Definizione: stallo
Uno stallo (in inglese deadlock) è un problema causato dalla mancata sincronizzazione tra unità di esecuzione nei sistemi concorrenti che si verifica quando due o più unità di esecuzione si bloccano a vicenda, aspettando che una esegua una certa azione che serve all’altra e viceversa.
Le condizioni necessarie affinché avvenga uno stallo sono:
- la condizione di mutua esclusione,
- la condizione di possesso e attesa,
- la condizione di assenza di prelazione e
- la condizione di attesa circolare.
La gestione di uno stallo si può affrontare in tre modi:
Esempio di stallo
Un esempio di stallo è rappresentato da due persone che vogliono disegnare: hanno a disposizione solo una riga e una matita e hanno bisogno di entrambe. Potendo prendere un solo oggetto per volta, se uno prende la matita, l’altro prende la riga, e se entrambi aspettano che l’altro gli dia l’oggetto che ha in mano, i due generano un stallo.
Condizioni necessarie per uno stallo
Definizione: condizione di mutua esclusione
La condizione di mutua esclusione afferma che, per verificarsi uno stallo tra due o più unità di esecuzione, ci deve essere almeno una risorsa condivisa in mutua esclusione, cioè utilizzabile da una sola unità di esecuzione alla volta. Se quella risorsa è occupata da un’unità e un’altra prova a richiederla, quest’ultima deve aspettare che si liberi.
Definizione: condizione di possesso e attesa
La condizione di possesso e attesa afferma che, per verificarsi uno stallo tra due o più unità di esecuzione, ci deve essere un’unità di esecuzione in possesso di almeno una risorsa condivisa che attende di acquisire altre risorse condivise già in possesso di altre unità di esecuzione.
Definizione: condizione di assenza di prelazione
La condizione di assenza di prelazione afferma che, per verificarsi uno stallo tra due o più unità di esecuzione, le risorse condivise non possono essere prelazionate, ossia possono essere rilasciate dall’unità di esecuzione che le possiede solo volontariamente, dopo aver terminato il proprio compito.
Definizione: condizione di attesa circolare
La condizione di attesa circolare afferma che, per verificarsi uno stallo tra due o più unità di esecuzione, ci deve essere un insieme di unità di esecuzione in cui ogni unità -esima attende una risorsa condivisa posseduta dall’unità -esima, ossia attende una risorsa posseduta da , attende una risorsa posseduta da e così via fino a che attende una risorsa posseduta da e attende una risorsa posseduta da .
Stallo attivo
Definizione: stallo attivo
Uno stallo attivo (in inglese livelock) è un problema causato dall’incorretta sincronizzazione tra unità di esecuzione in cui due o più unità di esecuzione sono in stallo ma, anziché bloccarsi a vicenda aspettando che una esegua una certa azione che serve all’altra e viceversa, almeno una delle unità tenta continuamente di compiere un’azione che non ha successo.
Esempio di stallo attivo
Un esempio di stallo attivo è dato da ciò che a volte accade quando due persone si incontrano in un corridoio: uno si sposta alla sua destra, l’altro alla sua sinistra e nessuna delle due persone può procedere. Poi una si sposta alla sua sinistra e l’altra alla sua destra e così via. Le due persone non sono bloccate, ma non stanno facendo alcun progresso nella direzione desiderata.
Grafo delle attese
Le situazioni di stallo si possono descrivere con maggior precisione avvalendosi di una rappresentazione detta grafo delle attese.
Definizione: grafo delle attese
Un grafo delle attese (o grafo delle attese o grafo di Holt dal nome di Ric Holt che l’ha ideato, in inglese wait-for graph) è un grafo orientato usato per rappresentare l’assegnazione di risorse condivise tra due o più unità di esecuzione in situazioni di stallo composto da:
- Un insieme di vertici , in cui ogni vertice -esimo rappresenta un’unità di esecuzione coinvolta nello stallo; vengono rappresentati con un cerchio.
- Un insieme di vertici , in cui ogni vertice -esimo rappresenta una risorsa condivisa coinvolta nello stallo; vengono rappresentati con un rettangolo contenente tanti pallini quante sono le istanze di quella risorsa.
- Un insieme di archi diretti da un vertice a un vertice , detti archi di richiesta e denotati con , che indicano che l’unità di esecuzione ha richiesto un’istanza della risorsa condivisa .
- Un insieme di archi diretti da un vertice a un vertice , detti archi di assegnazione e denotati con , che indicano che un’istanza della risorsa condivisa è stata assegnata all’unità di esecuzione .
Un arco di richiesta parte dal cerchio dell’unità di esecuzione e finisce nel rettangolo rappresentante la risorsa condivisa , mentre un arco di assegnazione parte dal singolo puntino rappresentante l’istanza della risorsa condivisa e finisce nel cerchio dell’unità di esecuzione .
Quando un’unità di esecuzione richiede un’istanza della risorsa condivisa e questa risorsa può essere immediatamente esaudita, anziché inserire l’arco di richiesta si inserisce direttamente l’arco di assegnazione .
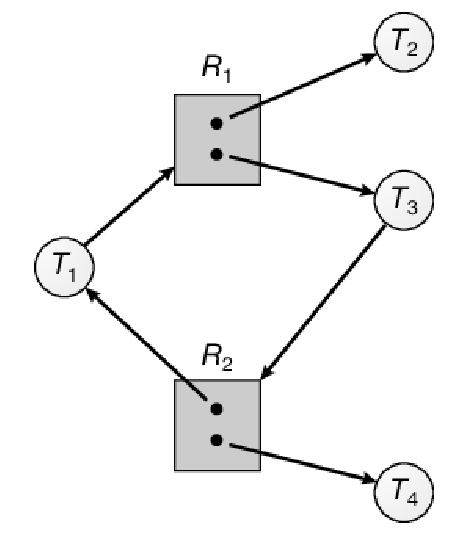
Esempio di grafo delle attese
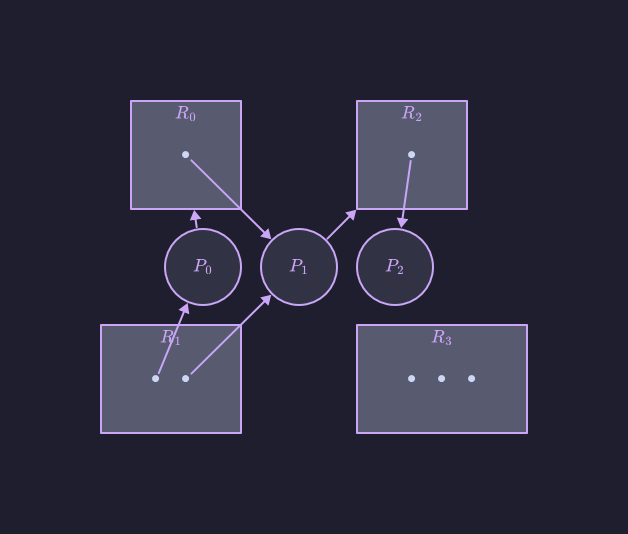
Ecco un esempio di grafo delle attese:
In questo grafo abbiamo:
- Un insieme di unità di esecuzione:
- Un insieme di risorse condivise:
- Un insieme di archi di richiesta:
- Un insieme di archi di assegnazione:
Ogni risorsa condivisa ha le seguenti istanze:
Risorsa condivisa Numero di istanze
Osservazione: cicli nel grafo delle attese
Data la definizione di grafo delle attese, si può mostrare che, se non contiene cicli, nessuna unità di esecuzione del sistema operativo subisce uno stallo; se contiene un ciclo, può sopraggiungere uno stallo.
