Nel Capitolo 5 si è descritto come è possibile condividere la cpu tra un insieme di processi. Uno dei risultati dello scheduling della cpu consiste nella possibilità di migliorare sia l’utilizzo della cpu sia la rapidità con cui il calcolatore risponde ai propri utenti; per ottenere questo aumento delle prestazioni, tuttavia, occorre tenere in memoria parecchi processi: la memoria deve, cioè, essere condivisa.
In questo capitolo si presentano diversi metodi di gestione della memoria. Gli algoritmi di gestione della memoria variano dall’approccio più semplice che accede all’hardware della macchina in maniera diretta ai metodi di paginazione e segmentazione. Ogni metodo presenta vantaggi e svantaggi. La scelta di un metodo specifico di gestione della memoria dipende da molti fattori, in particolar modo dall’architettura hardware del sistema, infatti molti algoritmi richiedono un supporto hardware. Per questa ragione in molti sistemi l’hardware e la gestione della memoria da parte del sistema operativo sono strettamente integrati.
Introduzione
Come abbiamo visto nel Capitolo 1, la memoria è fondamentale nelle operazioni di un moderno sistema di calcolo. La memoria consiste in un grande vettore di byte, ciascuno con il proprio indirizzo. La cpu preleva le istruzioni dalla memoria sulla base del contenuto del contatore di programma; tali istruzioni possono determinare ulteriori letture (load) e scritture (store) in specifici indirizzi di memoria. Un tipico ciclo d’esecuzione di un’istruzione, per esempio, prevede che l’istruzione sia prelevata dalla memoria; quindi viene decodificata (e ciò può comportare il prelievo di operandi dalla memoria) e poi eseguita sugli eventuali operandi; i risultati si possono scrivere in memoria. La memoria vede soltanto un flusso d’indirizzi di memoria, e non sa come sono generati (contatore di programma, indicizzazione, riferimenti indiretti, indirizzamenti immediati e così via), oppure a che cosa servano (istruzioni o dati). Di conseguenza, è possibile ignorare come un programma genera un indirizzo di memoria, e prestare attenzione solo alla sequenza degli indirizzi di memoria generati dal programma in esecuzione. L’analisi che sviluppiamo nel seguito comprende una panoramica degli aspetti basilari della gestione della memoria: l’hardware, la mappatura degli indirizzi simbolici in indirizzi fisici effettivi, e la distinzione fra indirizzamento logico e fisico. Concluderemo il paragrafo discutendo il linking dinamico e la condivisione delle librerie.
Hardware di base
La memoria centrale e i registri incorporati nel processore sono le sole aree di memorizzazione a cui la cpu può accedere direttamente. Vi sono istruzioni macchina che accettano gli indirizzi di memoria come argomenti, ma nessuna accetta gli indirizzi del disco. Pertanto, qualsiasi istruzione in esecuzione, e tutti i dati utilizzati dalle istruzioni, devono risiedere in uno di questi dispositivi di memorizzazione ad accesso diretto. I dati che non sono in memoria devono essere caricati prima che la cpu possa operare su di loro.
I registri incorporati nella cpu sono accessibili, in genere, nell’arco di un ciclo del clock della cpu. I core di alcune cpu sono capaci di decodificare istruzioni ed effettuare semplici operazioni sui contenuti dei registri alla velocità di una o più operazioni per ciclo. Ciò non vale per la memoria centrale, cui si accede tramite una transazione sul bus della memoria che può richiedere molti cicli di clock. In tal caso il processore entra necessariamente in stallo (stall), poiché manca dei dati richiesti per completare l’istruzione che sta eseguendo. Questa situazione è intollerabile, perché gli accessi alla memoria sono frequenti. Il rimedio consiste nell’interposizione di una memoria veloce tra cpu e memoria centrale. Di solito questo buffer di memoria, detto cache, si trova sul chip della cpu, in modo da garantire un accesso più rapido. La cache è stata descritta nel Paragrafo 1.5.5. Nella gestione di una cache interna alla cpu l’hardware si occupa direttamente di accelerare l’accesso alla memoria, senza l’intervento del sistema operativo. Ricordiamo dal Paragrafo 5.5.2 che durante uno stallo di memoria un core multithread può scambiare il thread hardware bloccato con un altro thread hardware.
Non basta prestare attenzione alle velocità relative di accesso alla memoria fisica, ma occorre anche assicurare una corretta esecuzione delle operazioni. A tal fine, bisogna proteggere il sistema operativo dall’accesso dei processi utenti, e, in sistemi multiutente, salvaguardare i processi utenti l’uno dall’altro. Tale protezione deve essere messa in atto a livello hardware, perché solitamente il sistema operativo, per una questione di prestazioni, non interviene negli accessi della cpu alla memoria. Come si vedrà lungo tutto il capitolo, questa protezione può essere realizzata dall’hardware con meccanismi diversi. In questo paragrafo evidenziamo una delle possibili implementazioni.
Innanzitutto, bisogna assicurarsi che ciascun processo abbia uno spazio di memoria separato, in modo da proteggere i processi l’uno dall’altro: ciò è fondamentale per avere più processi caricati in memoria per l’esecuzione concorrente. Per separare gli spazi di memoria occorre poter determinare l’intervallo degli indirizzi a cui un processo può accedere legalmente, e garantire che possa accedere soltanto a questi indirizzi. Si può implementare il meccanismo di protezione tramite due registri, detti registro base e registro limite, come illustrato nella Figura 9.1. Il registro base contiene il più piccolo indirizzo legale della memoria fisica; il registro limite determina la dimensione dell’intervallo ammesso. Per esempio, se i registri base e limite contengono rispettivamente i valori 300040 e 120900, al programma si consente l’accesso agli indirizzi compresi tra 300040 e 420939, estremi inclusi.
