con la propria cpu e memoria locale. Sebbene un’interconnessione di sistema consenta a tutte le cpu in un sistema numa di condividere uno spazio di indirizzamento fisico, una cpu ha un accesso più rapido alla propria memoria locale rispetto alla memoria locale di un’altra cpu. Se lo scheduler della cpu del sistema operativo e gli algoritmi di gestione della memoria sono consci del numa e lavorano insieme, a un thread che è stato schedulato su una particolare cpu può essere allocata la memoria più vicina a dove risiede la cpu, fornendo così al thread un accesso alla memoria più veloce possibile.
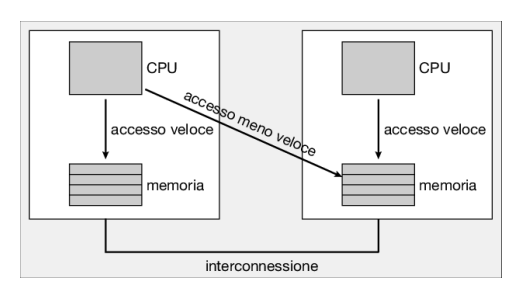
È interessante notare che il bilanciamento del carico spesso contrasta i vantaggi della predilezione per il processore. Il vantaggio di mantenere un thread in esecuzione sullo stesso processore, infatti, è che il thread può sfruttare i suoi dati nella memoria cache di quel processore. Il bilanciamento del carico, spostando un thread da un processore a un altro, rimuove questo vantaggio. Allo stesso modo, la migrazione di un thread tra processori può comportare svantaggi su sistemi numa, in cui un thread può essere spostato su un processore che richiede tempi di accesso alla memoria più lunghi. In altre parole, esiste un conflitto naturale tra il bilanciamento del carico e la riduzione dei tempi di accesso alla memoria. Per questa ragione gli algoritmi di scheduling per i moderni sistemi numa multicore sono diventati piuttosto complessi. Nel Paragrafo 5.7.1 si esamina l’algoritmo di scheduling cfs di Linux, analizzando come questo algoritmo bilanci questi obiettivi in conflitto tra loro.
Multiprocessing eterogeneo
Negli esempi che abbiamo discusso finora tutti i processori sono identici in termini di funzionalità e consentono quindi a qualsiasi thread di essere eseguito su qualsiasi core di elaborazione. L’unica differenza è che i tempi di accesso alla memoria variano in base al bilanciamento del carico e alle politiche di predilezione per il processore, nonché sui sistemi numa.
Sebbene i sistemi mobili includano architetture multicore, alcuni sistemi attuali sono progettati utilizzando core che eseguono lo stesso set di istruzioni, ma differiscono in termini di velocità di clock e gestione energetica, includendo la possibilità di regolare il consumo energetico di un core fino a renderlo inattivo (idle). Tali sistemi sono chiamati sistemi a multielaborazione eterogenea o, più brevemente, sistemi hmp (heterogeneous multiprocessing). Si noti che questa non è una forma di multielaborazione asimmetrica come quella descritta nel Paragrafo 5.5.1, poiché sia le attività di sistema sia quelle dell’utente possono essere eseguite su qualsiasi core. Piuttosto, l’intenzione dietro hmp è quella di gestire meglio il consumo di energia assegnando un task a un determinato core in base alle sue specifiche richieste
Nei processori arm che supportano hmp questa tipologia di architettura è nota come big.little ed è costituita da grandi core con prestazioni più elevate (big) combinati con piccoli core ad alta efficienza energetica (little). I core grandi consumano più energia e dovrebbero quindi essere usati solo per brevi periodi, mentre i core piccoli consumano meno energia e possono quindi essere utilizzati per periodi più lunghi
Questo approccio offre molti vantaggi. Grazie alla combinazione di un certo numero di core più lenti con core più veloci, uno scheduler della cpu può assegnare task che non richiedono prestazioni elevate, ma che potenzialmente saranno eseguiti per periodi più lunghi (come le attività in background) sui core piccoli, contribuendo così a preservare la carica della batteria. Allo stesso modo, le applicazioni interattive che richiedono più potenza di elaborazione, ma restano in esecuzione per periodi più brevi, possono essere assegnate ai core grandi. Inoltre, se il dispositivo mobile si trova in una modalità di risparmio energetico, è possibile disabilitare i core grandi ad alto consumo e forzare il sistema a utilizzare solo i core piccoli a basso consumo. Windows 10 supporta lo scheduling hmp, consentendo a un thread di selezionare una politica di scheduling ottimale secondo le sue esigenze di risparmio energetico
Esempi di scheduling nei sistemi operativi
È importante notare che viene qui utilizzato il termine scheduling dei processi in senso generale. In realtà nei sistemi Solaris e Windows stiamo descrivendo lo scheduling dei thread del kernel e in Linux lo scheduling dei task.