In particolare:
- se ciascuna risorsa condivisa coinvolta in un ciclo ha esattamente un’istanza, allora siamo in presenza di uno stallo, ma
- se ciascuna risorsa condivisa coinvolta in un ciclo ha più di un’istanza, l’esistenza del ¢iclo stesso non implica necessariamente uno stallo.
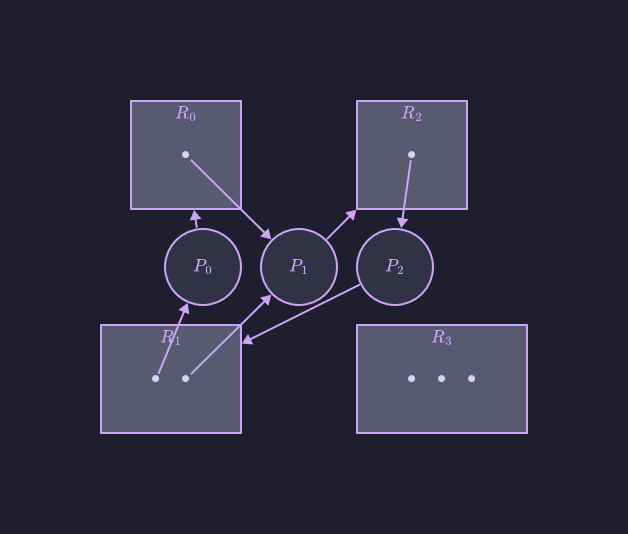
Per spiegare questo concetto conviene ritornare all’esempio di grafo delle attese di prima. Si supponga che l’unità di elaborazione richieda un’istanza della risorsa condivisa . Poiché attualmente non è disponibile alcuna istanza di quella risorsa, si aggiunge un arco di richiesta al grafo:
A questo punto nel grafo abbiamo due cicli minimi:
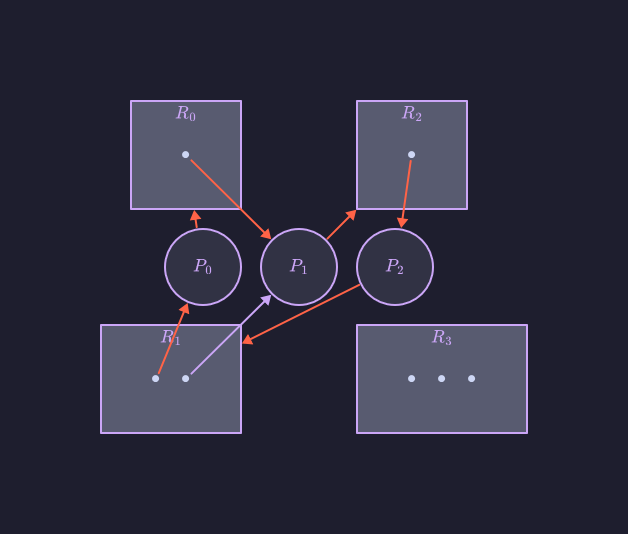
Dati questi due cicli e , abbiamo che le unità di esecuzione , e sono in stallo. Al contrario, consideriamo quest’altro grafo delle attese:
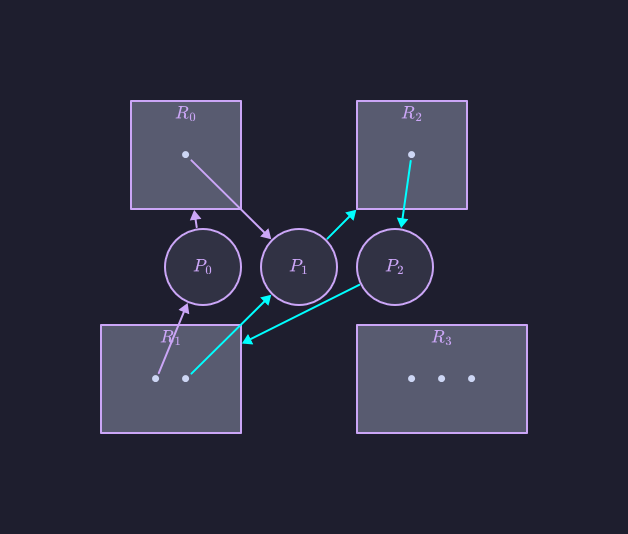
Anche in questo esempio abbiamo un ciclo, ossia:
In questo caso, però, non si ha alcuno stallo: l’unità di esecuzione può rilasciare la propria istanza della risorsa condivisa , che si può assegnare all’unità , rompendo così il ciclo.
Per concludere, quindi:
- L’assenza di cicli nel grafo delle attese implica l’assenza di situazioni di stallo nel sistema operativo.
- Viceversa, la presenza di un ciclo non è sufficiente a implicare la presenza di uno stallo nel sistema operativo.
Ignorare il problema dello stallo
La soluzione adottata nella maggior parte dei sistemi operativi (tra cui Windows e Linux) per gestire uno stallo è l’ignorare il problema dello stallo.
Definizione: ignorare il problema dello stallo
L’ignorare il problema dello stallo è uno dei metodi di gestione dello stallo in cui il sistema operativo non si preoccupa di prevenire, evitare o rilevare e successivamente correggere uno stallo, delegando questo compito alle singole unità di esecuzione.
Svantaggi dell'ignorare il problema dello stallo
Il principale svantaggio dell’ignorare il problema dello stallo è il degrado delle prestazioni del sistema operativo: infatti, nel caso in cui si verifichi uno stallo, ci saranno risorse condivise assegnate ad alcune unità di esecuzione che le negheranno ad altre unità, con un effetto a catena che può arrivare fino al blocco totale del sistema operativo che dovrà essere riavviato manualmente.
Vantaggi dell'ignorare il problema dello stallo
Il vantaggio dell’ignorare il problema dello stallo è l’aspetto economico: dal momento che in molti sistemi operativi le situazioni di stallo si verificano raramente (anche una volta al mese), sostenere una spesa aggiuntiva per gestire appositamente questo problema non sembra essere così conveniente.
Prevenzione dello stallo
Un metodo effettivo per gestire le situazioni di stallo è la sua prevenzione.
Definizione: prevenzione dello stallo
La prevenzione dello stallo è uno dei metodi di gestione dello stallo in cui il sistema operativo si preoccupa di prevenirlo agendo su almeno una delle quattro condizioni necessarie. In particolare:
- si può prevenire la mutua esclusione,
- si può prevenire il possesso e attesa,
- si può prevenire l’assenza di prelazione o
- si può prevenire l’attesa circolare.