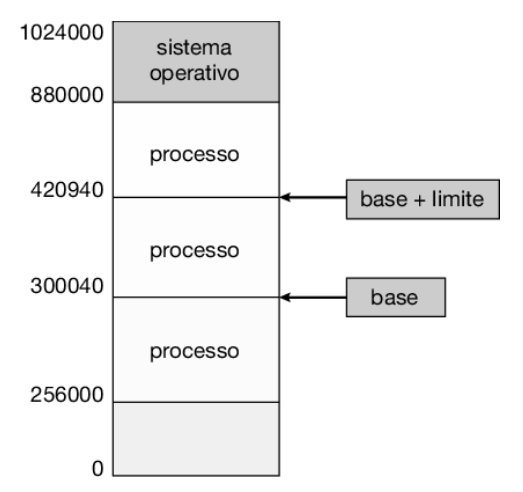
Per mettere in atto il meccanismo di protezione, la cpu confronta ciascun indirizzo generato in modalità utente con i valori contenuti nei due registri. Qualsiasi tentativo da parte di un programma eseguito in modalità utente di accedere alle aree di memoria riservate al sistema operativo o a una qualsiasi area di memoria riservata ad altri utenti comporta l’invio di una eccezione (trap) che restituisce il controllo al sistema operativo che, a sua volta, interpreta l’evento come un errore fatale (Figura 9.2). Questo schema impedisce a qualsiasi programma utente di alterare (accidentalmente o intenzionalmente) il codice o le strutture dati del sistema operativo o degli altri utenti.
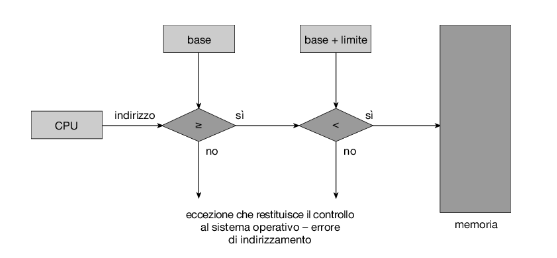
Solo il sistema operativo può caricare i registri base e limite, grazie a una speciale istruzione privilegiata. Dal momento che le istruzioni privilegiate possono essere eseguite unicamente in modalità kernel, e poiché solo il sistema operativo può essere eseguito in tale modalità, tale schema gli consente di modificare il valore di questi registri, ma impedisce tale operazione ai programmi utenti.
Grazie all’esecuzione in modalità kernel, il sistema operativo ha la possibilità di accedere indiscriminatamente sia alla memoria a esso riservata sia a quella riservata agli utenti. Questo privilegio consente al sistema di caricare i programmi utenti nelle aree di memoria a loro riservate; di generare copie del contenuto di queste regioni di memoria (dump) a scopi diagnostici, qualora si verifichino errori; di modificare i parametri delle chiamate di sistema; di eseguire i/o da e verso la memoria utente e di fornire molti altri servizi. Consideriamo, per esempio, che un sistema operativo per un sistema multiprocessing deve effettuare cambi di contesto, memorizzando lo stato di un processo dai registri nella memoria centrale prima di caricare il contesto del processo successivo dalla memoria centrale nei registri.
Associazione degli indirizzi
In genere un programma risiede in un disco sotto forma di un file binario eseguibile. Per essere eseguito, il programma va caricato in memoria e inserito nel contesto di un processo (come descritto nel Paragrafo 2.5), dove diventa idoneo per l’esecuzione su una cpu disponibile.
Il processo durante l’esecuzione può accedere alle istruzioni e ai dati in memoria. Quando il processo termina, si dichiara disponibile il suo spazio di memoria.
La maggior parte dei sistemi consente ai processi utenti di risiedere in qualsiasi parte della memoria fisica, quindi, anche se lo spazio d’indirizzi del calcolatore comincia all’indirizzo 00000, il primo indirizzo del processo utente non deve necessariamente essere 0. Vedremo più avanti come un programma utente inserisce un processo nella memoria fisica.
Nella maggior parte dei casi un programma utente, prima di essere eseguito, deve passare attraverso vari passi, alcuni dei quali possono essere facoltativi (Figura 9.3). In questi passi gli indirizzi sono rappresentabili in modi diversi. Generalmente gli indirizzi del programma sorgente sono simbolici (per esempio, la variabile count). Un compilatore di solito associa (bind) questi indirizzi simbolici a indirizzi rilocabili (per esempio, “14 byte dall’inizio di questo modulo”). L’editor dei collegamenti (linkage editor), o il caricatore (loader), fa corrispondere a sua volta questi indirizzi rilocabili a indirizzi assoluti (per esempio, 74014). Ogni associazione rappresenta una corrispondenza da uno spazio d’indirizzi a un altro
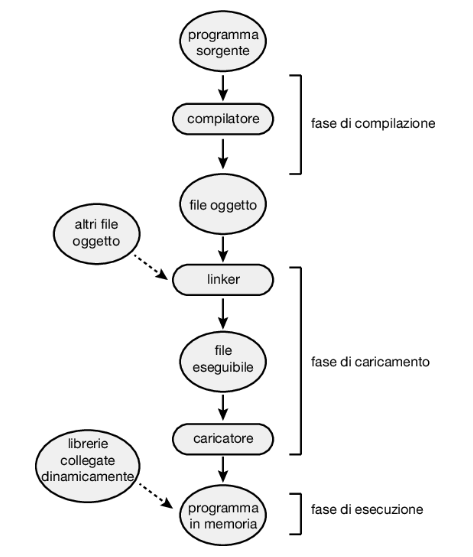
Generalmente, l’associazione di istruzioni e dati a indirizzi di memoria si può compiere in qualsiasi passo del seguente percorso:
- Compilazione. Se nella fase di compilazione si sa dove il processo risiederà in memoria, si può generare codice assoluto. Se, per esempio, è noto a priori che un processo utente inizia alla locazione R, anche il codice generato dal compilatore comincia da quella locazione. Se, in un momento successivo, la locazione iniziale cambiasse, sarebbe necessario ricompilare il codice.
