Spesso, affidare a un unico processo la gestione di un’intera applicazione può risultare poco efficiente: un processo singolo, infatti, è costretto a eseguire in modo sequenziale tutte le attività, con il rischio di rimanere bloccato durante operazioni lente o di I/O, di non sfruttare appieno i sistemi multi-core e di rendere l’applicazione meno reattiva.
Per superare questi limiti, è possibile suddividere l’esecuzione in più flussi di controllo indipendenti ma cooperanti, detti thread, che condividono le risorse del processo e consentono un’esecuzione concorrente più efficiente. Alcuni esempi di applicazioni che s fruttano più thread sono i seguenti:
- Un’applicazione e che crea miniature di foto (thumbnails) da una raccolta di immagini può utilizzare un thread distinto per generare una miniatura di ciascuna immagine.
- Un web browser può avere un thread per rappresentare sullo schermo immagini e testo e un altro thread per scaricare i dati dalla rete.
- Un word processor può avere un thread per la rappresentazione grafica, uno per la risposta all’input da tastiera e uno per la correzione ortografica e grammaticale eseguita in background.
In realtà, al posto di usare i thread, si potrebbero anche usare più processi nella stessa applicazione e affidare a ognuno di loro un compito, ma ciò è poco efficiente perché i thread sono in grado di condividere memoria e altre risorse, mentre per i processi c’è molto più overhead.
Processi sono heavy-weight, thread sono light-weight.
Kernel, applicazioni moderne, tutto è generalmente multithreaded oggi.
Definizione: thread
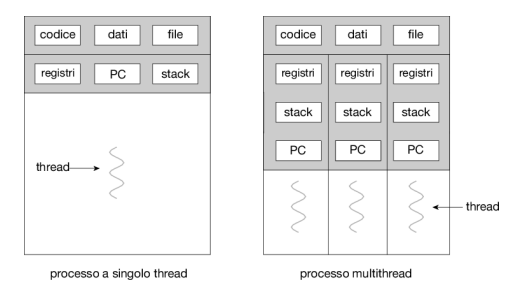
Un thread (abbreviazione di thread of execution, in italiano filo dell’esecuzione) è l’unità granulare in cui un processo può essere suddiviso e che può essere eseguito a divisione di tempo (cioè assegnando a ognuno una determinata porzione di tempo in cui poter essere eseguito) o in parallelo ad altri thread da parte del processore. Può essere eseguito a livello utente o a livello kernel.
Contesto del thread:
- Identificatore del thread (TID)
- Contatore del programma (PC)
- Insieme di registri
- Pila di memoria (stack)
Condivide con gli altri thread dello stesso processo la sezione del codice, dei dati e altre risorse di sistema, come i file aperti e i segnali.
Un processo tradizionale, chiamato anche processo pesante (heavyweight process), è composto da un solo thread. Un processo multithread è in grado di svolgere più compiti in modo concorrente. La Figura 4.1 mostra la differenza tra un processo tradizionale, a singolo thread, e uno multithread.
Kernel multithreaded: La maggior parte dei kernel dei sistemi operativi è multithread. Per esempio, durante l’avvio del sistema Linux vengono creati diversi thread a livello kernel e ogni thread esegue un’attività specifica, per esempio la gestione dei dispositivi, della memoria o delle interruzioni. Su un sistema Linux in esecuzione si può usare il comando ps -ef per visualizzare i thread a livello kernel. Esaminando l’output di questo comando si può notare il thread kthreadd (con pid = 2), che funge da genitore di tutti gli altri thread a livello kernel.
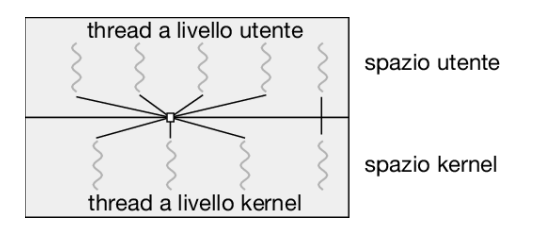
Thread a livello utente e a livello kernel
Definizione: thread a livello utente
Definizione: thread a livello kernel
Un thread si dice che è a livello kernel quando viene gestito unicamente dal sistema operativo e, in particolare, dal kernel.
1 - Differenza tra processo e thread
I termini processo e thread, nonostante a volte vengano usati in maniera interscambiabile, in realtà indicano due cose distinte:
- Un processo è un’istanza di un programma in esecuzione, con risorse e uno spazio di memoria proprio. Ogni processo è indipendente dagli altri e dispone di un proprio spazio di indirizzamento nella memoria, il che significa che i dati di un processo non sono condivisibili direttamente con quelli di un altro processo (salvo meccanismi appositi, come la memoria condivisa o la comunicazione inter-processo).
- Un thread è un’unità di esecuzione all’interno di un processo. Tutti i thread di un processo condividono lo stesso spazio di memoria e le stesse risorse del processo che li contiene. Un singolo processo può avere uno o più thread (concetto di multithreading).
Il termine inglese thread rende bene l’idea, in quanto si rifà visivamente al concetto di fune metallica composta da vari fili attorcigliati: se la fune è il processo in esecuzione, allora i singoli fili che la compongono sono i thread.

1.1 - Esempio pratico
Ecco un esempio pratico della differenza tra processo e thread.
Immagina di avviare un’applicazione come, per esempio, un editor di testo. Quando l’applicazione viene avviata, il sistema operativo crea un processo con il suo spazio di memoria. Se apri una seconda istanza dell’editor, viene creato un nuovo processo.
All’interno dell’editor di testo, ci possono essere più thread: uno che gestisce la visualizzazione del testo, un altro che gestisce il salvataggio automatico, e un altro che risponde ai comandi dell’utente. Tutti questi thread lavorano contemporaneamente e condividono lo stesso spazio di memoria, consentendo un’esecuzione fluida e parallela delle operazioni.
1.2 - Tabella riassuntiva delle differenze
Ecco una tabella riassuntiva delle differenze tra processo e thread:
| Caratteristica | Processo | Thread |
|---|---|---|
| Spazio di memoria | Ha uno spazio di memoria separato | Condivide lo spazio di memoria con altri thread del processo |
| Isolamento | Isolato da altri processi | Condivide le risorse con altri thread nel processo |
| Comunicazione | Comunicazione tra processi complessa | Comunicazione interna tra thread più semplice |
| Esecuzione | Un processo può avere uno o più thread, eseguiti separatamente | Ogni thread è un’unità di esecuzione all’interno di un processo |
| Crashing | Se un processo va in crash, non influenza altri processi | Se un thread va in crash, può compromettere l’intero processo |
| Cambi di contesto | Richiede un cambio di contesto completo (salvataggio di registri, memoria, ecc.) | Il cambio di contesto tra thread è più rapido poiché condividono memoria e risorse |
2 - Vantaggi e svantaggi dei thread
I principali vantaggi dei thread sono:
- Parallelismo: i thread permettono di eseguire compiti contemporaneamente, sfruttando al meglio i processori multicore, il che riduce i tempi di elaborazione per compiti intensivi.
- Reattività: nei programmi con interfaccia utente, i thread aiutano a mantenere il programma reattivo, separando i compiti di elaborazione in background dalle operazioni principali (come la gestione dell’interfaccia grafica).
- Condivisione delle risorse: i thread condividono risorse del processo, rendendo la comunicazione tra di loro più immediata rispetto a meccanismi di IPC a livello di processi (molto più lenti)
- Efficienza nella gestione della memoria: i thread condividono la memoria e le risorse del processo principale, il che riduce la duplicazione e l’uso della memoria rispetto ai processi separati.
- Minore overhead: i thread richiedono meno risorse per essere creati rispetto ai processi, poiché condividono risorse e spazio di indirizzamento del processo che li ha generati.
- Comunicazione più semplice: condividendo la memoria, i thread possono comunicare tra loro più facilmente, evitando le complessità dei canali di comunicazione tra processi separati.
- Scalabilità: un processo può sfruttare le architetture dei multiprocessori per creare un numero di thread adatto
I vantaggi della programmazione multithread si possono classificare in quattro categorie principali.
