Il processo è un’istanza di un programma in esecuzione su un computer e rappresenta una delle unità fondamentali di gestione delle risorse da parte di un sistema operativo. Quando un programma viene eseguito, il sistema operativo crea un processo per esso, fornendogli le risorse necessarie, come CPU, memoria, accesso ai file e altri dispositivi.
Osservazione: differenza tra processo e programma
La differenza tra il concetto di processo e quello di programma è fondamentale in informatica, poiché indicano concetti distinti legati all’esecuzione di un’applicazione:
Un programma è un insieme di istruzioni scritte in un linguaggio di programmazione, che descrive quali operazioni un computer deve eseguire. È un’entità passiva e rappresenta il codice sorgente o il codice binario di un’applicazione, che viene memorizzato in un file su disco (es. un file eseguibile .exe su Windows, oppure un documento contenente codice sorgente scritto in un linguaggio di programmazione come Python o C). Un programma non fa nulla da solo finché non viene avviato.
Un processo è un’istanza di un programma in esecuzione sulla memoria centrale (RAM). È un’entità attiva che include il codice del programma, lo stato della CPU (come il contatore del programma e i registri), lo spazio di memoria (segmento di testo e dei dati, stack e heap) e le risorse utilizzate dal programma. Quando un programma viene eseguito, il sistema operativo crea un processo per gestirne l’esecuzione.
Ecco una tabella riassuntiva:
Caratteristica
Programma
Processo
Definizione
Un insieme di istruzioni memorizzate su disco
Un’istanza di un programma in esecuzione
Stato
Entità passiva
Entità attiva
Memoria
Non usa memoria attiva
Utilizza memoria (segmento di testo e dei dati, stack e heap)
Esecuzione
Non è in esecuzione
In esecuzione
Durata
Permanente fino a quando è cancellato o modificato
Temporanea, esiste solo durante l’esecuzione
Gestione
Non richiede gestione attiva
Gestito dal sistema operativo (CPU, memoria, I/O)
Relazione
Un programma può generare più processi
Ogni processo è basato su un programma
Osservazione: più processi per lo stesso programma
Sebbene due processi siano associabili allo stesso programma, sono tuttavia da considerare due sequenze d’esecuzione distinte. Per esempio, l’utente può aprire più finestre dello stesso browser e, di conseguenza, generare più istanze dello stesso programma: ciascuna istanza è un diverso processo e, benché le sezioni di memoria contenenti il codice siano equivalenti, in realtà quelle dei dati, dell’heap e dello stack sono diverse. È inoltre usuale che durante la propria esecuzione un processo generi altri processi.
1 - Il PCB e le informazioni sul processo
Definizione: blocco di controllo del processo (PCB)
Il blocco di controllo del processo (in inglese PCB, Process Control Block) è una struttura dati fondamentale utilizzata dal sistema operativo per memorizzare nella RAM tutte le informazioni relative a un processo dal momento della sua inizializzazione e aggiornato durante l’intero ciclo di vita del processo.
Le informazioni contenute in un PCB variano a seconda delle implementazioni nei vari sistemi operativi, ma in generale sono presenti:
Identificatore del processo (in inglese PID, Process ID): un numero intero univoco assegnato al processo dal sistema operativo. Questo identificatore viene utilizzato per distinguere il processo dagli altri processi attivi.
Program Counter (abbreviato in PC): il valore contenuto nel Program Counter della CPU nel momento in cui il processo è stato interrotto, per consentire di riprendere poi l’esecuzione correttamente dall’ultima istruzione eseguita prima dell’interruzione stessa. Non viene aggiornato di continuo, ma solo nel momento in cui si effettua il cambio di contesto, perché altrimenti sarebbe inutile e poco efficiente tenerlo sincronizzato.