Prevenzione della mutua esclusione
Definizione: prevenzione della mutua esclusione
La prevenzione della mutua esclusione comprende tutte le tecniche che si attuano per evitare che si verifichi la condizione di mutua esclusione che può comportare uno stallo tra due o più unità di esecuzione in un sistema operativo. Fa parte delle tecniche di prevenzione dello stallo.
Osservazione: implementazione della prevenzione della mutua esclusione
Implementare effettivamente la prevenzione della mutua esclusione può risultare complicato perché questa operazione richiede che l’unità di esecuzione in questione non debba mai attendere una risorsa condivisa ma, poiché alcune risorse sono intrinsecamente condivise, non si possono in generale prevenire le situazioni di stallo negando la condizione di mutua esclusione. Per esempio, un O o un file non possono essere utilizzati contemporaneamente da più unità di esecuzione senza compromettere la correttezza del risultato, ergo è necessario che queste risorse condivise vengano protette da un meccanismo di mutua esclusione.
Prevenzione del possesso e attesa
Definizione: prevenzione del possesso e attesa
La prevenzione del possesso e attesa comprende tutte le tecniche che si attuano per evitare che si verifichi la condizione di possesso e attesa che può comportare uno stallo tra due o più unità di esecuzione in un sistema operativo. Fa parte delle tecniche di prevenzione dello stallo.
Osservazione: implementazione della prevenzione del possesso e attesa
Per assicurare che la condizione di possesso e attesa non si presenti mai nel sistema operativo (e quindi implementare una prevenzione del possesso e attesa), occorre garantire che un’unità di esecuzione che richiede una risorsa condivisa non ne possegga altre.
Si può usare un protocollo che ponga la condizione che ogni unità, prima di iniziare la propria esecuzione, richieda tutte le risorse condivise che le servono e che esse le siano assegnate. Tuttavia, a causa della natura dinamica della richiesta (es. un processo non può sapere a priori se gli servirà un file o meno), questa condizione è chiaramente poco pratica per la maggior parte delle applicazioni.
Un protocollo alternativo è quello che permette a un’unità di esecuzione di richiedere risorse condivise e adoperarle, ma prima di richiederne di ulteriori deve rilasciare tutte quelle che possiede.
Entrambi i protocolli presentano due svantaggi principali:
- Innanzitutto, l’utilizzo delle risorse condivise in questi modi può risultare poco efficiente, poiché molte risorse possono essere assegnate, ma non utilizzate, per un lungo periodo di tempo. Per esempio, può essere assegnato uno spinlock a un thread per tutta la sua esecuzione, anche se ne ha bisogno soltanto per un breve periodo.
- Il secondo svantaggio è dovuto al fatto che si possono verificare situazioni di attesa indefinita: per esempio, un thread che richieda più risorse condivise molto utilizzate anche da altri thread può trovarsi nella condizione di attenderne indefinitamente la disponibilità, poiché almeno una delle risorse di cui necessita è sempre assegnata a qualche altro thread.
Prevenzione dell’assenza di prelazione
Definizione: prevenzione dell'assenza di prelazione
La prevenzione dell’assenza di prelazione comprende tutte le tecniche che si attuano per evitare che si verifichi la condizione di assenza di prelazione che può comportare uno stallo tra due o più unità di esecuzione in un sistema operativo. Fa parte delle tecniche di prevenzione dello stallo.
Osservazione: implementazione della prevenzione dell'assenza di prelazione
Per assicurare che la condizione di assenza di prelazione non sussista (e quindi implementare una prevenzione dell’assenza di prelazione), si può impiegare il seguente protocollo: se un’unità di esecuzione che possiede una o più risorse condivise ne richiede un’altra che non gli si può assegnare immediatamente (e quindi deve attendere), allora si esercita la prelazione su tutte le risorse condivise attualmente in suo possesso. Si ha così il rilascio involontario di queste risorse condivise che si aggiungono alla lista delle risorse che l’unità di esecuzione sta attendendo, con quest’ultima che viene nuovamente avviata solo quando può ottenere sia le vecchie risorse condivise sia quelle nuova che sta richiedendo.
In alternativa, quando un’unità di esecuzione richiede alcune risorse condivise:
- Se queste sono già assegnate, si sottraggono alle unità di esecuzione che le posseggono e si assegnano all’unità richiedente.
- Se non sono possedute da nessun altra unità di esecuzione ma non sono neanche disponibili, l’unità richiedente deve attendere. Durante l’attesa si può avere la prelazione di alcune sue risorse condivise che nel frattempo vengono richieste da altre unità.
Quest’ultimo protocollo è applicato spesso per risorse condivise il cui stato si può salvare e recuperare facilmente in un secondo tempo, come i registri della CPU e le transazioni su un database, mentre non si può in generale applicare a risorse condivise come gli spinlock e i semafori, ovvero proprio quei tipi di risorse condivise che più comunemente generano situazioni di stallo (zio pera).
Prevenzione dell’attesa circolare
Definizione: prevenzione dell'attesa circolare
La prevenzione dell’attesa circolare comprende tutte le tecniche che si attuano per evitare che si verifichi la condizione di attesa circolare che può comportare uno stallo tra due o più unità di esecuzione in un sistema operativo. Fa parte delle tecniche di prevenzione dello stallo.
[!osservazione] Osservazione: implementazione della prevenzione dell’attesa circolare
Le altre soluzioni per la prevenzione dello stallo sono generalmente poco pratiche nella maggior parte delle situazioni.
La prevenzione dell’attesa circolare, però, offre un’opportunità per una soluzione pratica che renda non valida una delle condizioni di stallo. Un modo per assicurare che tale condizione non si verifichi consiste nell’imporre un ordinamento totale all’insieme di tutte le risorse condivise e imporre che ciascuna unità di esecuzione richieda le risorse condivise in ordine crescente.
Mi spiego meglio: supponiamo che sia l’insieme delle risorse condivise. A ogni risorsa si assegna un numero naturale unico che permetta di confrontare due risorse condivise e stabilirne la relazione d’ordine. Formalmente, si definisce una funzione iniettiva
che a ogni risorsa condivisa assegna un naturale .
Questo schema si può implementare in un programma imponendo un ordine a tutte le risorse condivise, facendo sì che ogni unità di esecuzione possa richiedere una risorsa solo seguendo un ordine crescente di numerazione. Ciò significa che un’unità può richiedere inizialmente qualsiasi numero di istanze di una certa risorsa , dopo di che:
- Può richiedere istanze di un’altra risorsa se e solo se
- Se, invece, abbiamo che allora deve prima rilasciare le risorse condivise .
In questo modo, la condizione di attesa circolare non può sussistere. Ciò si può dimostrare supponendo, per assurdo, che esista un’attesa circolare. Si supponga che l’insieme di unità di esecuzione coinvolti nell’attesa circolare sia dove attende una risorsa condivisa , posseduta dall’unità (ovviamente attende una risorsa posseduta da ). Poiché l’unità possiede la risorsa mentre richiede la risorsa , è necessario che sia verificata la condizione 1, ossia per tutti gli , ma ciò implica che
Per la proprietà transitiva, risulta che , il che è impossibile; quindi, non può esservi attesa circolare.