- Tempo di risposta. Rendere multithread un’applicazione interattiva può permettere a un programma di continuare la sua esecuzione, anche se una parte di esso è bloccata o sta eseguendo un’operazione particolarmente lunga, riducendo il tempo di risposta all’utente. Questa caratteristica è particolarmente utile nella progettazione di interfacce utente. Per esempio, si consideri quello che succede quando un utente fa clic su un pulsante che provoca l’esecuzione di un’operazione che richieda diverso tempo. Un’applicazione a thread singolo resterebbe bloccata fino al completamento dell’operazione. Al contrario, se l’operazione viene eseguita in un thread separato, l’applicazione rimane attiva per l’utente.
- Condivisione delle risorse. I processi possono condividere risorse soltanto attraverso tecniche come la memoria condivisa e lo scambio di messaggi. Queste tecniche devono essere esplicitamente messe in atto dal programmatore. Tuttavia, i thread condividono per default la memoria e le risorse del processo al quale appartengono. Il vantaggio della condivisione del codice e dei dati consiste nel fatto che un’applicazione può avere molti thread di attività diverse, tutti nello stesso spazio d’indirizzi.
- Economia. Assegnare memoria e risorse per la creazione di nuovi processi è costoso; poiché i thread condividono le risorse del processo cui appartengono, è molto più conveniente creare thread e gestirne i cambi di contesto. È difficile misurare empiricamente la differenza nell’overhead richiesto per creare e gestire un processo invece che un thread, tuttavia la creazione dei thread richiede in generale meno tempo e meno memoria, e il cambio di contesto tra thread è più rapido.
- Scalabilità. I vantaggi della programmazione multithread sono ancora maggiori nelle architetture multiprocessore, dove i thread si possono eseguire in parallelo su distinti core di elaborazione. Invece un processo con un singolo thread può funzionare solo su un processore, indipendentemente da quanti ve ne siano a disposizione. Il multithreading su una macchina con più processori incrementa il parallelismo. Esploreremo questo tema nel prossimo paragrafo.
I principali svantaggi dei thread sono:
- Complessità nella programmazione: la programmazione multithreading può essere complessa, specialmente per la gestione della sincronizzazione tra thread, aumentando il rischio di errori come race conditions e deadlock.
- Sincronizzazione dei dati: poiché i thread condividono la memoria, devono sincronizzare l’accesso ai dati condivisi per evitare conflitti e incoerenze, il che può risultare difficile da gestire.
- Debug difficile: identificare e risolvere i problemi nei programmi multithreading può essere complesso, soprattutto quando si tratta di bug non deterministici che si verificano solo in determinate condizioni.
- Scalabilità limitata: anche se i thread migliorano le prestazioni su CPU multicore, non tutti i problemi possono essere parallelizzati, e oltre un certo limite i benefici si riducono.
- Rischio di deadlock e starvation: se i thread non sono ben gestiti, possono bloccarsi in uno stato di attesa reciproca (deadlock) o essere “affamati” di risorse, restando bloccati e incapaci di completare il loro compito (starvation).
3 - Multithreading
Definizione: multithreading
Il multithreading è la capacità di un sistema operativo di eseguire più thread simultaneamente.
Il multithreading può essere implementato secondo diversi modelli:
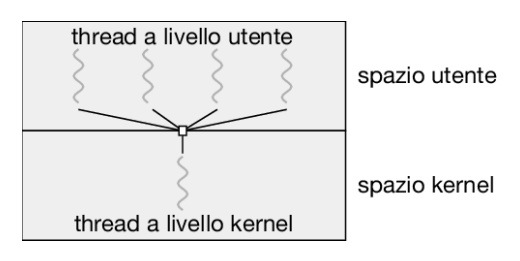
- Molti a uno: molti thread a livello utente sono mappati in un solo thread a livello kernel. Ciò implica che il blocco di un thread causa il blocco di tutti gli altri. Inoltre, poiché un solo thread alla volta può accedere al kernel, è impossibile eseguire thread multipli in parallelo in sistemi multicore. Pochi sistemi operativi utilizzano questo modello, come Solaris Green Threads o GNU Portable Threads. Tuttavia, pochissimi sistemi utilizzano ancora questo modello a causa della sua incapacità di trarre vantaggio dalla presenza di più core (che costituisco lo standard nei sistemi elaborativi moderni).
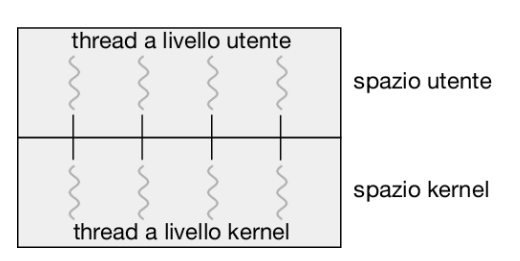
- Uno a uno: ogni thread a livello utente viene mappato in un thread a livello kernel. Ciò implica una concorrenza maggiore rispetto al modello molti a uno,e, poiché anche se un thread invoca una chiamata di sistema bloccante, è possibile eseguire un altro thread. L’unico svantaggio di questo modello è che la creazione di ogni thread a livello utente comporta la creazione del corrispondente thread a livello kernel. Poiché il carico dovuto alla creazione di un thread a livello kernel può sovraccaricare le prestazioni di un’applicazione, la maggior parte delle realizzazioni di questo modello limita il numero di thread supportabili dal sistema. Esempi di sistemi operativi che utilizzano questo modello sono Windows, Linux e Solaris (dalla versione 9 in poi).
- Molti a molti: molti thread a livello utente sono mappati in molti thread a livello kernel. Ciò permette al sistema operativo di creare un numero sufficiente di thread a livello kernel. Consideriamo l’effetto di questo modello sulla concorrenza. Nonostante il modello da molti a uno permetta ai programmatori di creare tanti thread a livello utente quanti ne desiderino, non viene garantita una concorrenza reale, poiché il meccanismo di scheduling del kernel può scegliere un solo thread alla volta. Il modello da uno a uno permette una maggiore concorrenza, ma i programmatori devono stare attenti a non creare troppi thread all’interno di un’applicazione (in qualche caso si possono avere limitazioni sul numero di thread che si possono creare). Il modello da molti a molti non ha alcuno di questi difetti: i programmatori possono creare liberamente i thread che ritengono necessari e i corrispondenti thread a livello kernel si possono eseguire in parallelo nelle architetture multiprocessore. Inoltre, se un thread impiega una chiamata di sistema bloccante, il kernel può schedulare un altro thread. Esempi di sistemi operativi che utilizzano questo modello sono Windows con il package ThreadFiber e Solaris (prima della versione 9).
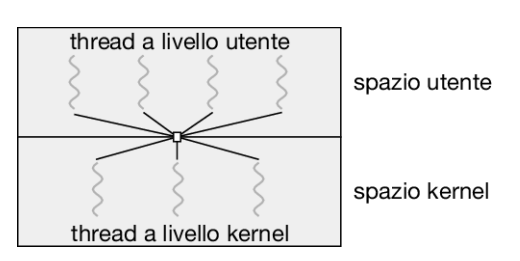 Una variante del modello da molti a molti mantiene la corrispondenza fra più thread utente e un numero minore o uguale di thread del kernel, ma permette anche di vincolare un thread utente a un solo thread del kernel. Questa variante è anche chiamata modello a due livelli (Figura 4.10).