Stato dei registri della CPU: i valori contenuti in alcuni registri della CPU di uso comune (es. accumulatori, puntatori allo stack, registri di uso generale) nel momento in cui il processo è stato interrotto. Come per il Program Counter, non vengono aggiornati di continuo, ma solo nel momento in cui si effettua il cambio di contesto, perché altrimenti sarebbe inutile e poco efficiente tenere tutti i valori sincronizzati.
Informazioni sulla gestione della memoria: dati su come la memoria è allocata al processo, come indirizzi di base e limiti di memoria del processo, oppure tabelle di paginazione o segmentazione, nel caso il sistema operativo utilizzi tecniche di gestione della memoria virtuale.
Informazioni di I/O: un elenco dei dispositivi di input/output utilizzati dal processo (es. file aperti, dispositivi hardware come stampanti, reti) e file descriptor che fanno riferimento ai file aperti dal processo.
Informazioni di schedulazione: un elenco delle informazioni utili alla schedulazione dei processi, come:
Priorità del processo: indica l’importanza relativa del processo rispetto agli altri.
Tempo di esecuzione accumulato: il tempo che il processo ha trascorso in esecuzione.
Algoritmo di schedulazione utilizzato: se il sistema operativo utilizza diverse politiche di schedulazione, nel PCB viene specificata quale viene usata.
Informazioni di accounting: dati utilizzati per tenere traccia del tempo CPU consumato dal processo, della quantità di risorse utilizzate e di eventuali statistiche di utilizzo, utili per la fatturazione o il monitoraggio delle prestazioni.
Informazioni sui segnali: un elenco dei segnali che il processo può ricevere e le relative azioni da eseguire al ricevimento di un segnale (ad esempio, terminare il processo o ignorare il segnale).
1.1 - Stato di un processo
Definizione: stato di un processo
Lo stato di un processo rappresenta la condizione in cui si trova un processo in un dato momento durante la sua esistenza nel sistema operativo. Serve a gestire i processi in modo efficiente, garantendo che la CPU venga utilizzata in modo ottimale senza che rimanga inattiva: per esempio, quando un processo è in attesa, il sistema operativo può assegnare la CPU a un altro processo già pronto per essere eseguito.
Vediamo ora la definizione completa di ogni stato.
Definizione: stato new (nuovo)
Un processo entra nello statonew (nuovo) non appena viene creato e ci rimane finché non sarà pronto per essere eseguito. Durante questa fase di inizializzazione vengono assegnate risorse come memoria e PID.
Definizione: stato ready (pronto)
Un processo entra nello statoready (pronto) quando è pronto per essere eseguito ma sta aspettando che la CPU diventi disponibile perché è occupata da altri processi.
Definizione: stato running (in esecuzione)
Un processo è nello statorunning (in esecuzione) quando utilizza la CPU e le sue istruzioni vengono eseguite.
Definizione: stato waiting (in attesa)
Un processo è nello statowaiting (in attesa) (o anche blocked (bloccato) oppure sleeping (dormiente)) quando è in attesa di un evento esterno per continuare l’esecuzione, come il completamento di un’operazione di input/output (I/O), la ricezione di dati o un messaggio.
Definizione: stato terminated (terminato)
Un processo entra nello statoterminated (terminato) quando ha completato la sua esecuzione o è stato interrotto in modo anomalo (per esempio, a causa di un errore). In questo stato, tutte le risorse del processo vengono rilasciate e il processo non esiste più nel sistema operativo.
1.1.1 - Visualizzazione degli stati correnti dei processi
In UNIX, tramite il comando ps -axjf si può avere una visualizzazione ad albero della lista di tutti i processi presenti nel sistema (ovverosia presenti nella coda dei processi) e, nella colonna STAT, ogni codice è associato a uno stato o una caratteristica del processo ed essi possono essere combinati tra loro:
Codice STAT
Descrizione
S
Sleeping: il processo è nello stato sleeping e si trova all’interno della coda dei processi bloccati in attesa che accada un evento, come un segnale o che un input diventi disponibile.