Teniamo presente che la semplice esistenza di un ordinamento delle risorse non protegge dallo stallo: è infatti responsabilità degli sviluppatori scrivere programmi che rispettino tale ordinamento. Tuttavia, stabilire un ordine tra risorse condivise come gli spinlock può essere difficile, specialmente su un sistema operativo con centinaia o migliaia di spinlock.
Evitamento dello stallo
Definizione: evitamento dello stallo
L’evitamento dello stallo è uno dei metodi di gestione dello stallo in cui il sistema operativo, anziché prevenire a priori una o più condizioni dello stallo, concede una richiesta di risorsa condivisa da parte di un’unità di esecuzione solo se ciò garantisce il mantenimento di uno stato sicuro del sistema.
Per evitare le situazioni di stallo occorre che il sistema operativo abbia in anticipo informazioni aggiuntive riguardanti le risorse che un thread richiederà e userà durante le sue attività. Con queste informazioni aggiuntive il sistema operativo può decidere se una richiesta di risorse da parte di un thread si può soddisfare o se il thread debba invece attendere. In tale thread di decisione il sistema tiene conto delle risorse correntemente disponibili, di quelle correntemente assegnate a ciascun thread e delle future richieste e futuri rilasci di ciascun thread. Questi metodi sono discussi nel Paragrafo 8.6.
Un metodo alternativo per evitare le situazioni di stallo consiste nel richiedere ulteriori informazioni sulle modalità di richiesta delle risorse. In un sistema con due risorse R1 e R2, per esempio, il sistema potrebbe aver bisogno di sapere che il thread P intende richiedere prima R1 e poi R2, prima di rilasciarle entrambe, mentre il thread Q richiederà prima R2 e poi R1. Una volta acquisita la sequenza completa delle richieste e dei rilasci di ogni thread, il sistema può stabilire per ogni richiesta se il thread debba attendere o meno, per evitare una possibile situazione di stallo futura. In seguito a ogni richiesta, il sistema deve esaminare le risorse attualmente disponibili, le risorse attualmente assegnate a ogni thread e le richieste e i rilasci futuri per ciascun thread.
Gli algoritmi differiscono tra loro per la quantità e il tipo di informazioni richieste. Il modello più semplice e più utile richiede che ciascun thread dichiari il numero massimo delle risorse di ciascun tipo di cui necessita. Data questa informazione a priori, si può costruire un algoritmo capace di assicurare che il sistema non entri mai in stallo. Questo algoritmo per evitare lo stallo esamina dinamicamente lo stato di assegnazione delle risorse per garantire che non possa esistere una condizione di attesa circolare. Lo stato di assegnazione delle risorse è definito dal numero di risorse disponibili e assegnate e dalle richieste massime dei thread. Nei due paragrafi successivi esaminiamo due algoritmi per evitare le situazioni di stallo.
Definizione: stato sicuro di un sistema operativo
Uno stato sicuro del sistema operativo è la condizione in cui il sistema è in grado di assegnare risorse condivise a ciascun’unità di esecuzione che le richiede impedendo il verificarsi di uno stallo.
Uno stato sicuro è assicurato solo se esiste una sequenza di unità di esecuzione tale, per ogni , le richieste di risorse condivise che può ancora fare si possono soddisfare impiegando le risorse condivise attualmente disponibili più quelle possedute da tutti i tali che . Se le risorse condivise richieste da non sono disponibili immediatamente, allora deve attendere che tutti i abbiano finito la loro esecuzione e che le abbiano rilasciate, e e a quel punto può ottenere tutte le risorse di cui ha bisogno, completare la sua esecuzione, restituire le risorse assegnate e terminare. Quando termina, può ottenere le risorse richieste, e così via.
[!esempio]
Per illustrare come funziona il mantenimento dello stato sicuro, consideriamo un sistema operativo con 12 risorse condivise e 3 processi , e .
Il processo può richiedere 10 risorse, il processo può richiederne 4 e il processo può richiedere fino a 9. Supponendo che in un dato istante possieda 5 risorse e che i processi e ne possiedano 2 ciascuno, restano libere 3 risorse.
| Processo | Risorse richieste | Risorse possedute |
|---|---|---|
All’istante , il sistema operativo si trova in uno stato sicuro: la sequenza soddisfa la condizione di sicurezza, poiché al processo si possono assegnare immediatamente tutte le risorse richieste, che saranno poi restituite (a quel punto saranno disponibili 5 risorse), quindi il thread può ottenere tutte le risorse richieste e restituirle (il sistema avrà 10 risorse disponibili) e infine il thread potrebbe ottenere tutte le sue risorse e restituirle (rendendo quindi disponibili tutte e 12 le risorse).
Un sistema può passare da uno stato sicuro a uno stato non sicuro. Si supponga che all’istante il thread richieda un’ulteriore risorsa e che questa gli sia assegnata: il sistema non si trova più nello stato sicuro. A questo punto, si possono assegnare tutte le risorse richieste soltanto al thread . Al momento della restituzione, il sistema avrà solo 4 risorse disponibili. Poiché al thread sono assegnate 5 risorse, ma il numero massimo è 10, il thread può richiederne altre 5; se lo fa, poiché queste non sono disponibili, il thread deve attendere. Analogamente, il thread può richiedere altre 6 risorse ed essere costretto ad attendere; il risultato è una situazione di stallo. L’errore è stato commesso nel soddisfare la richiesta di un’ulteriore risorsa fatta dal thread . Se fosse stato costretto ad attendere il termine di uno degli altri thread e il conseguente rilascio delle sue risorse, la situazione di stallo si sarebbe potuta evitare.
Dato il concetto di stato sicuro, si possono definire algoritmi che permettano di evitare le situazioni di stallo. L’idea è semplice: è sufficiente assicurare che il sistema rimanga sempre in uno stato sicuro. Il sistema si trova inizialmente in uno stato sicuro; ogni volta che un thread richiede una risorsa disponibile, il sistema deve stabilire se la risorsa può essere allocata oppure se il thread debba attendere. Si soddisfa la richiesta solo se l’assegnazione lascia il sistema in uno stato sicuro.
In questo modo, se un thread richiede una risorsa attualmente disponibile può essere comunque costretto ad attendere. Quindi, l’utilizzo delle risorse può essere inferiore rispetto a quello che si avrebbe in assenza di un algoritmo per evitare le situazioni di stallo.
Algoritmo con grafo delle attese
Quando il sistema per l’assegnazione delle risorse è tale che ogni tipo di risorsa ha una sola istanza, per evitare le situazioni di stallo si può far uso di una variante del grafo delle attese definito nel Paragrafo 8.3.2. Oltre agli archi di richiesta e di assegnazione, si introduce un nuovo tipo di arco, l’arco di “rivendicazione” (claim edge). Un arco di rivendicazione indica che il thread può richiedere la risorsa in un qualsiasi momento futuro. Quest’arco ha la stessa direzione dell’arco di richiesta, ma si rappresenta con una linea tratteggiata. Quando il thread richiede la risorsa , l’arco di rivendicazione diventa un arco di richiesta. Analogamente, quando rilascia la risorsa , l’arco di assegnazione diventa un arco di rivendicazione .