Una variante del modello da molti a molti mantiene la corrispondenza fra più thread utente e un numero minore o uguale di thread del kernel, ma permette anche di vincolare un thread utente a un solo thread del kernel. Questa variante è anche chiamata modello a due livelli (Figura 4.10).- Due livelli: misto tra molti-a-molti e uno-a-uno
Anche se il modello da molti a molti sembra essere il più flessibile tra quelli trattati è difficile metterlo in atto nella pratica. Inoltre, con un numero sempre crescente di core di elaborazione presenti nella maggior parte dei sistemi, la limitazione del numero di thread a livello kernel è diventata meno importante e, di conseguenza, la maggior parte dei sistemi operativi utilizza ora il modello da uno a uno. Tuttavia, alcune librerie per la concorrenza richiedono agli sviluppatori di identificare i task che vengono poi mappati sui thread usando il modello da molti a molti
Thread asincrono e sincrono
Prima di procedere con i nostri esempi di creazione di thread, introduciamo due strategie generali per la creazione di più thread: il threading asincrono e il threading sincrono. Nel threading asincrono, una volta che il genitore crea un thread figlio, riprende la sua esecuzione, in modo che genitore e figlio restino in esecuzione concorrentemente. Ogni thread viene eseguito in modo indipendente rispetto agli altri thread e il thread genitore non ha bisogno di conoscere quando suo figlio termina. Poiché i thread sono indipendenti, vi è di solito poca condivisione dei dati tra i thread. Il threading asincrono è la strategia utilizzata nel server multithread illustrato nella Figura 4.2 ed è anche comunemente utilizzato per il progetto di interfacce utente reattive (responsive).
Il threading sincrono si verifica quando il thread genitore crea uno o più figli e attende che tutti terminino prima di riprendere l’esecuzione. Tale strategia è detta fork-join. In questo caso, i thread creati dal genitore svolgono il lavoro in maniera concorrente, ma il genitore non può continuare fino al completamento di questo lavoro. Una volta che un thread ha completato il suo lavoro esso termina e si unisce (join) con il genitore. Solo dopo che tutti i figli si sono uniti al genitore, questo può riprendere l’esecuzione. In genere, il threading sincrono comporta una significativa condivisione dei dati tra i thread. Per esempio, il thread genitore può combinare i risultati calcolati dai suoi figli. Tutti i seguenti esempi utilizzano il threading sincrono
Librerie dei thread
Le librerie dei thread offrono al programmatore un’API per creare e gestire thread. I metodi con cui implementare una libreria dei thread sono essenzialmente due:
- Nel primo, la libreria è collocata interamente a livello utente, senza fare ricorso al kernel. Il codice e le strutture dati per la libreria risiedono tutti nello spazio utente. Questo implica che invocare una funzione della libreria si traduce in una chiamata locale a una funzione nello spazio utente e non in una chiamata di sistema.
- Il secondo metodo consiste nell’implementare una libreria a livello kernel, supportata direttamente del sistema operativo. In questo caso, il codice e le strutture dati per la libreria si trovano nello spazio del kernel. Invocare una funzione della api per la libreria provoca, generalmente, una chiamata di sistema al kernel.
Attualmente, sono tre le librerie di thread maggiormente in uso: Pthreads di posix, Windows e Java.
Nel threading di posix e di Windows tutti i dati dichiarati a livello globale, ovvero al di fuori di ogni funzione, sono condivisi tra tutti i thread appartenenti allo stesso processo. Poiché Java non ha alcuna nozione di dati globali, l’accesso ai dati condivisi deve essere assegnato in modo esplicito tra i thread. I dati locali di una funzione sono in genere memorizzati nello stack. Dal momento che ogni thread ha un proprio stack, ogni thread ha la propria copia di dati locali.
Pthreads
Pthreads, estensione dello standard posix, può essere realizzata sia come libreria a livello utente sia a livello kernel
Col termine Pthreads ci si riferisce allo standard posix (ieee 1003.1c) che definisce una api per la creazione e la sincronizzazione dei thread. Non si tratta di una implementazione, ma di una specifica del comportamento dei thread; i progettisti di sistemi operativi possono realizzare la specifica come meglio credono. Sono molti i sistemi che implementano le specifiche Pthreads; per la maggior parte si tratta di sistemi di tipo unix, tra cui Linux e macos. Anche se Windows non supporta nativamente Pthreads, sono disponibili alcune implementazioni di terze parti per Windows.
API specifies behavior of the thread library, implementation is up to development of the library
Common in UNIX operating systems (Solaris, Linux, Mac OS X)
Windows
La libreria di thread Windows è una libreria a livello kernel per i sistemi Windows
La tecnica usata dalla libreria Windows per la creazione dei thread può richiamare, per molti versi, quella di Pthreads
Nella api Windows i nuovi thread si generano tramite la funzione CreateThread(), che – proprio come in Pthreads – accetta una serie di attributi del thread come parametri. Tali attributi includono le informazioni sulla sicurezza, la dimensione dello stack e un indicatore (flag) per segnalare se il thread debba avere inizio nello stato d’attesa. Come si ricorderà, nel programma Pthread (Figura 4.11) il thread iniziale era posto in attesa della terminazione del nuovo thread tramite la funzione pthread_join(). La chiamata equivalente nella api Windows è WaitForSingleObject(), che causa la sospensione del thread iniziale fintanto che il nuovo thread non abbia terminato.
In situazioni che richiedono l’attesa della terminazione di più thread viene utilizzata la funzione WaitForMultipleObjects(), alla quale vengono passati quattro parametri:
- il numero di oggetti da attendere;
- un puntatore al vettore di oggetti;
- un flag che indica se tutti gli oggetti sono stati segnalati;
- la durata del timeout (o il valore INFINITE).
Per esempio, se THandles è un array di HANDLE di thread di dimensione N, il thread principale può attendere che tutti i suoi figli terminino con la seguente istruzione: WaitForMultipleObjects(N, THandles, TRUE, INFINITE);
Java Threads
La api per la creazione dei thread in Java è gestibile direttamente dai programmi Java. Tuttavia, data la peculiarità di funzionamento della jvm, quasi sempre eseguita sopra un sistema operativo che la ospita, la api di Java per i thread è solitamente implementata per mezzo di una libreria dei thread del sistema ospitante. Perciò, i thread di Java sui sistemi Windows sono in effetti implementati mediante la api Windows; sui sistemi unix e Linux, invece, si adopera spesso Pthreads.
I thread rappresentano il paradigma fondamentale per l’esecuzione dei programmi in ambiente Java; il linguaggio Java, con la propria api, è provvisto di una ricca gamma di funzionalità per la generazione e la gestione dei thread. Tutti i programmi scritti in Java incorporano almeno un thread di controllo – persino un semplice programma, costituito soltanto da un metodo main(), è eseguito dalla jvm come un singolo thread. I thread Java sono disponibili su tutti i sistemi che dispongono di una jvm, tra cui Windows, Linux e macos. L’api Java per i thread è anche disponibile per le applicazioni Android.
In un programma Java vi sono due tecniche per la generazione dei thread:
- Una è creare una nuova classe derivata dalla classe Thread e “sovrascrivere” (override) il suo metodo run()
- L’alternativa, usata più comunemente, consiste nella definizione di una classe che implementi l’interfaccia Runnable. Questa interfaccia definisce un singolo metodo astratto con segnatura public void run(). Il codice nel metodo run() di una classe che implementa Runnable sarà eseguito in un thread distinto
L’invocazione del metodo start() del nuovo oggetto Thread ha il duplice effetto di:
- allocare la memoria e inizializzare un nuovo thread nella jvm;
- chiamare il metodo run(), cosa che rende il thread eseguibile dalla jvm. Si osservi come il metodo run() non sia mai chiamato per via diretta, ma solo tramite la chiamata del metodo start().
Ricordiamo che i thread genitori nelle librerie Pthreads e Windows usano, rispettivamente, phtread_join() e WaitForSingleObject() per attendere la conclusione del thread che esegue la somma prima di procedere. Il metodo join() in Java fornisce una simile funzionalità. (Si noti che join() può sollevare una InterruptedException, che nel codice abbiamo deciso di non gestire).
Espressioni lambda in Java
A partire dalla versione 1.8 del linguaggio, Java ha introdotto le espressioni Lambda, che forniscono una sintassi molto più pulita per la creazione di thread. Piuttosto che definire una classe separata che implementa Runnable, è possibile utilizzare un’espressione Lambda:
Runnable task = () -> {
System.out.println(“I am a thread.”);
};
Thread worker = new Thread(task);
worker.start();
Le espressioni Lambda, così come funzioni simili chiamate chiusure (closure), sono una delle principali caratteristiche dei linguaggi di programmazione funzionale e sono state rese disponibili in diversi linguaggi non funzionali, compresi Python, C++ e C#. Come vedremo negli esempi successivi di questo capitolo, le espressioni Lambda permettono in molti casi di scrivere applicazioni parallele con una sintassi semplice.