- Caricamento. Se nella fase di compilazione non è possibile sapere in che punto della memoria risiederà il processo, il compilatore deve generare codice rilocabile. In questo caso si ritarda l’associazione finale degli indirizzi alla fase del caricamento. Se l’indirizzo iniziale cambia, è sufficiente ricaricare il codice utente per incorporare il valore modificato.
- Esecuzione. Se durante l’esecuzione il processo può essere spostato da un segmento di memoria a un altro, si deve ritardare l’associazione degli indirizzi fino alla fase d’esecuzione. Per realizzare questo schema è necessario disporre di hardware specializzato; questo argomento è trattato nel Paragrafo 9.1.3. La maggior parte dei sistemi operativi general-purpose impiega questo metodo.
Una gran parte di questo capitolo è dedicata alla spiegazione di come i vari tipi di associazione degli indirizzi si possano realizzare efficacemente in un calcolatore e, inoltre, alla discussione dell’appropriato supporto hardware per queste funzioni.
Spazi di indirizzi logici e fisici
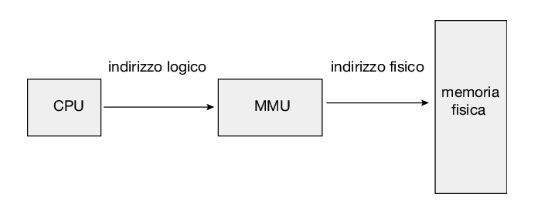
Un indirizzo generato dalla cpu è normalmente chiamato indirizzo logico, mentre un indirizzo visto dall’unità di memoria, cioè caricato nel registro dell’indirizzo di memoria (memory address register, mar) è normalmente chiamato indirizzo fisico.
I metodi di associazione degli indirizzi nelle fasi di compilazione e di caricamento producono indirizzi logici e fisici identici. Con il metodo di associazione nella fase d’esecuzione, invece, gli indirizzi logici non coincidono con gli indirizzi fisici. In questo caso ci si riferisce, di solito, agli indirizzi logici col termine indirizzi virtuali; in questo testo si usano tali termini in modo intercambiabile. L’insieme di tutti gli indirizzi logici generati da un programma è lo spazio degli indirizzi logici; l’insieme degli indirizzi fisici corrispondenti a tali indirizzi logici è lo spazio degli indirizzi fisici. Quindi, con lo schema di associazione degli indirizzi nella fase d’esecuzione, lo spazio degli indirizzi logici differisce dallo spazio degli indirizzi fisici.
L’associazione nella fase d’esecuzione dagli indirizzi virtuali agli indirizzi fisici è svolta da un dispositivo detto unità di gestione della memoria (memory-management unit, mmu):
Come viene discusso nei Paragrafi dal 9.2 al 9.3, si può scegliere tra diversi metodi di realizzazione di tale associazione. Per ora illustriamo un semplice schema di associazione degli indirizzi tramite mmu, che è una generalizzazione dello schema con registro di base descritto nel Paragrafo 9.1.1. Com’è illustrato nella Figura 9.5, il registro di base è ora denominato registro di rilocazione: quando un processo utente genera un indirizzo, prima dell’invio all’unità di memoria, si somma a tale indirizzo il valore contenuto nel registro di rilocazione. Per esempio, se il registro di rilocazione contiene il valore 14000, un tentativo da parte dell’utente di accedere alla locazione 0 è dinamicamente rilocato alla locazione 14000; un accesso alla locazione 346 è mappato alla locazione 14346:
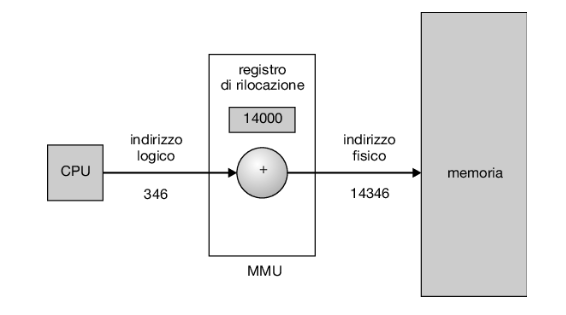
Il programma utente non vede mai i reali indirizzi fisici. Il programma crea un puntatore alla locazione 346, lo memorizza, lo modifica, lo confronta con altri indirizzi, tutto ciò sempre come il numero 346. Solo quando assume il ruolo di un indirizzo di memoria (magari in una load o una store indiretta), si riloca il numero sulla base del contenuto del registro di rilocazione. Il programma utente tratta indirizzi logici, l’architettura del sistema converte gli indirizzi logici in indirizzi fisici. Questa forma di collegamento nella fase d’esecuzione è stata trattata nel Paragrafo 9.1.2. La locazione finale di un riferimento a un indirizzo di memoria non è determinata finché non si compie effettivamente il riferimento.
In questo caso esistono due diversi tipi di indirizzi: gli indirizzi logici (nell’intervallo da 0 a max) e gli indirizzi fisici (nell’intervallo da r + 0 a r + max per un valore di base r). Il programma utente genera solo indirizzi logici e pensa che il processo sia eseguito nelle posizioni da 0 a max. Tuttavia questi indirizzi logici devono essere mappati in indirizzi fisici prima d’essere usati. Il concetto di spazio d’indirizzi logici mappato su uno spazio d’indirizzi fisici separato è fondamentale per una corretta gestione della memoria.