Occorre sottolineare che le risorse devono essere rivendicate a priori nel sistema. Ciò significa che prima che il thread inizi l’esecuzione, tutti i suoi archi di rivendicazione devono essere già inseriti nel grafo delle attese. Questa condizione si può rendere meno stringente permettendo l’aggiunta di un arco di rivendicazione al grafo solo se tutti gli archi associati al thread sono archi di rivendicazione.
Si supponga che il thread richieda la risorsa . La richiesta si può soddisfare solo se la conversione dell’arco di richiesta nell’arco di assegnazione non causa la formazione di un ciclo nel grafo delle attese. Possiamo verificare la condizione di sicurezza con un algoritmo di rilevamento dei cicli, che richiede un numero di operazioni dell’ordine di , dove è il numero dei thread del sistema.
Se non esiste alcun ciclo, l’assegnazione della risorsa lascia il sistema in uno stato sicuro. Se invece si trova un ciclo, l’assegnazione conduce il sistema in uno stato non sicuro e il thread deve attendere che si soddisfino le sue richieste.
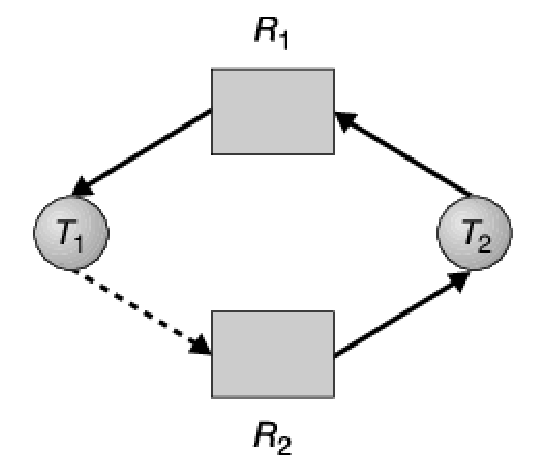
Per illustrare questo algoritmo si consideri questo grafo delle attese:
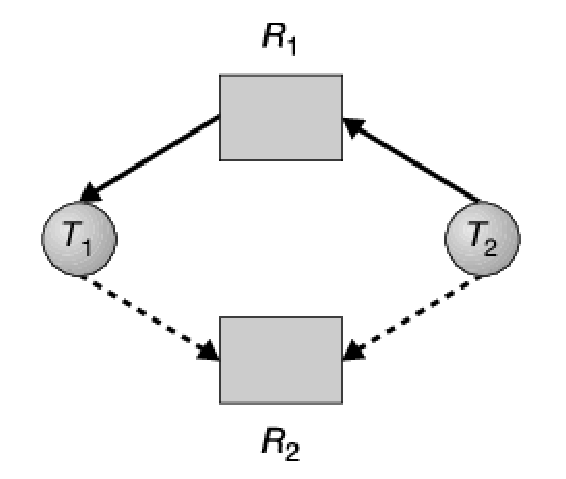
Si supponga che richieda . Sebbene sia attualmente libera, non può essere assegnata a , poiché, com’è evidenziato qua sotto, quest’operazione creerebbe un ciclo nel grafo e un ciclo indica che il sistema è in uno stato non sicuro. Se, a questo punto, richiedesse , si avrebbe uno stallo:
Algoritmo del banchiere
L’algoritmo con grafo delle attese non si può applicare ai sistemi di assegnazione delle risorse con più istanze di ciascun tipo di risorsa. L’algoritmo per evitare le situazioni di stallo descritte nel seguito, pur essendo meno efficiente dello schema con grafo delle attese, si può applicare a tali sistemi, ed è noto col nome di algoritmo del banchiere. Questo nome è stato scelto perché l’algoritmo si potrebbe impiegare in un sistema bancario per assicurare che la banca non assegni mai tutto il denaro disponibile, in modo da non poter più soddisfare le richieste di tutti i suoi clienti.
Quando si presenta al sistema, un nuovo thread deve dichiarare il numero massimo delle istanze di ciascun tipo di risorsa di cui potrà aver bisogno. Questo numero non può superare il numero totale delle risorse del sistema. Quando un utente richiede un gruppo di risorse, si deve stabilire se l’assegnazione di queste risorse lasci il sistema in uno stato sicuro. Se si rispetta tale condizione, si assegnano le risorse, altrimenti il thread deve attendere che qualche altro thread ne rilasci un numero sufficiente.
La realizzazione dell’algoritmo del banchiere richiede la gestione di alcune strutture dati che codificano lo stato di assegnazione delle risorse del sistema. Sia n il numero di thread del sistema e m il numero dei tipi di risorsa. Sono necessarie le seguenti strutture dati:
- Disponibili. Un vettore di lunghezza m che indica il numero delle istanze disponibili per ciascun tipo di risorsa; Disponibili[j] = k, significa che sono disponibili k istanze del tipo di risorsa .
- Massimo. Una matrice n × m che definisce la richiesta massima di ciascun thread; Massimo[i, j] = k significa che il thread può richiedere un massimo di k istanze del tipo di risorsa .
- Assegnate. Una matrice n × m che definisce il numero delle istanze di ciascun tipo di risorsa attualmente assegnate a ogni thread; Assegnate[i, j] = k significa che al thread sono correntemente assegnate k istanze del tipo di risorsa .
- Necessità. Una matrice n × m che indica la necessità residua di risorse relativa a ogni thread; Necessità[i, j] = k significa che il thread , per completare il suo compito, può avere bisogno di altre k istanze del tipo di risorsa . Si osservi che Necessità[i, j] = Massimo[i, j] – Assegnate[i, j].
Col trascorrere del tempo, queste strutture dati variano sia nelle dimensioni sia nei valori.
Per semplificare la presentazione dell’algoritmo del banchiere, si usano le seguenti notazioni: supponendo che X e Y siano vettori di lunghezza n, si può affermare che X ≤ Y se e solo se X[i] ≤ Y[i] per ogni i = 1, 2, …, n. Per esempio, se X = (1, 7, 3, 2) e Y = (0, 3, 2, 1), allora Y ≤ X; inoltre Y < X se Y ≤ X e Y ≠ X.
Si possono trattare le righe delle matrici Assegnate e Necessità come vettori chiamandole rispettivamente Assegnate_i e Necessità_i. Il vettore Assegnate_i specifica le risorse correntemente assegnate al thread , mentre il vettore Necessità_i specifica le risorse che il thread può ancora richiedere per completare il suo compito.
Algoritmo di verifica della sicurezza
L’algoritmo utilizzato per scoprire se il sistema è o non è in uno stato sicuro si può descrivere come segue:
- Siano Lavoro e Fine vettori di lunghezza rispettivamente m e n, si inizializza Lavoro = Disponibili e Fine[i] = falso, per i = 0, 1, … , n – 1;
- si cerca un indice i tale che valgano contemporaneamente le seguenti relazioni: a) Fine[i] == falso b) Necessità_i ≤ Lavoro
- se tale i non esiste, si esegue il passo 4;
- Lavoro = Lavoro + Assegnate_i
- Fine[i] = vero
- si va al passo 2
- se Fine[i] == vero per ogni i, allora il sistema è in uno stato sicuro.