Disk sleep: il processo è in uno stato sleeping non interrompibile e si trova all’interno della coda dei processi bloccati in attesa che un input o output diventi disponibile.
Zombie: il processo è nello stato zombie, ossia è terminato ma è in attesa di una wait() dal processo padre.
N
Nice: il processo è in esecuzione con bassa priorità.
W
Waiting for paging: il processo è in attesa che le pagine di memoria vengano scritte o lette dal disco (raro nei moderni sistemi Linux).
s
Session leader: il processo è un leader di sessione (es. una shell che avvia altri processi).
+
Il processo appartiene al gruppo di processi in esecuzione in primo piano (foreground) nel terminale.
l
Il processo è multithreaded (usato su alcuni sistemi come Solaris e Linux).
<
Il processo ha una priorità alta, quindi riceve più CPU rispetto ad altri.
1.2 - Identificatore del processo (PID)
Definizione: identificatore del processo (PID)
L’identificatore del processo (in inglese PID, Process ID) è un numero intero univoco assegnato al processo dal sistema operativo. Questo identificatore viene utilizzato per distinguere il processo dagli altri processi attivi all’interno del kernel.
1.2.1 - Ottenere i PID tramite getpid() e getppid()
La funzione getpid() è una chiamata di sistema utilizzata per ottenere il PID del processo che la usa.
Il suo prototipo è il seguente:
#include <unistd.h>pid_t getpid();
dove:
pid_t restituito: PID del processo che ha invocato la funzione.
La funzione getppid() è una chiamata di sistema utilizzata per ottenere il PID del processo padre di quello che la usa.
Il suo prototipo è il seguente:
#include <unistd.h>ppid_t getppid();
dove:
ppid_t restituito: PID del processo padre del processo che ha invocato la funzione.
Le relazioni tra processi costituiscono una struttura ad albero. Il genitore di ogni processo ha a sua volta un genitore, fino ad arrivare alla radice: il processo init.
Esempio: visualizzazione dei PID del figlio e del padre
Ecco un semplice codice in C per visualizzare il PID del processo che sta eseguendo questo programma (il figlio) e quello del suo processo padre (ossia il processo del terminale che ha eseguito il programma):
#include <stdio.h>#include <unistd.h>int main(int argc, char *argv[]) { printf("Id del processo: %d\n", getpid()); printf("Id del processo padre: %d\n", getppid());}
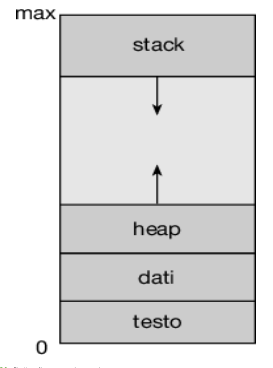
1.3 - Spazio di memoria
Definizione: spazio di memoria di un processo
Lo spazio di memoria di un processo rappresenta l’insieme di tutte le aree di memoria allocate per un processo dal sistema operativo e contiene il codice eseguibile, i dati e le strutture necessarie per far funzionare il programma. Ogni processo ha il proprio spazio di memoria isolato, separato da quello degli altri processi, garantendo che un processo non possa accedere o modificare direttamente la memoria di un altro processo: questa separazione migliora la sicurezza e la stabilità del sistema.
Lo spazio di memoria di un processo è solitamente diviso in:
Segmento di codice (o segmento testo): contiene il codice eseguibile del programma, cioè le istruzioni che la CPU eseguirà. Il segmento di codice è generalmente di sola lettura, per evitare che il codice del programma venga accidentalmente modificato.
Segmento dati: contiene le variabili globali e statiche del programma, divise in:
Dati inizializzati: l’insieme delle variabili globali e statiche a cui è stato assegnato un valore al momento della dichiarazione.