Java Executor
Java ha supportato la creazione di thread mediante l’approccio che abbiamo descritto finora sin dalle sue origini. Tuttavia, a partire dalla versione 1.5 e dalla relativa api, Java ha introdotto diverse nuove funzionalità per la concorrenza che forniscono agli sviluppatori un controllo superiore sulla creazione di thread e sulla loro comunicazione. Questi strumenti sono disponibili nel package java.util.concurrent. Piuttosto che creare esplicitamente oggetti Thread, la creazione del thread è ora organizzata attorno all’interfaccia Executor:
public interface Executor {
void execute(Runnable command);
}
Le classi che implementano questa interfaccia devono definire il metodo execute(), passato a un oggetto Runnable. Gli sviluppatori Java, invece di creare un oggetto Thread distinto e richiamare il suo metodo start(), possono utilizzare Executor, come segue:
Executor service = new Executor;
service.execute(new Task());
L’ambiente Executor si basa sul modello produttore-consumatore; vengono generati task che implementano l’interfaccia Runnable e i thread che eseguono questi task li consumano. Il vantaggio di questo approccio è che non solo separa la creazione del thread dalla sua esecuzione, ma fornisce anche un meccanismo per la comunicazione tra task concorrenti.
La condivisione dei dati tra thread appartenenti allo stesso processo avviene facilmente in Windows e Pthreads, poiché i dati condivisi vengono semplicemente dichiarati globalmente. Essendo un linguaggio puramente orientato agli oggetti, Java non possiede una tale nozione di dato globale e, sebbene sia possibile passare parametri a una classe che implementa Runnable, i thread Java non possono restituire risultati. Per soddisfare questa esigenza, il package java.util.concurrent definisce l’interfaccia Callable, che si comporta in modo simile a Runnable tranne per il fatto che è possibile restituire un risultato. I risultati restituiti dai task Callable sono noti come oggetti Future. Un risultato può essere recuperato con il metodo get() definito nell’interfaccia Future. Il programma mostrato nella Figura 4.14 illustra il calcolo di una sommatoria utilizzando queste funzionalità Java.
La JVM e il sistema operativo ospite
La macchina virtuale del linguaggio Java (jvm) è solitamente implementata sulla base di un sistema operativo sottostante (Figura 18.10). Questo assetto permette alla jvm di nascondere i dettagli del sistema operativo e di offrire un ambiente astratto e coerente che consente ai programmi scritti in Java di essere eseguiti su qualsiasi piattaforma che disponga di una jvm. Le specifiche della jvm non prescrivono come i thread Java debbano corrispondere ai servizi del sistema operativo sottostante, lasciando i dettagli all’implementazione. Il sistema operativo Windows, per esempio, adotta il modello da uno a uno; perciò, ogni thread Java di una jvm installata su questo sistema corrisponde a un thread a livello kernel. Oltre a ciò, può esistere una relazione tra la libreria dei thread di Java e la libreria dei thread del sistema operativo residente. Le varie versioni della jvm per la famiglia di sistemi operativi Windows, per esempio, potrebbero ricorrere alla api Windows al fine di implementare i thread di Java; i sistemi Linux e macos potrebbero impiegare la api Pthreads.
Threading implicito
Con la continua crescita di elaborazione multicore si profilano all’orizzonte applicazioni contenenti centinaia, o anche migliaia, di thread. La progettazione di tali applicazioni non è un’impresa semplice. Un modo per affrontare tali ostacoli e gestire al meglio la progettazione di applicazioni parallele e concorrenti è il trasferimento della creazione e della gestione del threading dagli sviluppatori di applicazioni ai compilatori e alle librerie di runtime. La correttezza dei programmi può diventare difficile da gestire con thread gestiti “manualmente” (esplicitamente) → lasciamo fare i thread ai compilatori e le librerie di run-time piuttosto che ai compilatori.
Questa strategia, chiamata threading implicito, è diventata oggi molto comune. In questo paragrafo esploriamo tre approcci alternativi per la progettazione di programmi multithread in grado di sfruttare i processori multicore attraverso il threading implicito. Come vedremo, queste strategie richiedono in genere agli sviluppatori di applicazioni di identificare task, e non thread, che possano essere eseguiti in parallelo. Un task viene solitamente codificato come una funzione, che viene mappata dalla libreria di runtime su un thread separato, in genere utilizzando il modello da molti a molti (Paragrafo 4.3.3). Il vantaggio di questo approccio è che gli sviluppatori devono solo individuare i task parallelizzabili, mentre le librerie determinano i dettagli specifici della creazione e della gestione dei thread.
Tre metodi principali:
- Gruppi di thread (thread pools)
- OpenMP
- Grand Central Dispatch
Gruppi di thread (thread pools)
Nonostante la creazione di un thread distinto sia molto più vantaggiosa della creazione di un nuovo processo, tuttavia un server multithread presenta diversi problemi. Il primo riguarda il tempo richiesto per la creazione del thread prima di poter soddisfare la richiesta, considerando anche il fatto che questo thread sarà terminato non appena avrà completato il proprio lavoro. La seconda questione è più problematica: se si permette che tutte le richieste concorrenti siano servite da un nuovo thread, non si è posto un limite al numero di thread concorrentemente attivo nel sistema. Un numero illimitato di thread potrebbe esaurire le risorse del sistema, come il tempo di cpu o la memoria. L’impiego dei gruppi di thread (thread pool) è una possibile soluzione a questo problema.
L’idea generale è quella di creare un certo numero di thread alla creazione del processo e organizzarlo in un gruppo (pool) in cui attenda di eseguire il lavoro che gli sarà richiesto. Quando un server riceve una richiesta, attiva un thread del gruppo – se ce n’è uno disponibile – e gli passa la richiesta; dopo aver completato il suo lavoro, il thread rientra nel gruppo d’attesa. I gruppi di thread funzionano bene quando i task possono essere eseguiti in maniera asincrona.
I vantaggi sono i seguenti:
- il servizio di una richiesta tramite un thread esistente è più rapido dell’attesa della creazione di un nuovo thread;
- un gruppo di thread limita il numero di thread esistenti a un certo istante; ciò è particolarmente rilevante per sistemi che non possono sostenere un elevato numero di thread concorrenti;
- separare il task da svolgere dalla meccanica della sua creazione ci permette di utilizzare diverse strategie per l’esecuzione di tale task. Per esempio, si potrebbe pianificare l’esecuzione del task dopo un ritardo di tempo o periodicamente.
Il numero di thread di un gruppo si può determinare tramite euristiche che considerano fattori come il numero di cpu nel sistema, la quantità di memoria fisica e il numero atteso di richieste concorrenti da parte dei client. Architetture più raffinate per la gestione dei gruppi di thread possono correggere dinamicamente il numero di thread di un gruppo secondo l’utilizzazione del sistema. Queste architetture hanno l’ulteriore vantaggio di utilizzare gruppi più piccoli – comportando quindi un minore impegno di memoria – quando il carico del sistema è basso. Introdurremo una di queste architetture, Grand Central Dispatch di Apple, nei prossimi paragrafi.
Thread pool in Java
Il pacchetto java.util.concurrent include un’api per diverse varietà architetturali di gruppi di thread. Ci concentreremo sui seguenti tre modelli:
- Single thread executor—newSingleThreadExecutor(): crea un gruppo di dimensione 1.
- Fixed thread executor—newFixedThreadPool(int size): crea un gruppo con un numero specificato di thread.
- Cached thread executor—newCachedThreadPool(): crea un gruppo di thread illimitato, riutilizzando i thread in esecuzioni successive.