Per determinare se uno stato è sicuro tale algoritmo può richiedere un numero di operazioni dell’ordine di m × n^2.
Algoritmo di richiesta delle risorse
Si descrive ora l’algoritmo che determina se le richieste possano essere soddisfatte mantenendo la condizione di sicurezza. Sia Richieste_i il vettore delle richieste per il thread . Se Richieste_i[j] == k, allora il thread richiede k istanze del tipo di risorsa . Se il thread effettua una richiesta di risorse, si svolgono le seguenti azioni:
- se Richieste_j ≤ Necessità_i , si va al passo 2, altrimenti si riporta una condizione d’errore, poiché il thread ha superato il numero massimo di richieste;
- se Richieste_j ≤ Disponibili, si esegue il passo 3, altrimenti deve attendere poiché le risorse non sono disponibili;
- si simula l’assegnazione al thread delle risorse richieste modificando come segue lo stato di assegnazione delle risorse:
- Disponibili = Disponibili – Richieste_i
- Assegnate_i = Assegnate_j + Richieste_i
- Necessità_j = Necessità_j – Richieste_j Se lo stato di assegnazione delle risorse risultante è sicuro, la transazione è completata e al thread si assegnano le risorse richieste. Tuttavia, se il nuovo stato è non sicuro, deve attendere Richieste_i e si ripristina il vecchio stato di assegnazione delle risorse.
Esempio
Illustriamo l’uso dell’algoritmo del banchiere, considerando un sistema con cinque thread, da a , e tre tipi di risorse: A, B, e C. Il tipo di risorse A ha 10 istanze, il tipo B ha 5 istanze e il tipo C ha 7 istanze. Si supponga che all’istante si sia verificata la seguente situazione del sistema:
| Thread | Assegnate (A B C) | Massimo (A B C) | Disponibili (A B C) |
|---|---|---|---|
| 0 1 0 | 7 5 3 | 3 3 2 | |
| 2 0 0 | 3 2 2 | ||
| 3 0 2 | 9 0 2 | ||
| 2 1 1 | 2 2 2 | ||
| 0 0 2 | 4 3 3 |
Il contenuto della matrice Necessità è definito come Massimo – Assegnate:
| Thread | Necessità (ABC) |
|---|---|
| 7 4 3 | |
| 1 2 2 | |
| 6 0 0 | |
| 0 1 1 | |
| 4 3 1 |
Possiamo affermare che il sistema si trova attualmente in uno stato sicuro; infatti, la sequenza soddisfa i criteri di sicurezza. Si supponga ora che il thread richieda un’altra istanza del tipo di risorsa A e due istanze del tipo C, quindi Richieste1 = (1, 0, 2). Per stabilire se questa richiesta si possa soddisfare immediatamente verifichiamo la condizione Richieste1 ≤ Disponibili (vale a dire (1, 0, 2) ≤ (3, 3, 2)), che risulta vera. A questo punto simuliamo che questa richiesta sia stata soddisfatta, e otteniamo il seguente nuovo stato:
| Thread | Assegnate (A B C) | Necessità (ABC) | Disponibili (A B C) |
|---|---|---|---|
| 0 1 0 | 7 4 3 | 2 3 0 | |
| 3 0 2 | 0 2 0 | ||
| 3 0 2 | 6 0 0 | ||
| 2 1 1 | 0 1 1 | ||
| 0 0 2 | 4 3 1 |
Occorre stabilire se questo nuovo stato del sistema sia sicuro; a tale scopo si esegue l’algoritmo di verifica della sicurezza da cui risulta che la sequenza rispetta il requisito di sicurezza. Quindi si può soddisfare immediatamente la richiesta del thread .
Tuttavia, dovrebbe essere chiaro che, quando il sistema si trova in questo stato, una richiesta di (3, 3, 0) da parte di non si può soddisfare perché non sono disponibili le risorse. Inoltre, una richiesta di (0, 2, 0) da parte di non si può soddisfare, anche se le risorse sono disponibili, poiché lo stato risultante sarebbe non sicuro. L’implementazione dell’algoritmo del banchiere è lasciata come esercizio di programmazione.
Rilevamento delle situazioni di stallo
- si può permettere al sistema di entrare in stallo, individuarlo, e quindi eseguire il ripristino.
Se un sistema non impiega né un algoritmo per prevenire né un algoritmo per evitare gli stalli, tali situazioni possono verificarsi. In un ambiente di questo tipo il sistema può servirsi di un algoritmo che ne esamini lo stato, al fine di stabilire se si è verificato uno stallo e in tal caso ricorrere a un secondo algoritmo per il ripristino del sistema. Tali argomenti sono discussi nei Paragrafi 8.7 e 8.8.
Se un sistema non si avvale di un algoritmo per prevenire o evitare lo stallo è possibile che una situazione di stallo si verifichi. In un ambiente di questo genere, il sistema può fornire i seguenti algoritmi:
- un algoritmo che esamini lo stato del sistema per stabilire se si è verificato uno stallo;
- un algoritmo che ripristini il sistema dalla condizione di stallo.
Nell’analisi seguente sono trattati i suddetti argomenti sia per sistemi con una sola istanza di ciascun tipo di risorsa, sia per sistemi con più istanze. Tuttavia, a questo punto, occorre notare che uno schema di rilevamento e ripristino richiede un overhead che include non solo i costi per la memorizzazione delle informazioni necessarie e per l’esecuzione dell’algoritmo di rilevamento, ma anche i potenziali costi dovuti alle perdite di informazioni connesse al ripristino da una situazione di stallo.
Istanza singola di ciascun tipo di risorsa
Se tutte le risorse hanno una sola istanza si può definire un algoritmo di rilevamento di situazioni di stallo che fa uso di una variante del grafo delle attese, detta grafo d’attesa, ottenuta dal grafo delle attese togliendo i nodi dei tipi di risorse e componendo gli archi tra i thread.
Più precisamente, un arco da a del grafo d’attesa implica che il thread attende che il thread rilasci una risorsa di cui ha bisogno. Un arco esiste nel grafo d’attesa se e solo se il corrispondente grafo delle attese contiene due archi e per qualche risorsa . Nella Figura 8.11 sono illustrati un grafo delle attese e il corrispondente grafo d’attesa:
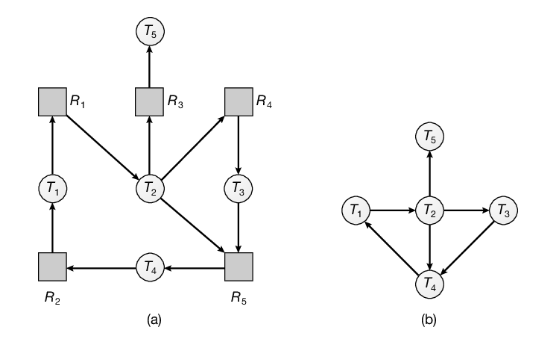
Come in precedenza, nel sistema esiste uno stallo se e solo se il grafo d’attesa contiene un ciclo. Per individuare le situazioni di stallo, il sistema deve mantenere aggiornato il grafo d’attesa e invocare periodicamente un algoritmo che cerchi un ciclo all’interno del grafo. L’algoritmo per il rilevamento di un ciclo all’interno di un grafo richiede un numero di operazioni dell’ordine di n^2, dove con n si indica il numero dei vertici del grafo.