Dati non inizializzati (in inglese BSS, Block Started by Symbol): l’insieme delle variabili globali e statiche che sono dichiarate ma non esplicitamente inizializzate, quindi non hanno un valore inizialmente definito; in alcuni sistemi operativi vengono inizializzate a zero.
Heap: è l’area della memoria dinamica utilizzata per l’allocazione di memoria a runtime. Quando un programma richiede memoria dinamica (ad esempio tramite funzioni come malloc() in C o new in C++/Java), questa viene allocata nello heap, il quale viene gestito unicamente dal programmatore stesso (cioè il programmatore è l’unico responsabile della gestione e del rilascio della memoria).
Stack: area di memoria che viene utilizzata per memorizzare variabili locali, parametri di funzione e indirizzi di ritorno da funzioni. Ogni volta che viene chiamata una funzione, un nuovo “frame” viene aggiunto allo stack, che contiene le informazioni relative a quella particolare chiamata. Quando la funzione termina, lo stack viene “srotolato” e il frame della funzione viene rimosso. Lo stack si espande e si contrae automaticamente durante l’esecuzione del programma, e la sua gestione è di solito curata dal compilatore e dal sistema operativo.
Ecco una rappresentazione grafica dello spazio di memoria di un processo:
1.3.1 - Variazione della grandezza dei segmenti di memoria
Si può notare che le dimensioni dei segmenti di codice e di dati sono fisse, ovvero non cambiano durante l’esecuzione del programma, mentre le dimensioni di stack e heap possono ridursi e crescere dinamicamente durante l’esecuzione:
Ogni volta che si chiama una funzione, viene inserito nello stack una struttura dati detta record di attivazione (in inglese activation record) contenente i suoi parametri, le variabili locali e l’indirizzo di ritorno; quando la funzione restituisce il controllo al chiamante, il record di attivazione viene rimosso dallo stack.
Allo stesso modo, l’heap crescerà quando viene allocata memoria dinamicamente e si ridurrà quando la memoria viene restituita al sistema.
Visto che le sezioni dello stack e dell’heap crescono l’una verso l’altra, tocca al sistema operativo garantire che non si sovrappongano.
2 - Schedulazione dei processi
Definizione: schedulazione dei processi
La schedulazione dei processi è il meccanismo attraverso il quale il sistema operativo decide quale processo deve essere eseguito dalla CPU in un dato momento. In un sistema multitasking, più processi competono tra di loro per l’utilizzo della CPU ed esiste un programma specifico (detto process scheduler) il cui ruolo è quello di assegnare la CPU a questi processi in modo efficiente, garantendo che il sistema risponda correttamente alle richieste degli utenti e ottimizzi le prestazioni.
Esistono diversi tipi di schedulazione, che variano in base a quando e come viene assegnata la CPU ai processi: a lungo, a medio e a breve termine.
Definizione: schedulazione a lungo termine
La schedulazione a lungo termine è un tipo di schedulazione dei processi in cui la CPU decide quali processi devono essere prelevati dalla coda dei processi per essere spostati nella memoria principale (RAM) nella coda dei processi pronti. Il suo scopo è quello di controllare il grado di multiprogrammazione, cioè il numero di processi che possono essere mantenuti in memoria e pronti per essere eseguiti contemporaneamente.
Definizione: schedulazione a medio termine
La schedulazione a medio termine è un tipo di schedulazione dei processi responsabile del cosiddetto swapping dei processi, cioè dello spostamento temporaneo di processi in stato waiting dalla RAM a una memoria secondaria (per esempio su disco) per liberare memoria e fare spazio ad altri processi.
Definizione: schedulazione a breve termine
La schedulazione a breve termine è un tipo di schedulazione dei processi ed è l’unica schedulazione realmente necessaria in un sistema operativo, poiché decide quale processo tra quelli nello stato ready dovrà essere eseguito dalla CPU attraverso l’uso di diversi algoritmi di schedulazione. Questo processo avviene molto frequentemente (nell’ordine dei millisecondi).