Caricamento dinamico
Nella discussione svolta fin’ora, era necessario che l’intero programma e i dati di un processo fossero presenti nella memoria fisica perché il processo potesse essere eseguito. La dimensione di un processo era quindi limitata alle dimensioni della memoria fisica. Per migliorare l’utilizzo della memoria si può ricorrere al caricamento dinamico (dynamic loading), mediante il quale si carica una procedura solo quando viene richiamata; tutte le procedure si tengono su disco in un formato di caricamento rilocabile. Si carica il programma principale in memoria e quando, durante l’esecuzione, una procedura deve richiamarne un’altra, controlla innanzitutto che sia stata caricata. Se non è stata caricata, si richiama il linking loader rilocabile per caricare in memoria la procedura richiesta e aggiornare le tabelle degli indirizzi del programma in modo che registrino questo cambiamento. A questo punto il controllo passa alla procedura appena caricata.
Il vantaggio dato dal caricamento dinamico consiste nel fatto che una procedura viene caricata solo quando serve. Questo metodo è utile soprattutto quando servono grandi quantità di codice per gestire casi non frequenti, per esempio le procedure di gestione degli errori. In questi casi, anche se un programma può avere dimensioni totali elevate, la parte effettivamente usata, e quindi effettivamente caricata, può essere molto più piccola.
Il caricamento dinamico non richiede un supporto particolare del sistema operativo. Spetta agli utenti progettare i programmi in modo da trarre vantaggio da un metodo di questo tipo. Il sistema operativo può tuttavia aiutare il programmatore fornendo librerie di procedure che realizzano il caricamento dinamico.
Linking dinamico e librerie condivise
Le librerie collegate dinamicamente (dll) sono librerie di sistema che vengono collegate ai programmi utente quando questi vengono eseguiti (si faccia riferimento alla Figura 9.3). Alcuni sistemi operativi consentono solo il collegamento statico (static linking), in cui le librerie di sistema sono trattate come qualsiasi altro modulo oggetto e combinate dal loader nell’immagine binaria del programma. Il concetto di linking dinamico, invece, è analogo a quello di caricamento dinamico. Invece di differire il caricamento di una procedura fino al momento dell’esecuzione, si differisce il collegamento. Questa modalità si usa soprattutto con le librerie di sistema, per esempio la libreria standard del linguaggio C. Senza questo strumento tutti i programmi di un sistema dovrebbero disporre, all’interno dell’eseguibile, di una copia della libreria di linguaggio (o almeno delle procedure cui il programma fa riferimento). Ciò porta a un aumento della dimensione del file eseguibile e a un possibile spreco di spazio in memoria centrale. Un secondo vantaggio delle dll è che possono essere condivise tra più processi, in modo che solo un’istanza della dll risieda nella memoria centrale. Per questo motivo, le dll sono anche conosciute come librerie condivise e sono ampiamente utilizzate nei sistemi Windows e Linux.
Quando un programma fa riferimento a una routine presente in una libreria dinamica, il loader individua la dll e, se necessario, la carica in memoria. Gli indirizzi sono poi modificati in modo che facciano riferimento alle funzioni nella libreria dinamica secondo la posizione della dll in memoria. Le librerie collegate dinamicamente possono essere estese mediante aggiornamenti (per esempio, per correggere bug) o anche sostituite da una nuova versione. In questo caso, tutti i programmi che fanno riferimento alla libreria utilizzeranno automaticamente la nuova versione. Senza linking dinamico tutti i programmi di questo tipo avrebbero bisogno di essere nuovamente linkati per accedere alla nuova libreria. Affinché i programmi non eseguano accidentalmente nuove versioni di librerie incompatibili, le informazioni sulla versione sono incluse sia nel programma sia nella libreria. È possibile caricare in memoria più di una versione della stessa libreria e ogni programma si serve delle informazioni sulla versione per decidere quale copia della libreria utilizzare. Se le modifiche sono di piccola entità, il numero di versione resta invariato; se l’entità delle modifiche diviene rilevante, si aumenta anche il numero di versione. Perciò, solo i programmi compilati con la nuova versione della libreria subiscono gli effetti delle modifiche incompatibili incorporate nella libreria stessa. I programmi collegati prima dell’installazione della nuova libreria continuano ad avvalersi della vecchia libreria.
A differenza del caricamento dinamico, il linking dinamico e le librerie condivise richiedono generalmente l’assistenza del sistema operativo. Se i processi presenti in memoria sono protetti l’uno dall’altro, il sistema operativo è l’unica entità che può controllare se la procedura richiesta da un processo è nello spazio di memoria di un altro processo, o che può consentire l’accesso di più processi agli stessi indirizzi di memoria. Questo concetto è sviluppato nell’analisi della paginazione, nel Paragrafo 9.3.4.
Allocazione contigua della memoria
La memoria centrale deve contenere sia il sistema operativo sia i vari processi utenti; perciò è necessario assegnare le diverse parti della memoria centrale nel modo più efficiente. In questo paragrafo si tratta il primo metodo di allocazione della memoria, l’allocazione contigua.
La memoria centrale di solito si divide in due partizioni, una per il sistema operativo residente e una per i processi utente. Il sistema operativo si può collocare sia nella parte bassa sia nella parte alta della memoria. Questa decisione dipende da molti fattori, per esempio dalla posizione del vettore delle interruzioni. Visto però che molti sistemi operativi (inclusi Linux e Windows) collocano il sistema operativo in memoria alta, discutiamo solo questa situazione.