Il toolkit bcc descritto nel Paragrafo 2.10.4 fornisce uno strumento in grado di rilevare potenziali stalli con lock mutex Pthread in un processo utente in esecuzione su un sistema Linux. Lo strumento stallo_detector di bcc funziona inserendo delle probe che tracciano le chiamate alle funzioni pthread_mutex_lock() e pthread_mutex_unlock(). Quando il processo specificato effettua una chiamata a una delle due funzioni, stallo_detector costruisce un grafo d’attesa dei lock mutex in quel processo e segnala il possibile verificarsi di stalli se rileva un ciclo nel grafo.
Rilevamento di situazioni di stallo mediante dump dei thread Java
Sebbene Java non fornisca un esplicito supporto per il rilevamento degli stalli, è possibile utilizzare un dump dei thread per analizzare un programma in esecuzione e determinare se si è verificato uno stallo. Un dump dei thread è un utile strumento di debug in grado di mostrare un’istantanea degli stati di tutti i thread in un’applicazione Java. I dump dei thread Java mostrano anche informazioni sui lock, inclusi i lock che un thread bloccato è in attesa di acquisire. Quando viene generato un dump dei thread, la JVM cerca il grafo d’attesa per individuare i cicli, segnalando eventuali stalli rilevati. Per generare un dump dei thread di un’applicazione in esecuzione occorre digitare dalla riga di comando:
Ctrl-L (unix, Linux o macos)
Ctrl-Break (Windows)
Nella sezione di download del codice sorgente relativa a questo testo forniamo un esempio Java del programma mostrato nella Figura 8.1 e descriviamo come generare un dump dei thread che riporta i thread Java in situazione di stallo.
Più istanze di ciascun tipo di risorsa
Lo schema con grafo d’attesa non si può applicare ai sistemi di assegnazione delle risorse con più istanze di ciascun tipo di risorsa. Il seguente algoritmo di rilevamento di situazioni di stallo è, invece, applicabile a tali sistemi. Esso si serve di strutture dati variabili nel tempo, simili a quelle adoperate nell’algoritmo del banchiere (Paragrafo 8.6.3).
- Disponibili. Vettore di lunghezza m che indica il numero delle istanze disponibili per ciascun tipo di risorsa.
- Assegnate. Matrice n × m che definisce il numero delle istanze di ciascun tipo di risorse correntemente assegnate a ciascun thread.
- Richieste. Matrice n × m che indica la richiesta attuale di ciascun thread. Se Richieste[i, j] = k, significa che il thread P_i sta richiedendo altre k istanze del tipo di risorsa R_j.
La relazione ≤ tra due vettori si definisce come nel Paragrafo 8.6.3. Per semplificare la notazione, le righe delle matrici Assegnate e Richieste si trattano come vettori e, nel seguito, sono indicate rispettivamente come Assegnate_i e Richieste_i. L’algoritmo di rilevamento descritto verifica ogni possibile sequenza di assegnazione per i thread che devono ancora essere completati. Questo algoritmo si può confrontare con quello del banchiere del Paragrafo 8.6.3.
- Siano Lavoro e Fine vettori di lunghezza rispettivamente m e n, si inizializza Lavoro = Disponibili; per i = 0, 1, …, n, se Assegnate_i ≠ 0, allora Fine[i] = falso, altrimenti Fine[i] = vero;
- si cerca un indice i tale che valgano contemporaneamente le seguenti relazioni: a) Fine[i] == falso b) Richieste_j ≤ Lavoro
- se tale i non esiste, si esegue il passo 4;
- Lavoro = Lavoro + Assegnate_i
- Fine[i] = vero
- si torna al passo 2
- se Fine[i] falso per qualche i, 0 ≤ i < n, allora il sistema è in stallo, inoltre, se Fine[i] falso, il thread P_j è in stallo.
Tale algoritmo richiede un numero di operazioni dell’ordine di m × n^2 per controllare se il sistema è in stallo.
Ci si può chiedere perché le risorse del thread siano liberate (passo 3) non appena risulta valida la condizione Richieste_i ≤ Lavoro (passo 2.b). Sappiamo che P_i non è correntemente coinvolto in uno stallo, quindi, assumendo un atteggiamento ottimistico, si suppone che P_i non intenda richiedere altre risorse per completare il proprio compito, e che restituisca presto tutte le risorse. Se non si verifica l’ipotesi fatta, si potrà verificare uno stallo, che sarà rilevato quando si richiamerà nuovamente l’algoritmo di rilevamento.
Per illustrare questo algoritmo, si consideri un sistema con cinque thread, da a , e tre tipi di risorse: A, B, e C. Il tipo di risorsa A ha 7 istanze, il tipo B ha 2 istanze e il tipo C ne ha 6. Si supponga di avere, all’istante , il seguente stato di assegnazione delle risorse:
| Thread | Assegnate (A B C) | Richieste (A B C) | Disponibili (A B C) |
|---|---|---|---|
| 0 1 0 | 0 0 0 | 0 0 0 | |
| 2 0 0 | 2 0 2 | ||
| 3 0 3 | 0 0 0 | ||
| 2 1 1 | 1 0 0 | ||
| 0 0 2 | 0 0 2 |
Il sistema non è in stallo. Infatti eseguendo l’algoritmo troviamo che la sequenza porta a per ogni .
Si supponga ora che il thread richieda un’altra istanza di tipo C. La matrice Richieste viene modificata come segue:
| Thread | Richieste (A B C) |
|---|---|
| 0 0 0 | |
| 2 0 2 | |
| 0 0 1 | |
| 1 0 0 | |
| 0 0 2 |
Ora il sistema è in stallo. Anche se si possono liberare le risorse possedute dal thread , il numero delle risorse disponibili non è sufficiente per soddisfare le richieste degli altri thread, quindi si verifica uno stallo composto dai thread , , e .
Uso dell’algoritmo di rilevamento
Per sapere quando è necessario ricorrere all’algoritmo di rilevamento si devono considerare i seguenti fattori:
- frequenza presunta con la quale si verifica uno stallo;
- numero dei thread che sarebbero influenzati da tale stallo.
Se le situazioni di stallo sono frequenti, è necessario ricorrere spesso all’algoritmo per il loro rilevamento. Le risorse assegnate a thread in stallo rimangono inattive fino all’eliminazione dello stallo. Inoltre, il numero dei thread coinvolti nel ciclo di stallo può aumentare.