2.1 - Code di schedulazione
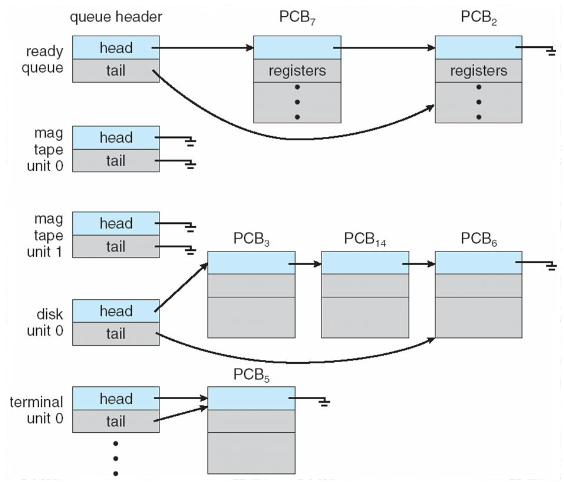
Definizione: code di schedulazione
Le code di schedulazione (in inglese scheduling queues) sono strutture di dati utilizzate dal sistema operativo per gestire i processi in diverse fasi del loro ciclo di vita, determinando quale processo deve essere eseguito, aspettare o bloccarsi, basandosi su determinati algoritmi di schedulazione.
Ogni coda generalmente viene memorizzata come una lista concatenata, con un’intestazione della coda contenente i puntatori al primo PCB della lista che a sua volta comprende un campo puntatore che indica il successivo processo contenuto nella coda e così via:
La coda dei processi (job queue) è una coda di schedulazione che contiene tutti i processi esistenti nel sistema operativo, indipendentemente dallo stato in cui si trovano. Non appena un processo viene creato, viene aggiunto a questa coda.
Definizione: coda dei processi pronti ( ready queue o run queue)
La coda dei processi pronti (ready queue o run queue) è una coda di schedulazione che contiene tutti i processi che sono pronti per l’esecuzione (cioè nello stato ready) e in attesa che la CPU sia disponibile. Lo schedulatore a breve termine sceglie i processi da questa coda per essere eseguiti. Questa coda è una delle più attive e importanti, poiché determina quali processi avranno accesso alla CPU.
Definizione: coda dei dispositivi ( device queue)
La coda dei dispositivi (device queue) è una coda di schedulazione propria di ogni dispositivo di I/O nel sistema operativo. Quando un processo richiede un’operazione di I/O, entra nella coda del dispositivo corrispondente e rimane bloccato finché l’operazione non viene completata. Dopo che l’I/O è completato, il processo può ritornare nella coda dei processi pronti. Per esempio, se un processo sta aspettando che venga completata la lettura da disco, sarà nella coda del disco fino al termine dell’operazione.
Definizione: coda dei dispositivi ( device queue)
La coda dei dispositivi (device queue) è una coda di schedulazione propria di ogni dispositivo di I/O nel sistema operativo. Quando un processo richiede un’operazione di I/O, entra nella coda del dispositivo corrispondente e rimane bloccato finché l’operazione non viene completata. Dopo che l’I/O è completato, il processo può ritornare nella coda dei processi pronti. Per esempio, se un processo sta aspettando che venga completata la lettura da disco, sarà nella coda del disco fino al termine dell’operazione.
Definizione: coda dei processi bloccati ( waiting queue)
La coda dei processi bloccati (waiting queue) è una coda di schedulazione che contiene processi che sono bloccati in attesa di un evento (cioè nello stato waiting), come l’input da un dispositivo o il completamento di una richiesta di I/O. Quando l’evento atteso si verifica, il processo ritorna nella coda dei processi pronti. È simile alla coda dei dispositivi, ma può anche includere processi in attesa di altri tipi di eventi non legati ai dispositivi di I/O.