Un gruppo di thread viene creato utilizzando uno dei metodi factory della classe Executors: static ExecutorService newSingleThreadExecutor() static ExecutorService newFixedThreadPool(int size) static ExecutorService newCachedThreadPool()
Ciascuno di questi metodi crea e restituisce un’istanza dell’oggetto che implementa l’interfaccia ExecutorService. ExecutorService estende l’interfaccia di Executor, permettendoci di invocare il metodo execute() su questo oggetto. Inoltre, ExecutorService fornisce metodi per la gestione della terminazione del gruppo di thread.
Fork join
Secondo la strategia di creazione dei thread “fork-join”, il thread padre crea (fork) uno o più thread figli, attende che i figli terminino e si uniscano a esso (join) e a quel punto può recuperare e combinare i risultati ottenuti dai figli. Questo modello sincrono è spesso indicato come uno strumento per la creazione esplicita di thread, ma è anche un eccellente candidato per il threading implicito. In quest’ultima situazione, i thread non sono costruiti direttamente durante la fase di fork; piuttosto, occorre definire task paralleli. Una libreria gestisce il numero di thread che vengono creati ed è responsabile dell’assegnazione dei task ai thread. In un certo senso, questo modello fork-join è una versione sincrona di un thread pool in cui una libreria determina il numero effettivo di thread da creare.
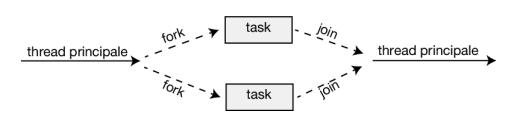
Fork join in Java
Java ha introdotto una libreria fork-join nella versione 1.7 dell’api, progettata per essere utilizzata con algoritmi ricorsivi divide et impera come Quicksort e Mergesort. Quando si implementano algoritmi divide et impera mediante questa libreria, differenti task vengono diramati (fork) durante il passo ricorsivo e vengono assegnati a sottoinsiemi più piccoli del problema originale. Gli algoritmi devono essere progettati in modo che questi task separati possano essere eseguiti contemporaneamente. A un certo punto, la dimensione del problema assegnato a un task è abbastanza piccola da poter essere risolta direttamente senza richiedere la creazione di nuovi task.
Un aspetto importante da tenere in considerazione è determinare quando il problema è “abbastanza piccolo” da poter essere risolto direttamente, senza necessità di creare ulteriori task. Nella pratica, per determinare quando un problema può essere risolto direttamente occorre eseguire attenti cronometraggi, poiché il valore può variare in base all’implementazione
Ciò che è interessante nel modello fork-join di Java è la gestione dei task, dove la libreria costruisce un gruppo di thread di lavoro e bilancia il carico dei task tra i thread disponibili. In alcune situazioni ci sono migliaia di task, ma solo una manciata di thread esegue il lavoro (per esempio, un thread distinto per ogni cpu). Inoltre, ogni thread in ForkJoinPool mantiene una coda dei task che ha generato; se la coda di un thread è vuota, il thread può “rubare” un’attività dalla coda di un altro thread usando un algoritmo detto di work stealing e bilanciando così il carico di lavoro tra tutti i thread.
OpenMP
- OpenMP: insieme di direttive del compilatore e un’API per C, C++, FORTRAN. Permette supporto per programmazione parallela in ambienti a memoria condivisa.
Openmp definisce le regioni parallele come blocchi di codice eseguibili in parallelo. Gli sviluppatori di applicazioni inseriscono direttive del compilatore nei punti del codice dove vi sono regioni parallele e queste direttive istruiscono la libreria di runtime Openmp per l’esecuzione della regione in parallelo.
Quando Openmp incontra la direttiva
# pragma omp parallel
crea tanti thread quanti sono i core di elaborazione del sistema. In questo modo, in un sistema dual-core vengono creati due thread, in un sistema quad-core quattro thread, e così via. Tutti i thread eseguono poi contemporaneamente la regione parallela. Quando un thread esce dalla regione parallela viene terminato.
Openmp fornisce diverse direttive aggiuntive per l’esecuzione di porzioni di codice in parallelo, tra cui i cicli parallelizzati. Per esempio, supponiamo di avere due array a e b di dimensione N. Desideriamo sommare i valori in essi contenuti e inserire i risultati nell’array c. Possiamo eseguire questo task in parallelo utilizzando il seguente frammento di codice, contenente la direttiva del compilatore per parallelizzare i cicli for:
#pragma omp parallel for
for (i = 0; i < N; i++) {
c[i] = a[i] + b[i];
}
Openmp divide il compito contenuto nel ciclo for fra i thread che ha creato in risposta alla direttiva:
# pragma omp parallel for
Oltre a fornire direttive per la parallelizzazione, Openmp consente agli sviluppatori di scegliere tra diversi livelli di parallelismo. Si può per esempio impostare manualmente il numero di thread o indicare se i dati sono condivisi tra i thread o sono riservati a un solo thread. Openmp è disponibile su diversi compilatori open-source e commerciali per sistemi Linux, Windows e macos. Esortiamo i lettori interessati a saperne di più su Openmp a consultare la bibliografia alla fine del capitolo.
Grand Central Dispatch (GCD)
Grand Central Dispatch (GCD), una tecnologia per i sistemi operativi macos e ios di Apple, è una combinazione di estensioni del linguaggio C, una api e una libreria di runtime che permette agli sviluppatori di applicazioni di individuare sezioni di codice da eseguire in parallelo. Come Openmp, gcd gestisce la maggior parte dei dettagli del threading.
GCD pianifica l’esecuzione runtime dei task inserendoli in una coda di dispacciamento (dispatch queue). Quando GCD rimuove un task dalla coda, lo assegna a un thread disponibile tra quelli presenti nel gruppo di thread che gestisce. GCD definisce due tipi di code di dispacciamento: seriali e concorrenti
- I task posti in una coda seriale vengono prelevati secondo un ordine fifo. Una volta che un task è stato rimosso dalla coda la sua esecuzione deve essere completata prima del prelievo di un altro task. Ogni processo ha una propria coda seriale, chiamata coda principale (main queue). Gli sviluppatori possono creare altre code seriali locali per processi particolari (questo è il motivo per cui le code seriali sono anche note come private dispatch queue, o code di dispacciamento private). Le code seriali sono utili per assicurare l’esecuzione sequenziale delle diverse attività.
- Anche i task posti in una coda concorrente vengono rimossi secondo un ordine fifo, ma è possibile prelevare più task alla volta, permettendo così la loro esecuzione in parallelo. Ci sono diverse code concorrenti a livello di sistema (note anche come global dispatch queues, o code di dispacciamento globali), suddivise in quattro classi principali in base alla qualità del servizio (qos):
- QOS_CLASS_USER_INTERACTIVE: la classe user-interactive rappresenta i task che interagiscono con l’utente, come l’interfaccia utente e la gestione degli eventi, per garantire un’interfaccia utente reattiva. Il completamento di un task appartenente a questa classe richiede di norma poco lavoro.
- QOS_CLASS_USER_INITIATED: la classe user-initiated è simile alla classe precedente, perché le attività sono associate a un’interfaccia utente reattiva; tuttavia, i task avviati dall’utente possono richiedere tempi di elaborazione più lunghi. Per esempio, l’apertura di un file o di un url è un task avviato dall’utente. I task di questa classe devono essere completati affinché l’utente possa continuare a interagire con il sistema, ma non è necessario servirli con la stessa tempestività dei task nella coda user-interactive.
- QOS_CLASS_UTILITY: La classe utility rappresenta i task che richiedono un tempo più lungo per essere completati, ma non richiedono risultati immediati. Questa classe include attività come l’importazione di dati.
- QOS_CLASS_BACKGROUND: i task appartenenti alla classe background non sono visibili all’utente e non sono sensibili al fattore tempo. Alcuni esempi sono l’indicizzazione di una casella di posta elettronica e l’esecuzione di un backup.
I task inviati alle code di dispacciamento possono essere espressi in due modi diversi.