Scheduling di Linux
Lo scheduling dei processi in Linux ha avuto una storia interessante. Prima della versione 2.5, il kernel Linux utilizzava una variante dell’algoritmo tradizionale di scheduling di unix.
Tuttavia questo algoritmo, progettato senza pensare ai sistemi smp, non supporta adeguatamente sistemi multiprocessore e fornisce prestazioni scarse nei sistemi in grado di eseguire un gran numero di processi. Con la versione 2.5 del kernel, lo scheduler è stato rivisitato per includere un algoritmo di scheduling noto come O(1), che veniva eseguito in tempo costante indipendentemente dal numero di task nel sistema. Lo scheduler O(1) forniva anche un maggiore supporto ai sistemi smp fra cui la gestione della predilezione e il bilanciamento del carico. Tuttavia, in pratica, anche se lo scheduler O(1) forniva eccellenti prestazioni su sistemi smp, portava a tempi di risposta troppo scarsi sui processi interattivi, comuni in molti sistemi desktop. Durante lo sviluppo del kernel 2.6, lo scheduler è stato nuovamente rivisto e dalla versione 2.6.23 del kernel, lo scheduler cfs (completely fair scheduler) è diventato l’algoritmo predefinito di scheduling Linux.
Nei sistemi Linux lo scheduling si basa sulle classi di scheduling. A ogni classe è assegnata una specifica priorità. Utilizzando diverse classi di scheduling, il kernel può utilizzare algoritmi distinti in base alle esigenze del sistema e dei suoi processi. I criteri di scheduling per un server Linux, per esempio, possono essere diversi da quelli per un dispositivo mobile che utilizza Linux. Per decidere quale task eseguire, lo scheduler seleziona il task con priorità più alta appartenente alla classe di scheduling a priorità più elevata. Il kernel Linux standard implementa due classi di scheduling, che verranno discusse nel seguito: (1) una classe di scheduling predefinita che utilizza l’algoritmo cfs e (2) una classe di scheduling real-time. Possono naturalmente essere aggiunte ulteriori classi.
Invece di utilizzare regole rigide che associano un valore di priorità relativo alla lunghezza di un quanto di tempo, lo scheduler cfs assegna a ogni task una percentuale del tempo di elaborazione della cpu. Questa percentuale è calcolata sulla base dei valori nice value assegnati a ciascun task. I nice value vanno da –20 a +19, dove un valore numerico più basso indica una priorità relativa superiore. I task con nice value minori ricevono una maggiore percentuale di tempo di elaborazione della cpu rispetto ai task con nice value più alti. Il nice value di default è 0. Il termine nice value deriva dall’idea che se un task aumenta il suo nice value, per esempio da 0 a +10, si comporta in maniera gentile – in inglese “nice” – rispetto agli altri task del sistema, abbassando la sua priorità relativa. cfs non utilizza valori discreti per i quanti di tempo, ma piuttosto definisce una latenza obiettivo (targeted latency), cioè un intervallo di tempo entro il quale ogni task eseguibile dovrebbe andare in esecuzione almeno una volta. Le porzioni di tempo di cpu vengono assegnate a partire dal valore della latenza obiettivo. La latenza obiettivo, che ha valore di default e un valore minimo, può aumentare qualora il numero di task attivi nel sistema cresca oltre una certa soglia.