Le situazioni di stallo si verificano solo quando qualche thread fa una richiesta che non si può soddisfare immediatamente; questa può essere la richiesta che chiude una catena di thread in attesa. All’estremo, si può invocare l’algoritmo di rilevamento ogni volta che non si può soddisfare immediatamente una richiesta di assegnazione. In questo caso non si identifica soltanto il gruppo di thread in stallo, ma anche lo specifico thread che ha “causato” lo stallo, anche se, in verità, ciascuno dei thread in stallo è un elemento del ciclo all’interno del grafo delle attese, quindi tutti i thread sono, congiuntamente, responsabili dello stallo. Se esistono tipi di risorsa diversi, una singola richiesta può causare più cicli nel grafo delle risorse, ciascuno dei quali viene completato da quest’ultima richiesta, causata da un thread identificabile.
Naturalmente, l’uso dell’algoritmo di rilevamento per ogni richiesta aumenta notevolmente il carico computazionale. Un’alternativa meno dispendiosa è quella in cui l’algoritmo di rilevamento s’invoca a intervalli definiti, per esempio una volta ogni ora, oppure ogni volta che l’utilizzo della cpu scende sotto il 40 per cento, poiché uno stallo rende inefficienti le prestazioni del sistema e quindi porta a una drastica riduzione dell’utilizzo della cpu. Se l’algoritmo di rilevamento viene invocato in momenti arbitrari, poiché nel grafo delle risorse possono coesistere molti cicli, normalmente non si può dire quale fra i tanti thread in stallo abbia “causato” lo stallo.
Gestione degli stalli nei database
I sistemi di gestione dei database (dbms) forniscono un’utile esempio di come sia il software open source sia quello commerciale gestiscano gli stalli. Gli aggiornamenti a un database possono essere eseguiti come transazioni e, per garantire l’integrità dei dati, vengono generalmente utilizzati i lock. Una transazione può coinvolgere diversi lock, non sorprende quindi che siano possibili stalli in un database che esegue più transazioni concorrenti. Per gestire le situazioni di stallo la maggior parte dei dbms include un meccanismo di rilevamento degli stalli e di ripristino. Il database server cercherà periodicamente i cicli nel grafo d’attesa per rilevare situazioni di stallo in un insieme di transazioni. Quando viene rilevato uno stallo, viene designata una transazione vittima che viene interrotta e riportata allo stato iniziale (“rolled back”), permettendo così il rilascio dei lock trattenuti dalla transazione vittima e liberando le restanti transazioni dalla situazione di stallo. Una volta riprese le transazioni rimanenti, la transazione annullata viene riavviata. La scelta di una transazione vittima dipende dal dbms; per esempio, MySQL tenta di selezionare le transazioni che riducono al minimo il numero di righe inserite, aggiornate o eliminate.
Ripristino da situazioni di stallo
Una volta rilevato uno stallo, questo si può affrontare in diversi modi. Una soluzione consiste nell’informare l’operatore della presenza dello stallo, in modo che possa gestirlo manualmente. L’altra soluzione lascia al sistema il ripristino automatico dalla situazione di stallo. Uno stallo si può eliminare in due modi: il primo prevede semplicemente la terminazione di uno o più thread per interrompere l’attesa circolare; il secondo consiste nell’esercitare la prelazione su alcune risorse in possesso di uno o più thread in stallo.
Terminazione di processi e thread
Per eliminare le situazioni di stallo attraverso la terminazione di processi o thread si possono adoperare due metodi; in entrambi il sistema recupera tutte le risorse assegnate ai processi terminati.
- Terminazione di tutti i processi in stallo. Chiaramente questo metodo interrompe il ciclo di stallo, ma l’operazione è molto onerosa; questi processi possono aver già fatto molti calcoli i cui risultati si scartano e probabilmente dovranno essere ricalcolati.
- Terminazione di un processo alla volta fino all’eliminazione del ciclo di stallo. Questo metodo comporta un notevole overhead, poiché, dopo aver terminato ogni processo, si deve invocare un algoritmo di rilevamento per stabilire se esistono ancora processi in stallo.
Procurare la terminazione di un processo può non essere un’operazione semplice: se il processo si trova nel mezzo dell’aggiornamento di un file, la terminazione lascia il file in uno stato scorretto; analogamente, se il processo si trova nel mezzo dell’aggiornamento di dati condivisi mentre è in possesso di un lock mutex, il sistema deve reimpostare lo stato del lock come disponibile, sebbene non sia possibile offrire alcuna garanzia sull’integrità dei dati condivisi.
Se si adopera il metodo di terminazione parziale, occorre determinare quale processo, o quali processi in situazione di stallo devono essere terminati. Analogamente ai problemi di scheduling della cpu, si tratta di seguire un criterio. Le considerazioni sono essenzialmente economiche: si dovrebbero arrestare i processi la cui terminazione causa il minimo costo. Sfortunatamente, il termine minimo costo non è preciso. La scelta dei processi è influenzata da diversi fattori, tra cui i seguenti:
- la priorità del processo;
- il tempo trascorso in computazione e il tempo ancora necessario per completare il compito assegnato al processo;
- la quantità e il tipo di risorse impiegate dal processo (per esempio, se si può effettuare facilmente la prelazione delle risorse);
- la quantità di ulteriori risorse di cui il processo ha ancora bisogno per completare l’esecuzione;
- il numero di processi che si devono terminare.
Prelazione delle risorse
Per eliminare uno stallo si può esercitare la prelazione sulle risorse: le risorse si sottraggono in successione ad alcuni processi e si assegnano ad altri finché si ottiene l’interruzione del ciclo di stallo.
Se per gestire le situazioni di stallo s’impiega la prelazione, si devono considerare i seguenti problemi.
- Selezione di una vittima. Occorre stabilire quali risorse e quali processi si devono sottoporre a prelazione. Come per la terminazione dei processi, è necessario stabilire l’ordine di prelazione allo scopo di minimizzare i costi. I fattori di costo possono includere parametri come il numero delle risorse possedute da un processo in stallo, e la quantità di tempo già spesa durante l’esecuzione del processo.
- Ristabilimento di un precedente stato sicuro. Occorre stabilire che cosa fare con un processo cui è stata sottratta una risorsa. Poiché è stato privato di una risorsa necessaria, la sua esecuzione non può continuare normalmente, quindi deve essere ricondotto a un precedente stato sicuro (rollback) dal quale essere riavviato. Poiché, in generale, è difficile stabilire quale stato sia sicuro, la soluzione più semplice consiste nel terminare il processo e quindi riavviarlo. Benché sia più efficace effettuare il rollback solo fino al punto necessario allo scioglimento della situazione di stallo, questo metodo richiede che il sistema mantenga più informazioni sullo stato di tutti i processi in esecuzione.
- Attesa indefinita (starvation). È necessario assicurare che non si verifichino situazioni d’attesa indefinita, occorre cioè garantire che le risorse non siano sottratte sempre allo stesso processo.
- In un sistema in cui la scelta della vittima avviene soprattutto secondo fattori di costo, può accadere che si scelga sempre lo stesso processo; in questo caso il processo non riesce mai a completare il suo compito; si tratta di una situazione d’attesa indefinita che ogni sistema reale deve saper affrontare. Chiaramente è necessario assicurare che un processo possa essere prescelto come vittima solo un numero finito (e ridotto) di volte; la soluzione più diffusa prevede l’inclusione del numero di rollback tra i fattori di costo.