- Nei linguaggi C, C++ e Objective-C, gcd definisce un’estensione del linguaggio nota come blocco. Un blocco è semplicemente un’unità di lavoro autocontenuta e viene specificato dal simbolo ^ inserito prima di una coppia di parentesi graffe {}. Il codice tra parentesi descrive l’attività da svolgere. Un semplice esempio di blocco è:
^{ printf ( “I am a block” ); } - Nel linguaggio di programmazione Swift, un task viene definito utilizzando una chiusura (closure), simile a un blocco, in quanto esprime un’unità autocontenuta di funzionalità. Sintatticamente, una chiusura Swift è scritta come un blocco, eccetto il simbolo ^ iniziale.
Internamente, il gruppo di thread di GCD è composto da thread posix. gcd gestisce attivamente il gruppo, consentendo al numero di thread di aumentare o diminuire in base alle richieste dell’applicazione e alla capacità del sistema. gcd è implementato dalla libreria libdispatch, che Apple ha rilasciato sotto licenza Apache Commons. In seguito ne è stato effettuato il porting su sistema operativo Freebsd.
Intel Thread Building Blocks
Intel threading building blocks (TBB) è una libreria di template che supporta la progettazione di applicazioni parallele in C++ e non richiede alcun compilatore o supporto linguistico speciale. Gli sviluppatori specificano i task che possono essere eseguiti in parallelo e il task scheduler di TBB mappa questi task sui thread sottostanti. Inoltre, il task scheduler fornisce il bilanciamento del carico ed è conscio della presenza della cache, ovvero darà la precedenza alle attività che più probabilmente avranno i loro dati memorizzati nella memoria cache e che quindi verranno eseguite più rapidamente.
tbb offre un ricco set di funzionalità, tra cui template per cicli paralleli, operazioni atomiche e lock mutex. Inoltre, fornisce strutture dati concorrenti, tra cui la mappa hash, la coda e il vettore, che possono fungere da versioni thread-safe equivalenti alle strutture dati della libreria di template standard del linguaggio C++.
Problemi del threading
Semantica di fork() ed exec()
- fork() duplica solo il thread che sta usando la chiamata di sistema o tutti i thread di quel processo?
- Alcuni UNIXes hanno due versioni della fork
- exec() di solito sostituisce il processo corrente insieme a tutti i suoi thread
L’uso delle due versioni della fork() dipende dall’applicazione. Se s’invoca la exec() immediatamente dopo la fork(), la duplicazione dei thread non è necessaria, poiché il programma specificato nei parametri della exec() sostituirà il processo. In questo caso conviene duplicare il solo thread chiamante. Tuttavia, se la exec() non segue immediatamente la fork(), il nuovo processo dovrebbe duplicare tutti i thread del processo genitore.
Gestione dei segnali
Per i processi a singolo thread la gestione dei segnali è semplice: i segnali vengono sempre inviati al processo. Per i processi multithread si pone il problema del thread cui si deve inviare il segnale. In generale esistono le seguenti possibilità:
- inviare il segnale al thread cui il segnale si riferisce;
- inviare il segnale a ogni thread del processo;
- inviare il segnale a specifici thread del processo;
- definire un thread specifico per ricevere tutti i segnali diretti al processo
Il metodo per recapitare un segnale dipende dal tipo di segnale. I segnali sincroni, per esempio, si devono inviare al thread che ha generato l’evento causa del segnale e non ad altri thread nel processo. Se si tratta di segnali asincroni la situazione non è invece così chiara; alcuni segnali asincroni, come il segnale che termina un processo (come Ctrl+C), si devono inviare a tutti i thread.
La maggior parte delle versioni multithread di unix permette che per ciascun thread si indichino i segnali da accettare e quelli da bloccare. Quindi, alcuni segnali asincroni si potrebbero recapitare soltanto ai thread che non li bloccano
Tuttavia, poiché i segnali vanno gestiti una sola volta, di solito un segnale è recapitato solo al primo thread che non lo blocca. La api Pthreads posix dispone della funzione
pthread_kill(pthread_t tid, int signal)
che permette di specificare il thread (tid) cui recapitare il segnale.
Sebbene Windows non preveda la gestione esplicita dei segnali, questi si possono emulare con le chiamate di procedure asincrone (asynchronous procedure call, apc). Le funzioni apc permettono a un thread a livello utente di specificare la funzione da richiamare quando il thread riceve la comunicazione di un particolare evento. Come s’intuisce dal nome, una apc è grosso modo equivalente a un segnale asincrono di unix. Mentre tuttavia in un ambiente multithread unix necessita di un criterio di gestione dei segnali, il sistema delle apc è più semplice, poiché una apc è rivolta a un particolare thread e non a un processo
Cancellazione dei thread
La cancellazione dei thread è l’operazione che permette di terminare un thread prima che completi il suo compito. Per esempio, se più thread eseguono una ricerca in modo concorrente in una base di dati e un thread riporta il risultato, gli altri thread possono essere cancellati. Una situazione analoga potrebbe verificarsi quando un utente preme il pulsante di terminazione di un browser web per interrompere il caricamento di una pagina. Spesso il caricamento di una pagina è gestito da più thread: ogni immagine è caricata da un thread separato; quando l’utente preme il pulsante di terminazione, tutti i thread che stanno caricando la pagina vengono cancellati.
Un thread da cancellare è spesso chiamato thread bersaglio (target thread). La cancellazione di un thread bersaglio può avvenire in due modi diversi:
- cancellazione asincrona. Un thread fa immediatamente terminare il thread bersaglio;
- cancellazione differita. Il thread bersaglio controlla periodicamente se deve terminare, in modo da effettuare la terminazione in maniera ordinata.
Si presentano difficoltà con la cancellazione nei casi in cui ci siano risorse assegnate a un thread cancellato, o se si cancella un thread mentre sta aggiornando dei dati che condivide con altri thread. Quest’ultimo caso è particolarmente problematico se si tratta di cancellazione asincrona. Il sistema operativo di solito si riappropria delle risorse di sistema usate da un thread cancellato, ma spesso non si riappropria di tutte le risorse. Quindi, la cancellazione di un thread in modo asincrono potrebbe non liberare una risorsa necessaria per tutto il sistema
La cancellazione differita invece funziona tramite un thread che segnala la necessità di cancellare un certo thread bersaglio; la cancellazione avviene soltanto quando il thread bersaglio verifica se debba essere o meno cancellato. Questo metodo permette di programmare la verifica in un punto dell’esecuzione in cui il thread sia cancellabile senza problemi.
Pthreads
In Pthreads la cancellazione del thread viene avviata tramite la funzione pthread_cancel(). L’identificatore del thread da cancellare viene passato come parametro alla funzione. La chiamata della pthread_cancel() comporta solamente una richiesta di cancellazione del thread di destinazione: l’effettiva cancellazione dipende da come il thread di destinazione è impostato per la gestione della richiesta. Pthreads supporta tre modalità di cancellazione, ognuna definita da uno stato e da un tipo, come illustrato nella tabella che segue. Un thread può impostare il suo stato di cancellazione e il suo tipo usando una api.
| Modalità | Stato | Tipo |
|---|---|---|
| Off | Disabilitato | - |
| Differita | Abilitato | Differito |
| Asincrona | Abilitato | Asincrono |
Come risulta dalla tabella, Pthreads permette di disabilitare o abilitare la cancellazione dei thread. Ovviamente, un thread non può essere cancellato se la cancellazione è disabilitata; tuttavia, le richieste di cancellazione rimangono in sospeso, in modo che il thread possa in seguito abilitare la cancellazione e rispondere alla richiesta.
Il tipo di cancellazione predefinito è la cancellazione differita, secondo cui la cancellazione avviene solo quando un thread raggiunge un punto di cancellazione (cancellation point). La maggior parte delle chiamate di sistema bloccanti in posix e nella libreria standard del C è definita come punto di cancellazione (è possibile elencare queste chiamate utilizzando il comando man pthreads su un sistema Linux). Per esempio, la chiamata di sistema read() è un punto di cancellazione che consente di cancellare un thread bloccato durante l’attesa di input da read().
Una tecnica per la creazione di un punto di cancellazione consiste nell’invocare la funzione pthread_testcancel(). In caso di richiesta di cancellazione in attesa, viene richiamata una funzione nota come gestore della pulizia (cleanup handler), che permette di rilasciare tutte le risorse che un thread può aver acquisito prima di eliminarlo.