Lo scheduler cfs non assegna direttamente le priorità, ma registra per quanto tempo ogni task è stato eseguito mantenendo il tempo di esecuzione virtuale di ogni task nella variabile vruntime. Il tempo di esecuzione virtuale è associato a un fattore di decadimento che dipende dalla priorità di un task: task a bassa priorità hanno fattori di decadimento più alti di task ad alta priorità. Per i task con priorità normale (nice value pari a 0), il tempo di esecuzione virtuale coincide con il tempo effettivo di esecuzione. Quindi, se un task con priorità normale viene eseguito per 200 millisecondi, anche il suo vruntime sarà di 200 millisecondi, ma se un task con priorità inferiore viene eseguito per 200 millisecondi, il suo vruntime sarà superiore a 200 millisecondi. Analogamente, se un task con priorità più alta viene eseguito per 200 millisecondi, il suo vruntime sarà inferiore a 200 millisecondi. Per decidere il prossimo task da eseguire, lo scheduler seleziona semplicemente il task con il valore vruntime più piccolo. Inoltre, un task con priorità più alta che diventa disponibile per l’esecuzione può avere prelazione su un task con priorità inferiore.
Esaminiamo lo scheduler cfs in azione. Si supponga che due task abbiano lo stesso nice value. Un task è i/o-bound e l’altro è cpu-bound. In genere, un task i/o-bound verrà eseguito solo per brevi periodi di tempo prima di bloccarsi in attesa di i/o, mentre un task cpu-bound esaurirà il suo periodo di tempo ogni volta che avrà l’opportunità di essere in esecuzione su un processore. Pertanto, il valore di vruntime del task i/o-bound diventerà inferiore rispetto a quello del task cpu-bound, dando così al task i/o-bound una priorità superiore. A questo punto, se il task cpu-bound è in esecuzione quando il task i/o-bound diventa pronto per l’esecuzione (per esempio, quando l’i/o che il task sta attendendo diventa disponibile), il task i/o-bound effettuerà la prelazione del task cpu-bound.
Linux implementa anche lo scheduling in tempo reale utilizzando lo standard posix, come descritto nel Paragrafo 5.6.6. Qualsiasi task pianificato utilizzando le politiche real-time sched_fifo o sched_rr viene eseguito con una priorità più alta rispetto ai normali task (non real-time). Linux usa due intervalli di priorità distinti, uno per i task real-time e l’altro per i normali task. Ai task real-time vengono assegnate priorità statiche nell’intervallo 0-99, mentre ai task non real-time vengono assegnate priorità nell’intervallo 100-139. Questi due intervalli sono mappati in uno schema di priorità globale in cui i valori numericamente inferiori indicano priorità relative più alte. Ai task normali vengono assegnate priorità in base ai loro nice value: il valore –20 viene mappato nella priorità 100 e il valore +19 nella priorità 139. Questo schema è mostrato nella Figura 5.26.
Lo scheduler cfs supporta anche il bilanciamento del carico, utilizzando una sofisticata tecnica che equilibra il carico tra i core di elaborazione, ma è anche compatibile con numa (numa-aware) e riduce al minimo la migrazione dei thread. cfs definisce il carico di ogni thread come combinazione della sua priorità e del suo tasso medio di utilizzo della cpu. Pertanto, un thread con una priorità elevata, ma che si dedica per lo più all’i/o e richiede poco utilizzo della cpu, ha un carico generalmente basso, simile al carico di un thread con bassa priorità che ha un elevato utilizzo della cpu. Utilizzando questa metrica, il carico di una coda è la somma dei carichi di tutti i thread nella coda e il bilanciamento garantisce semplicemente che tutte le code abbiano approssimativamente lo stesso carico.