2.2 - Algoritmi di schedulazione
Un algoritmo di schedulazione è un algoritmo che definisce le regole secondo cui il sistema operativo assegna la CPU ai processi pronti all’esecuzione, cioè quelli nello stato ready elencati nella coda dei processi pronti. È un componente fondamentale del dispatcher del kernel e influisce su tempo di risposta (responsiveness), utilizzo della CPU, throughput ed equità tra processi.
Esistono vari algoritmi di schedulazione utilizzati per determinare quale processo deve essere eseguito dalla CPU in un dato momento. I vari algoritmi di schedulazione hanno caratteristiche diverse che li rendono più adatti a determinati scenari (interattivi, in tempo reale, ecc.), e la scelta dell’algoritmo giusto dipende dai requisiti specifici del sistema.
1. First-Come, First-Served (FCFS)
Descrizione: I processi vengono eseguiti nell’ordine in cui arrivano. Il primo processo che arriva è il primo a essere eseguito.
Vantaggi: Semplice da implementare.
Svantaggi: Può causare il problema della convoy effect, dove i processi più lunghi bloccano l’esecuzione di quelli più brevi, aumentando i tempi di attesa.
2. Shortest Job Next (SJN) o Shortest Job First (SJF):
Descrizione: Il processo con il tempo di esecuzione più breve viene eseguito per primo.
Vantaggi: Minimizza il tempo di attesa medio.
Svantaggi: Difficile da implementare, poiché è necessario conoscere in anticipo la durata di ogni processo. Può causare starvation (processi lunghi potrebbero non essere mai eseguiti).
3. Round Robin (RR):
Descrizione: Ogni processo viene eseguito per un intervallo di tempo fisso (detto quantum), dopodiché la CPU passa al processo successivo in coda. Se un processo non termina nel suo quantum, viene reinserito in coda per essere eseguito più tardi.
Vantaggi: Fornisce equità, poiché ogni processo ha un’opportunità di essere eseguito in modo ciclico.
Svantaggi: Se il quantum è troppo lungo, il comportamento diventa simile a FCFS. Se è troppo breve, si ha un overhead elevato per i frequenti cambi di contesto.
4. Priority Scheduling:
Descrizione: Ad ogni processo viene assegnata una priorità, e la CPU viene assegnata al processo con la priorità più alta. In caso di parità di priorità, si può usare un altro criterio, come l’FCFS.
Vantaggi: Può essere utilizzato per dare la precedenza a processi importanti.
Svantaggi: Può causare starvation per i processi con priorità bassa, che potrebbero attendere a lungo prima di essere eseguiti. Il problema può essere risolto con tecniche di aging, che aumentano la priorità di un processo man mano che rimane in attesa.
5. Multilevel Queue Scheduling:
Descrizione: I processi vengono suddivisi in più code, ciascuna con una diversa priorità (ad esempio, processi interattivi in una coda e processi batch in un’altra). Ogni coda può avere il proprio algoritmo di schedulazione.
Vantaggi: Permette di gestire diversi tipi di processi in modo efficace.
Svantaggi: La separazione rigida tra code può causare squilibri nel carico della CPU.
6. Multilevel Feedback Queue Scheduling:
Descrizione: Simile al multilevel queue, ma i processi possono “scendere” o “salire” da una coda all’altra in base al loro comportamento (es. se un processo usa troppo la CPU, può essere spostato in una coda a priorità inferiore).
Vantaggi: Più flessibile rispetto al multilevel queue, permette di adattare la schedulazione alle caratteristiche di esecuzione dei processi.
Svantaggi: Può essere complesso da implementare e configurare correttamente.
Ogni PCB ha dei puntatori, per cui il context switch si fa spostando questi puntatori.
cambiare schema
linklinklink
5. Segnali (Signals)
I segnali sono un metodo per inviare notifiche asincrone a un processo. Un processo può ricevere segnali che indicano la necessità di eseguire qualche azione (es. terminazione, interruzione).