Java Threads
La cancellazione del thread in Java utilizza una politica simile alla cancellazione differita in Pthreads. Per cancellare un thread Java occorre invocare il metodo interrupt(), che imposta lo stato di interruzione di un thread a true.
Un thread può controllare il suo stato di interruzione invocando isInterrupted(), che restituisce il valore booleano dello stato di interruzione di un thread.
Thread-Local Storage (TLS) o Dati localidel thread
Uno dei vantaggi principali della programmazione multithread è dato dal fatto che i thread appartenenti allo stesso processo ne condividono i dati. Tuttavia, in particolari circostanze, ogni thread può necessitare di una copia privata di certi dati, chiamati dati specifici dei thread (o tls). Per esempio, in un sistema transazionale si può svolgere ciascuna transazione tramite un thread distinto e assegnare un identificatore unico per ogni transazione. Per associare ciascun thread al relativo identificatore si possono usare dati specifici dei thread.
È facile confondere i dati specifici dei thread con le variabili locali. Mentre le variabili locali sono visibili solo durante la chiamata di una singola funzione, i dati specifici sono visibili attraverso tutte le chiamate. Inoltre, quando lo sviluppatore non ha alcun controllo sul processo di creazione dei thread, per esempio quando si utilizza una tecnica implicita come un gruppo di thread, è necessario un approccio alternativo.
In un certo senso, i tls assomigliano ai dati statici, con la differenza che i dati tls sono unici per ogni thread. (In effetti, i tls vengono solitamente dichiarati come static). La maggior parte delle librerie di thread e dei compilatori fornisce supporto per tls. Per esempio, Java fornisce una classe ThreadLocal con metodi set() e get() per gli oggetti ThreadLocal <T>. Pthreads include il tipo pthread_key_t che fornisce una chiave specifica per ogni thread. Questa chiave può essere utilizzata per accedere ai dati tls. Il linguaggio C# di Microsoft richiede semplicemente l’aggiunta dell’attributo [ThreadStatic] nella dichiarazione dei dati locali del thread. Il compilatore gcc fornisce la keyword _thread, che definisce la storage class necessaria per la dichiarazione dei dati locali dei thread
Attivazione dello scheduler
Un’ultima questione da affrontare in merito ai programmi multithread riguarda la comunicazione tra la libreria del kernel e la libreria per i thread, che può rendersi necessaria nel modello a due livelli e in quello da molti a molti. È proprio grazie a questa forma di coordinamento che il numero dei thread nel kernel è modificabile dinamicamente, con l’obiettivo di conseguire le migliori prestazioni.
Molti sistemi che implementano o il modello da molti a molti o quello a due livelli collocano una struttura dati intermedia tra i thread del kernel e dell’utente. Questa struttura dati, normalmente nota come processo leggero o LWP (acronimo di lightweight process), dal punto di vista della libreria di thread a livello utente si presenta come un processore virtuale a cui l’applicazione può richiedere lo scheduling di un thread a livello utente. Ciascun lwp è associato a un thread del kernel, e sono proprio i thread del kernel che il sistema operativo pone in esecuzione sui processori fisici. Se un thread del kernel si blocca (mentre attende il completamento di un’operazione di i/o, per esempio) anche l’lwp si blocca. L’effetto a catena risale fino al thread a livello utente associato all’lwp, che si blocca anch’esso.
Tipicamente si usa una struttura dati intermedia tra i thread utente e i thread kernel, il lightweight process (LWP)
- appare come un processore virtuale su cui il processo può schedulare processi utente da eseguire
- Ogni LWP è collegato a un thread kernel
Quanti LWP da creare? Per un’efficiente esecuzione un’applicazione può aver bisogno di un numero imprecisato di lwp. Si consideri un processo con prevalenza di elaborazione eseguito da un singolo processore. In questa situazione è eseguibile solo un thread per volta, dunque un lwp è sufficiente. Un’applicazione con prevalenza di i/o potrebbe, tuttavia, richiedere l’esecuzione di molteplici lwp. Di solito è necessario un lwp per ogni chiamata di sistema concorrente bloccante. Supponiamo, per esempio, che giungano allo stesso tempo cinque richieste differenti per la lettura di file. Sono necessari cinque lwp, nel caso in cui tutte le richieste restino in attesa del completamento dell’i/o nel kernel. Se un processo ha soltanto quattro lwp, la quinta richiesta deve attendere che uno degli lwp sia rilasciato dal kernel.
Uno dei modelli di comunicazione tra la libreria a livello utente e il kernel è conosciuto come attivazione dello scheduler. Il suo funzionamento è il seguente: il kernel fornisce all’applicazione una serie di processori virtuali (lwp), mentre l’applicazione esegue lo scheduling dei thread dell’utente sui processori virtuali disponibili. Inoltre, il kernel deve informare l’applicazione se si verificano determinati eventi, seguendo una procedura nota come upcall. Le upcall sono gestite dalla libreria dei thread mediante un apposito gestore, eseguito su un processore virtuale. Una situazione capace di innescare una upcall si verifica quando il thread di un’applicazione è sul punto di bloccarsi. In questo caso il kernel, tramite una upcall, informa l’applicazione che un thread è prossimo a bloccarsi, e identifica il thread in oggetto. Il kernel, quindi, assegna all’applicazione un nuovo processore virtuale. L’applicazione esegue un gestore della upcall su questo nuovo processore: il gestore salva lo stato del thread bloccante e rilascia il processore virtuale su cui era stato eseguito. Il gestore della upcall pianifica allora l’esecuzione di un altro thread sul nuovo processore virtuale. Quando si verifica l’evento atteso dal thread bloccante, il kernel fa un’altra upcall alla libreria dei thread per comunicare che il thread bloccato è nuovamente in condizione di essere eseguito. Il gestore di questa upcall necessita anch’esso di un processore virtuale: il kernel può crearne uno ex novo, o sottrarlo a un thread utente per prelazione. L’applicazione contrassegna il thread fino ad allora bloccato come pronto per l’esecuzione, ed esegue lo scheduling di un thread pronto per l’esecuzione su un processore virtuale disponibile.
Esempi di thread negli OS
Windows threads
Un’applicazione per l’ambiente Windows si esegue come un processo separato; ogni processo può contenere uno o più thread. Il sistema Windows impiega il modello da uno a uno, secondo cui ogni thread a livello utente si associa a un thread del kernel.
I componenti generali di un thread includono:
- un identificatore di thread (id), che identifica univocamente il thread;
- un insieme di registri che rappresenta lo stato del processore;
- un contatore di programma;
- uno stack utente, usato quando il thread è eseguito in modalità utente, e uno stack kernel, usato quando il thread è eseguito in modalità kernel;
- un’area di memoria privata, usata da diverse librerie run-time e dinamiche (dll).
L’insieme di registri, stack e area di dati privati sono il CONTESTO DEL THREAD
Le strutture dati primarie di un thread sono:
- ETHREAD (executive thread block): I componenti chiave dell’ethread sono un puntatore al processo a cui il thread appartiene e l’indirizzo della funzione in cui il thread inizia l’esecuzione. La struttura ethread contiene anche un puntatore alla corrispondente struttura kthread.
- KTHREAD (kernel thread block): include informazioni per il thread relative allo scheduling e alla sincronizzazione. Inoltre, kthread contiene lo stack kernel (usato quando il thread viene eseguito in modalità kernel) e un puntatore alla struttura teb.
- TEB (thread environment block): contiene ID thread, stack a livello utente, vettore di dati specifici del thread
Le strutture ethread e kthread risiedono interamente nello spazio del kernel; ciò implica che solo il kernel vi può accedere. La struttura dati teb appartiene invece allo spazio utente e vi si accede quando il thread è eseguito in modalità utente.

Linux Thread
Linux offre la chiamata di sistema fork() per duplicare un processo, e prevede inoltre la chiamata di sistema clone() per generare nuovo thread. Tuttavia Linux non distingue tra processi e thread, impiegando generalmente al loro posto il termine task in riferimento a un flusso del controllo nell’ambito di un programma.