Generalmente si vuole che più processi utenti risiedano contemporaneamente in memoria centrale. Perciò è necessario considerare come assegnare la memoria disponibile ai processi presenti nella coda d’ingresso che attendono di essere caricati in memoria. Con l’allocazione contigua della memoria, ciascun processo è contenuto in una singola sezione di memoria contigua a quella che contiene il processo successivo. Prima di discutere ulteriormente questo schema di allocazione della memoria dobbiamo affrontare il problema della protezione della memoria
Protezione della memoria
Prima di trattare l’allocazione della memoria, dobbiamo soffermarci sul problema della protezione della memoria. Possiamo evitare che un processo acceda alla memoria che non gli appartiene combinando due idee discusse in precedenza. Se abbiamo un sistema con un registro di rilocazione (Paragrafo 9.1.3) e un registro limite (Paragrafo 9.1.1) abbiamo già raggiunto il nostro obiettivo. Il registro di rilocazione contiene il valore dell’indirizzo fisico minore; il registro limite contiene l’intervallo di indirizzi logici, per esempio, rilocazione = 100.040 e limite = 74.600. Ogni indirizzo logico deve cadere nell’intervallo specificato dal registro limite; la mmu fa corrispondere dinamicamente l’indirizzo fisico all’indirizzo logico sommando a quest’ultimo il valore contenuto nel registro di rilocazione (Figura 9.6), e invia l’indirizzo risultante alla memoria.
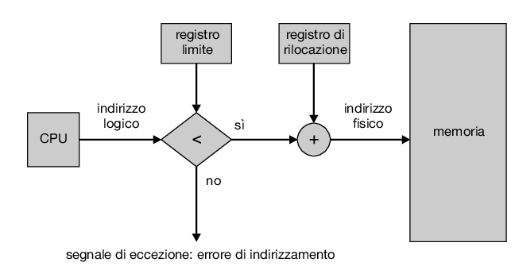
Quando lo scheduler della cpu seleziona un processo per l’esecuzione, il dispatcher, durante l’esecuzione del cambio di contesto, carica il registro di rilocazione e il registro limite con i valori corretti. Poiché si confronta ogni indirizzo generato dalla cpu con i valori contenuti in questi registri, si possono proteggere il sistema operativo, i programmi e i dati di altri utenti da tentativi di modifiche da parte del processo in esecuzione.
Lo schema con registro di rilocazione consente al sistema operativo di cambiare dinamicamente le proprie dimensioni. Tale flessibilità è utile in molte situazioni; il sistema operativo, per esempio, contiene codice e spazio di memoria per i driver dei dispositivi. Se un driver di periferica non è attualmente in uso, ha poco senso mantenerlo in memoria. È meglio, invece, caricarlo in memoria solo quando è necessario e rimuoverlo quando non lo è più, destinando la sua memoria ad altre esigenze.
Allocazione della memoria
Siamo ora pronti per parlare dell’allocazione della memoria. Uno dei metodi più semplici per l’allocazione della memoria consiste nel suddividere la stessa in partizioni di dimensione variabile, dove ciascuna partizione può contenere esattamente un processo. In questo schema a partizione variabile il sistema operativo conserva una tabella in cui sono indicate le partizioni di memoria disponibili e quelle occupate. Inizialmente tutta la memoria è a disposizione dei processi utenti; si tratta di un grande blocco di memoria disponibile, un buco (hole). Nel lungo periodo, come si vede nel seguito, la memoria contiene una serie di buchi di diverse dimensioni.
La Figura 9.7 illustra questo schema. Inizialmente, la memoria è completamente utilizzata e contiene i processi 5, 8 e 2. Dopo l’uscita del processo 8 si forma un unico buco. Successivamente, entra in memoria il processo 9, per il quale viene allocata memoria. Quindi il processo 5 viene rimosso, producendo due buchi non contigui.
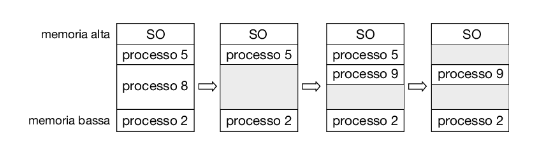
Quando i processi entrano nel sistema, il sistema operativo prende in considerazione i loro requisiti di memoria e la quantità di spazio di memoria disponibile e determina a quali processi allocare memoria. Quando gli viene assegnato dello spazio, un processo viene caricato in memoria e può quindi competere per il controllo della cpu. Quando termina, rilascia la memoria che gli era stata assegnata e il sistema operativo può impiegarla per un altro processo.
Che cosa succede quando non c’è sufficiente memoria per soddisfare le esigenze di un processo in arrivo? Un’opzione semplice è rifiutare il processo e fornire un messaggio di errore appropriato. In alternativa, possiamo inserire il processo in una coda di attesa. Quando, in seguito, la memoria viene rilasciata, il sistema operativo controlla la coda di attesa per determinare se può soddisfare le richieste di memoria di un processo in attesa.
In generale è sempre presente un insieme di buchi di diverse dimensioni sparsi per la memoria. Quando si presenta un processo che necessita di memoria, il sistema cerca nel gruppo un buco di dimensioni sufficienti per contenerlo. Se è troppo grande, il buco viene diviso in due parti: si assegna una parte al processo in arrivo e si riporta l’altra nell’insieme dei buchi. Quando termina, un processo rilascia il blocco di memoria, che si reinserisce nell’insieme dei buchi; se si trova accanto ad altri buchi, si uniscono tutti i buchi adiacenti per formarne uno più grande.
Questa procedura è una particolare istanza del più generale problema di allocazione dinamica della memoria, che consiste nel soddisfare una richiesta di dimensione n data una lista di buchi liberi. Le soluzioni sono numerose. I criteri più usati per scegliere un buco libero tra quelli disponibili nell’insieme sono i seguenti:
- First-fit. Si assegna il primo buco abbastanza grande. La ricerca può cominciare sia dall’inizio dell’insieme di buchi sia dal punto in cui era terminata la ricerca precedente. Si può fermare la ricerca non appena s’individua un buco libero di dimensioni sufficientemente grandi.
- Best-fit. Si assegna il più piccolo buco in grado di contenere il processo. Si deve compiere la ricerca in tutta la lista, a meno che questa non sia ordinata per dimensione. Tale criterio produce le parti di buco inutilizzate più piccole.