Esempi: kill(), signal().
6. Semafori (Semaphores)
I semafori sono variabili che vengono utilizzate per gestire l’accesso concorrente alle risorse condivise, come la memoria condivisa. Aiutano a evitare situazioni come il race condition.
Esempi: semget(), semop().
7. File temporanei
I file temporanei possono essere usati per lo scambio di dati tra processi. I dati vengono scritti su file e letti da altri processi.
9. Database e Sistemi di File
Un processo può scrivere dati in un database o file, e un altro processo può leggerli. Questo metodo è meno efficiente rispetto ad altri, ma può essere utile per la persistenza e condivisione di grandi quantità di dati.
6. Coordinamento e sincronizzazione tra processi
Nei sistemi con processi concorrenti, è necessario coordinare l’esecuzione di più processi per evitare problemi come race conditions (condizioni di corsa) o deadlock (stallo). Le operazioni per la sincronizzazione includono:
Mutua esclusione: Garantisce che un solo processo possa accedere a una risorsa condivisa alla volta (utilizzando semafori o mutex).
Semafori: I semafori sono variabili utilizzate per controllare l’accesso a risorse condivise, permettendo ai processi di attendere in modo sicuro l’accesso a una risorsa.
Monitor: I monitor sono costrutti di alto livello per gestire la mutua esclusione e la sincronizzazione dei processi.
7. Forking e clonazione di processi
Alcuni sistemi operativi (come Unix/Linux) permettono a un processo di creare una copia di se stesso tramite l’operazione di fork. Il processo figlio risultante è una replica del processo padre, con la stessa memoria, ma con un diverso PID.
8. Gestione dei segnali (Signals)
I processi possono inviare e ricevere segnali, che sono notifiche asincrone inviate dal sistema operativo o da altri processi per segnalare eventi come errori, richieste di terminazione o altri eventi specifici. Ad esempio, in Unix/Linux, il comando kill invia segnali a un processo (ad esempio, SIGTERM per richiedere la terminazione del processo).
9. Esecuzione di processi in foreground e background
Nei sistemi multiutente, è possibile eseguire un processo in foreground (in primo piano) o in background (sullo sfondo). Un processo in background può continuare a essere eseguito mentre l’utente esegue altre attività.
link linklink
ATTENZIONE: DA NON CONFONDERE CON PARALLELISMO O MULTITHREADING
errno è una variabile globale definita nella libreria <errno.h> che viene impostata dalle chiamate di sistema e dalle funzioni della libreria standard per segnalare un errore. Non viene mai azzerata automaticamente, quindi il suo valore è significativo solo dopo che una funzione segnala un errore (ad esempio restituendo -1 o NULL).
7.2 - Dove si trova errno?
errno è definita in <errno.h>, quindi per usarla bisogna includere questa libreria:
#include <errno.h>
È una variabile globale ma thread-local, il che significa che ogni thread ha la propria copia di errno.
7.3 - Come funziona errno?
Quando una funzione di sistema fallisce, imposta errno con un codice d’errore specifico.
L’utente può controllare errno subito dopo l’errore per capire cosa è andato storto.
Se una funzione ha successo, il valore di errno non viene modificato.
🏫 Lezioni e slide del Prof. Aldinucci Marco del corso di Sistemi Operativi (canale B), Corso di Laurea in Informatica presso l’Università di Torino, A.A. 2024-25:
🏫 Lezioni e slide del Prof. Schifanella Claudio del corso di Laboratorio di Sistemi Operativi (canale B, turno T4), Corso di Laurea in Informatica presso l’Università di Torino, A.A. 2024-25:
🏫 Appunti di Carlos Palomino del corso di Sistemi Operativi, Corso di Laurea in Informatica presso l’Università di Torino, A.A. 2024-25 (caricati sul repository GitHub del Team Studentesco Informatica):