Quando clone() è invocata, riceve come parametro un insieme di indicatori (flag), al fine di stabilire quante e quali risorse del task genitore debbano essere condivise dal task figlio. I flag controllano il loro comportamento:
- CLONE_FS: informazioni del file system sono condivise
- CLONE_VM: lo stesso spazio di memoria è condiviso
- CLONE_SIGHAND: i signal handler sono condivisi
- CLONE_FILES: l’insieme di file aperti è condiviso
Per esempio, qualora clone() riceva i flag CLONE_FS, CLONE_VM, CLONE_SIGHAND e CLONE_FILES, il task genitore e il task figlio condivideranno le medesime informazioni sul file system (come la directory attiva), lo stesso spazio di memoria, gli stessi gestori dei segnali e lo stesso insieme di file aperti. Adoperare clone() in questo modo è equivalente a creare thread come descritto in questo capitolo, dal momento che il task genitore condivide la maggior parte delle proprie risorse con il task figlio. Tuttavia, se nessuno dei flag è impostato al momento dell’invocazione di clone(), non si ha alcuna condivisione, e la funzionalità ottenuta diventa simile a quella fornita dalla chiamata di sistema fork().
Questa condivisione a intensità variabile è resa possibile dal modo in cui un task è rappresentato nel kernel di Linux. Per ogni task, nel kernel esiste un’unica struttura dati (e precisamente, struct task_struct). Questa struttura, invece di memorizzare i dati del task relativo, utilizza dei puntatori ad altre strutture dove i dati sono effettivamente contenuti: per esempio, strutture dati che rappresentano l’elenco dei file aperti, le informazioni per la gestione dei segnali e la memoria virtuale. Quando si invoca fork(), si crea un nuovo task insieme con una copia di tutte le strutture dati del task genitore. Anche quando s’invoca la chiamata clone() si crea un nuovo task, ma anziché ricevere una copia di tutte le strutture dati, il nuovo task può puntare alle strutture dati del task genitore, a seconda dell’insieme di flag passati a clone().
Infine, la chiamata di sistema clone() può essere usata per implementare il concetto di contenitore (container); un contenitore è una tecnica di virtualizzazione fornita dal sistema operativo che consente di creare diversi sistemi Linux (contenitori), isolati l’uno dall’altro, su un singolo kernel Linux. Proprio come alcuni flag passati alla clone() permettono di generare un task che si comporta come un processo o come un thread a seconda della quantità di condivisione tra i padre e figlio, ci sono altri flag della clone() che consentono la creazione di un contenitore Linux.
Schedulazione dei thread
Nel Capitolo 4 abbiamo arricchito il modello dei processi con i thread, distinguendo quelli a livello utente da quelli a livello kernel. Sui sistemi operativi che prevedono la loro presenza, il sistema non effettua lo scheduling dei processi, ma dei thread a livello kernel. I thread a livello utente sono gestiti da una libreria: il kernel non è consapevole della loro esistenza. Di conseguenza, per eseguire i thread a livello utente occorre associare loro dei thread a livello kernel. Tale associazione può essere indiretta, ossia realizzata con un processo leggero (lwp). Trattiamo adesso le questioni dello scheduling che riguardano i thread a livello utente e a livello kernel, offrendo esempi specifici dello scheduling per Pthreads
Ambito della contesa
Una distinzione fra thread a livello utente e a livello kernel riguarda il modo in cui vengono schedulati. Nei sistemi che impiegano il modello da molti a uno e il modello da molti a molti, la libreria dei thread pianifica l’esecuzione dei thread a livello utente su un lwp libero; si parla allora di ambito della contesa ristretto al processo (process-contention scope, pcs), perché la contesa per aggiudicarsi la cpu ha luogo fra thread dello stesso processo. In realtà, affermando che la libreria dei thread pianifica l’esecuzione dei thread a livello utente associandoli agli lwp liberi, non si intende che il thread sia in esecuzione su una cpu; ciò avviene solo quando il sistema operativo pianifica l’esecuzione di thread del kernel su un processore fisico. Per determinare quale thread a livello kernel debba essere eseguito da una cpu, il kernel esamina i thread di tutto il sistema; si parla allora di ambito della contesa allargato al sistema (system-contention scope, scs). Quindi, nel caso di scs, tutti i thread del sistema competono per l’uso della cpu. I sistemi caratterizzati dal modello da uno a uno (Paragrafo 4.3.2) quali Windows e Linux, schedulano i thread unicamente sulla base di scs.
Nel caso del pcs, lo scheduling è solitamente basato sulle priorità: lo scheduler sceglie per l’esecuzione il thread con priorità più alta. Le priorità dei thread a livello utente sono stabilite dal programmatore, e la libreria dei thread non le modifica; alcune librerie danno facoltà al programmatore di cambiare la priorità di un thread. Si noti che quando l’ambito della contesa è ristretto al processo si è soliti applicare la prelazione al thread in esecuzione, a vantaggio di thread con priorità più alta; tuttavia, se i thread sono dotati della medesima priorità, non vi è garanzia di time slicing (porzione di tempo)
Scheduling di Pthread
La generazione dei thread con posix Pthreads è stata introdotta nel Paragrafo 4.4.1, insieme a un programma esemplificativo. Ci accingiamo ora a esaminare la api Pthread di posix, che consente di specificare pcs o scs nella fase di generazione dei thread. Per specificare l’ambito della contesa Pthreads usa i valori seguenti:
- pthread_scope_process pianifica i thread con lo scheduling pcs
- pthread_scope_system pianifica i thread tramite lo scheduling scs
Nei sistemi che si avvalgono del modello da molti a molti la politica pthread_scope_process pianifica i thread a livello utente sugli lwp disponibili. Il numero di lwp viene mantenuto dalla libreria dei thread, che può servirsi delle attivazioni dello scheduler (Paragrafo 4.6.5). La seconda politica, pthread_scope_system, crea, in corrispondenza di ciascun thread a livello utente, un lwp a esso vincolato, realizzando così, in effetti, una corrispondenza secondo il modello da molti a uno.
L’ipc di Pthread offre due funzioni per leggere (e impostare) l’ambito della contesa:
pthread_attr_setscope(pthread_attr_t *attr, int scope)pthread_attr_getscope(pthread_attr_t *attr, int *scope)
Il primo parametro per entrambe le funzioni è un puntatore agli attributi del thread. Il secondo parametro della funzione pthread_attr_setscope() riceve uno dei valori pthread_scope_system o pthread_scope_process, che stabiliscono come deve essere impostato l’ambito della contesa. Nel caso di pthread_attr_getscope() il secondo parametro contiene un puntatore a un intero che contiene l’attuale valore dell’ambito della contesa. Qualora si verifichi un errore, ambedue le funzioni restituiscono valori non nulli.
Nella Figura 5.10 illustriamo l’api di scheduling Pthread mediante un programma che determina l’ambito della contesa in vigore e lo imposta a pthread_scope_system; quindi crea cinque thread distinti, che andranno in esecuzione secondo il modello di scheduling scs. Si noti che, nel caso di alcuni sistemi, sono possibili solo determinati valori per l’ambito della contesa. I sistemi Linux e macos, per esempio, consentono soltanto pthread_scope_system.
4 - Fiber
Definizione: fiber
Un fiber è un’unità in cui può essere ulteriormente suddiviso un thread.
Fonti
- Abraham Silberschatz, Peter Baer Galvin, Greg Gagne - Sistemi Operativi (10ᵃ Edizione) - Pearson, 2019 - ISBN:
9788891904560.- Capitolo 4: thread
- Capitolo 5: schedulazione della CPU
- 🏫 Lezioni e slide del Prof. Aldinucci Marco del corso di Sistemi Operativi (canale B), Corso di Laurea in Informatica presso l’Università di Torino, A.A. 2024-25:
- 🏫 Appunti di Carlos Palomino del corso di Sistemi Operativi, Corso di Laurea in Informatica presso l’Università di Torino, A.A. 2024-25 (caricati sul repository GitHub del Team Studentesco Informatica):