- Worst-fit. Si assegna il buco più grande. Anche in questo caso si deve esaminare tutta la lista, a meno che non sia ordinata per dimensione. Tale criterio produce le parti di buco inutilizzate più grandi, che possono essere più utili delle parti più piccole ottenute col criterio best-fit.
Con l’uso di simulazioni si è dimostrato che sia first-fit sia best-fit sono migliori rispetto a worst-fit in termini di risparmio di tempo e di utilizzo di memoria. D’altra parte nessuno dei due è chiaramente migliore dell’altro per quel che riguarda l’utilizzo della memoria ma, in genere, first-fit è più veloce
Frammentazione
Entrambi i criteri first-fit e best-fit di allocazione della memoria soffrono di frammentazione esterna. Caricando e rimuovendo i processi dalla memoria, si frammenta lo spazio libero della memoria in tante piccole parti. Si ha la frammentazione esterna se lo spazio di memoria totale è sufficiente per soddisfare una richiesta, ma non è contiguo; la memoria è frammentata in tanti piccoli buchi. Questo problema di frammentazione può essere molto grave; nel caso peggiore può verificarsi un blocco di memoria libera, sprecata, tra ogni coppia di processi. Se tutti questi piccoli pezzi di memoria costituissero in un unico blocco libero di grandi dimensioni, si potrebbero eseguire molti più processi.
Sia che si adotti l’uno o l’altro, l’impiego di un determinato criterio può influire sulla quantità di frammentazione: in alcuni sistemi dà migliori risultati il first-fit, in altri dà migliori risultati il best-fit; un altro elemento rilevante è quale sia l’estremità assegnata di un blocco libero (se la parte inutilizzata è quella in alto o quella in basso). A prescindere dal tipo di algoritmo usato, la frammentazione esterna è un problema.
La sua gravità dipende dalla quantità totale di memoria e dalla dimensione media dei processi. L’analisi statistica dell’algoritmo first-fit, per esempio, rivela che, pur con alcune ottimizzazioni, per n blocchi assegnati, si perdono altri 0,5 n blocchi a causa della frammentazione, ciò significa che potrebbe essere inutilizzabile un terzo della memoria. Questa caratteristica è nota come regola del 50 per cento.
La frammentazione può essere interna oltre che esterna. Si consideri uno schema a partizioni multiple con un buco di 18.464 byte. Supponendo che il processo successivo richieda 18.462 byte, assegnando esattamente il blocco richiesto rimane un buco di 2 byte. L’overhead necessario per tener traccia di questo buco è nettamente più grande del buco stesso. Il metodo generale per superare questo problema prevede di suddividere la memoria fisica in blocchi di dimensione fissa, che costituiscono le unità d’allocazione. Con questo metodo la memoria assegnata può essere leggermente maggiore della memoria richiesta. La differenza tra questi due numeri è la frammentazione interna che consiste nella memoria inutilizzata all’interno di una partizione.
Una soluzione al problema della frammentazione esterna è data dalla compattazione. Lo scopo è quello di riordinare il contenuto della memoria per riunire la memoria libera in un unico grosso blocco. La compattazione tuttavia non è sempre possibile: non si può realizzare se la rilocazione è statica ed è effettuata nella fase di assemblaggio o di caricamento; è possibile solo se la rilocazione è dinamica e si effettua nella fase d’esecuzione. Se gli indirizzi sono rilocati dinamicamente, la rilocazione richiede solo lo spostamento del programma e dei dati, e quindi la modifica del registro di rilocazione in modo che rifletta il nuovo indirizzo di base. Quando è possibile eseguire la compattazione, è necessario determinarne il costo. Il più semplice algoritmo di compattazione consiste nello spostare tutti i processi verso un’estremità della memoria: tutti i buchi si spostano nell’altra direzione formando un grosso buco di memoria. Questo metodo può essere assai oneroso.
Un’altra possibile soluzione del problema della frammentazione esterna è data dal consentire la non contiguità dello spazio degli indirizzi logici di un processo, permettendo così di assegnare la memoria fisica ai processi dovunque essa sia disponibile. Questa è la strategia utilizzata nella paginazione, la più comune tecnica di gestione della memoria nei sistemi elaborativi. La paginazione sarà descritta nel paragrafo successivo.
La frammentazione è un problema generale che può verificarsi ogni volta che si opera su blocchi di dati. Questa tematica sarà approfondita ulteriormente nei capitoli sulla gestione della memoria secondaria (dal Capitolo 11 al Capitolo 15)
Paginazione
La gestione della memoria discussa finora richiedeva che lo spazio di indirizzamento fisico di un processo fosse contiguo. Introduciamo ora la paginazione, uno schema di gestione della memoria che consente allo spazio di indirizzamento fisico di un processo di essere non contiguo. La paginazione evita la frammentazione esterna e la necessità di compattazione, due problemi che affliggono l’allocazione di memoria contigua. Visti i numerosi vantaggi offerti, la paginazione, nelle sue varie forme, viene utilizzata nella maggior parte dei sistemi operativi, da quelli destinati a server di grandi dimensioni a quelli per dispositivi mobili. L’implementazione della paginazione è frutto della cooperazione tra il sistema operativo e l’hardware del computer.
Metodo di base
Il metodo di base per implementare la paginazione consiste nel suddividere la memoria fisica in blocchi di dimensione fissa, detti frame, e nel suddividere la memoria logica in blocchi di pari dimensione, detti pagine. Quando si deve eseguire un processo, si caricano le sue pagine nei frame disponibili, prendendole dalla memoria ausiliaria o dal file system. La memoria ausiliaria è divisa in blocchi di dimensione fissa, uguale a quella dei frame della memoria o di blocchi composti da più frame.