Come evidenziato nel Paragrafo 5.5.4, tuttavia, la migrazione di un thread può penalizzare l’accesso alla memoria a causa della necessità di invalidare il contenuto della cache o, nei sistemi numa, di incorrere in tempi di accesso alla memoria più lunghi. Per risolvere questo problema, Linux identifica un sistema gerarchico di domini di scheduling. Un dominio di scheduling è un insieme di core che può essere bilanciato l’uno con l’altro, come mostrato nella Figura 5.27. I core in ciascun dominio di scheduling sono raggruppati in base al modo in cui condividono le risorse del sistema. Per esempio, sebbene ciascun core mostrato nella Figura 5.27 possa avere una propria cache di livello 1 (L1), coppie di core condividono una cache di livello 2 (L2) e sono quindi organizzate in due domini separati dominio e dominio . Allo stesso modo, questi due domini possono condividere una cache di livello 3 (L3) e sono dunque organizzati in un dominio a livello di processore (noto anche come nodo numa). Facendo un ulteriore passo in avanti, su un sistema numa un dominio più grande a livello di sistema combinerebbe nodi numa distinti a livello di processore.
La strategia generale alla base di cfs è di bilanciare i carichi all’interno dei domini, iniziando dal livello più basso della gerarchia. Prendendo la Figura 5.27 come esempio, inizialmente un thread migrerebbe solo tra core sullo stesso dominio (cioè all’interno di dominio0 o di dominio1). Al livello successivo il bilanciamento del carico avverrebbe tra dominio0 e dominio1. cfs tende a non migrare i thread tra nodi numa distinti quando un thread venisse spostato più lontano dalla sua memoria locale; una tale migrazione si potrebbe verificare solo in presenza di gravi squilibri di carico. Come regola generale, se il sistema nel suo complesso è occupato, cfs non eseguirà il bilanciamento del carico oltre il dominio locale di ciascun core per evitare peggioramenti della latenza della memoria nei sistemi numa.
Prestazioni del CFS
Lo scheduler cfs di Linux fornisce un efficiente algoritmo per la selezione del prossimo task da eseguire. Ogni task eseguibile è posto in un R-B albero, un albero binario di ricerca bilanciato, la cui chiave si basa sul valore di vruntime. L’albero è il seguente:
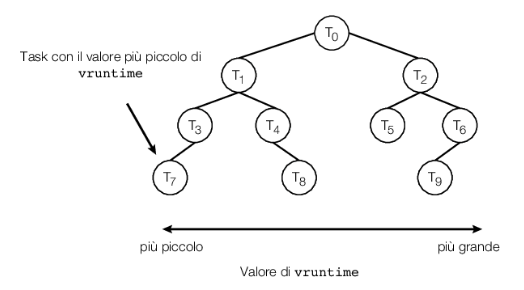
Quando un task diventa eseguibile viene aggiunto all’albero. Se un task dell’albero non è eseguibile (per esempio, se è bloccato in attesa di i/o), viene rimosso. In generale, i task a cui è stato dato meno tempo di elaborazione (valori minori di vruntime) si trovano nel lato sinistro dell’albero e i task a cui è stato dato più tempo di elaborazione si trovano sul lato destro. Secondo le proprietà di un albero binario di ricerca il nodo più a sinistra ha il valore della chiave più piccolo, il che significa, per lo scheduler cfs, che è il task con la massima priorità. Poiché l’albero R-B è bilanciato, la ricerca del nodo più a sinistra richiede O(logN) operazioni (dove N è il numero di nodi dell’albero). Tuttavia, per ragioni di efficienza, lo scheduler Linux memorizza questo valore nella variabile rb_leftmost in modo da poter determinare qual è il prossimo task da eseguire recuperando semplicemente il valore memorizzato.