Questa idea piuttosto semplice fornisce grandi funzionalità e ha diverse ramificazioni. Per esempio, ora lo spazio degli indirizzi logici è totalmente separato dallo spazio degli indirizzi fisici e dunque un processo può avere uno spazio degli indirizzi logici a 64 bit anche se il sistema ha meno di 2^64 byte di memoria fisica.
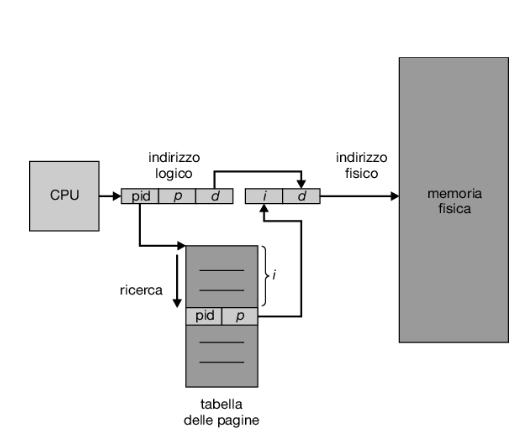
Ogni indirizzo generato dalla cpu è diviso in due parti: un numero di pagina (p), e un offset di pagina (d).
Il numero di pagina serve come indice per la tabella delle pagine relativa al processo (Figura 9.8). La tabella delle pagine contiene l’indirizzo di base di ciascun frame nella memoria fisica e l’offset è la posizione nel frame a cui viene fatto riferimento. Pertanto, l’indirizzo di base del frame viene combinato con l’offset della pagina per definire l’indirizzo di memoria fisica. Il modello di paginazione della memoria è mostrato nella Figura 9.9.
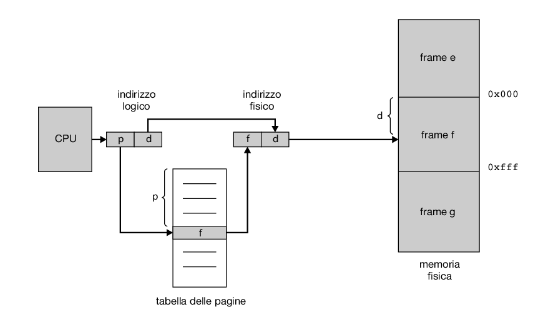

Descriviamo di seguito i passaggi adottati dalla mmu per tradurre un indirizzo logico generato dalla cpu in un indirizzo fisico.
- Estrarre il numero di pagina p e utilizzarlo come indice nella tabella delle pagine.
- Estrarre il numero di frame f corrispondente dalla tabella delle pagine.
- Sostituire il numero di pagina p nell’indirizzo logico con il numero di frame f. L’offset d non cambia e pertanto non viene sostituito; il numero di frame e l’offset determinano insieme l’indirizzo fisico.
La dimensione di una pagina, così come quella di un frame, è definita dall’hardware ed è, in genere, una potenza di 2 compresa tra 4 kb e 1 gb, a seconda dell’architettura. La scelta di una potenza di 2 come dimensione della pagina facilita notevolmente la traduzione di un indirizzo logico nei corrispondenti numero di pagina e offset di pagina. Se la dimensione dello spazio degli indirizzi logici è 2^m e la dimensione di una pagina è di 2^n byte, allora gli m – n bit più significativi di un indirizzo logico indicano il numero di pagina, e gli n bit meno significativi indicano l’offset di pagina. L’indirizzo logico ha quindi la forma seguente:
| Numero di pagina | Offset di pagina |
|---|---|
| p | d |
| m - n | n |
dove p è un indice della tabella delle pagine e d è l’offset all’interno della pagina indicata da p.
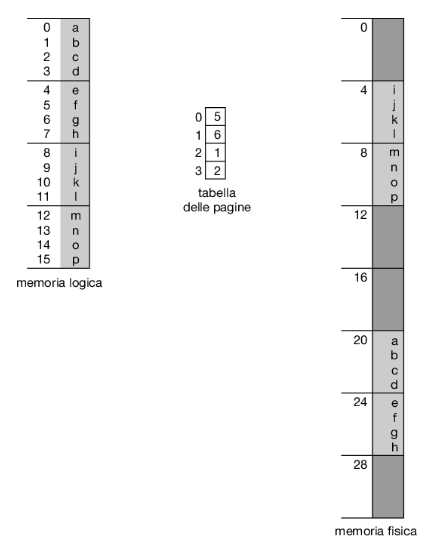
Come esempio concreto, anche se minimo, si consideri la memoria illustrata nella Figura 9.10; qui, nell’indirizzo logico, n = 2 e m = 4. Utilizzando pagine di 4 byte e una memoria fisica di 32 byte (8 pagine), vediamo come si fa corrispondere la memoria vista dal programmatore alla memoria fisica. L’indirizzo logico 0 è la pagina 0 con offset 0. Secondo la tabella delle pagine, la pagina 0 si trova nel frame 5. Quindi all’indirizzo logico 0 corrisponde l’indirizzo fisico 20 [= (5 × 4) + 0]. All’indirizzo logico 3 (pagina 0, offset 3) corrisponde l’indirizzo fisico 23 [= (5 × 4) + 3]. Per quel che riguarda l’indirizzo logico 4 (pagina 1, offset 0), secondo la tabella delle pagine, alla pagina 1 corrisponde il frame 6, quindi, all’indirizzo logico 4 corrisponde l’indirizzo fisico 24 [= (6 × 4) + 0]. All’indirizzo logico 13 corrisponde l’indirizzo fisico 9.
Il lettore può aver notato che la paginazione non è altro che una forma di rilocazione dinamica: a ogni indirizzo logico l’architettura di paginazione fa corrispondere un indirizzo fisico. L’uso della tabella delle pagine è simile all’uso di una tabella di registri base (o di rilocazione), uno per ciascun frame.
Con la paginazione si evita la frammentazione esterna: qualsiasi frame libero si può assegnare a un processo che ne abbia bisogno; tuttavia si può avere la frammentazione interna. I frame si assegnano come unità. Poiché in generale lo spazio di memoria richiesto da un processo non è un multiplo delle dimensioni delle pagine, l’ultimo frame assegnato può non essere completamente pieno. Se, per esempio, le pagine sono di 2048 byte, un processo di 72.766 byte necessita di 35 pagine più 1086 byte. Si assegnano 36 frame, quindi si ha una frammentazione interna di 2048 – 1086 = 962 byte. Il caso peggiore si ha con un processo che necessita di n pagine più un byte: si assegnano n + 1 frame, quindi si ha una frammentazione interna di quasi un intero frame.
Se la dimensione del processo è indipendente dalla dimensione della pagina, si deve prevedere una frammentazione interna media di mezza pagina per processo. Questa considerazione suggerisce che conviene usare pagine di piccole dimensioni; tuttavia, a ogni elemento della tabella delle pagine è associato un overhead che si riduce all’aumentare delle dimensioni delle pagine. Inoltre, con un maggior numero di dati da trasferire, l’i/o su disco è più efficiente (Capitolo 11). Generalmente, nel tempo la dimensione delle pagine è cresciuta col crescere dei processi, dei dati e della memoria centrale; attualmente la dimensione tipica delle pagine è compresa tra 4 kb e 8 kb; in alcuni sistemi può essere anche maggiore. Per esempio, su sistemi x86-64, Windows 10 supporta dimensioni di pagina di 4 kb e 2 mb, mentre Linux supporta una dimensione di pagina predefinita, in genere di 4 kb, e pagine più grandi la cui dimensione dipende dall’architettura, chiamate pagine enormi (huge page).
Spesso, su una cpu a 32 bit, ogni voce della tabella delle pagine è lunga 4 byte, ma questa dimensione può variare. Un singola voce di 32 bit può puntare a uno dei 2^32 frame di pagina fisici. Se la dimensione di un frame è di 4 kb (2^12), un sistema con voci della tabella delle pagine di 4 byte può indirizzare 2^44 byte (o 16 tb) di memoria fisica. Va notato che la dimensione della memoria fisica in un sistema di memoria paginata è differente dalla dimensione logica massima di un processo. Quando analizzeremo ulteriormente la paginazione, introdurremo altre informazioni che devono essere mantenute nelle voci della tabella delle pagine. Queste informazioni riducono il numero di bit disponibili per indirizzare i frame. Un sistema con voci di 32 bit è quindi in grado di indirizzare una quantità di memoria fisica inferiore al valore massimo teoricamente possibile. Una cpu a 32 bit utilizza indirizzi a 32 bit, il che significa che lo spazio di memoria di un processo può essere al massimo di 2^32 byte (4 gb). La paginazione ci consente quindi di utilizzare una memoria fisica che è decisamente più grande rispetto a quella che potrebbe essere indirizzata dalla lunghezza del puntatore agli indirizzi della cpu.
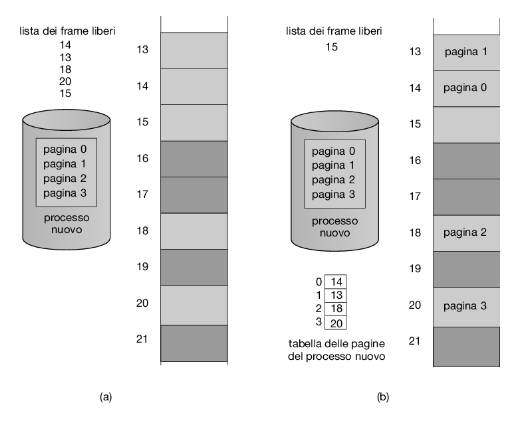
Quando si deve eseguire un processo, il sistema esamina la sua dimensione espressa in pagine. Poiché ogni pagina del processo necessita di un frame, se il processo richiede n pagine, devono essere disponibili almeno n frame che, se ci sono, vengono assegnate al processo. Si carica la prima pagina in uno dei frame assegnati e s’inserisce il numero del frame nella tabella delle pagine relativa al processo in questione. La pagina successiva si carica in un altro frame e, anche in questo caso, s’inserisce il numero del frame nella tabella delle pagine, e così via (Figura 9.11).
Un aspetto importante della paginazione è la netta distinzione tra la memoria vista dal programmatore e l’effettiva memoria fisica: il programmatore vede la memoria come un unico spazio contiguo, contenente solo il programma stesso; in realtà, il programma utente è sparso in una memoria fisica contenente anche altri programmi. La differenza tra la memoria vista dal programmatore e la memoria fisica è colmata dall’hardware di traduzione degli indirizzi, che fa corrispondere gli indirizzi fisici agli indirizzi logici generati dai processi utenti. Questa corrispondenza non è visibile ai programmatori ed è controllata dal sistema operativo. Si noti che un processo utente, per definizione, non può accedere alle zone di memoria che non gli appartengono. Non ha modo di accedere alla memoria oltre quel che è previsto dalla sua tabella delle pagine, e tale tabella contiene soltanto le pagine che appartengono al processo.
Poiché il sistema operativo gestisce la memoria fisica, deve essere informato dei dettagli della allocazione: quali frame sono assegnati, quali sono disponibili, il loro numero totale, e così via. In genere queste informazioni sono contenute in una struttura dati chiamata tabella dei frame, contenente un elemento per ogni frame, indicante se sia libero oppure assegnato e, se è assegnato, a quale pagina di quale processo o di quali processi.
Inoltre, il sistema operativo deve sapere che i processi utenti operano nello spazio utente, e tutti gli indirizzi logici si devono far corrispondere a indirizzi fisici. Se un utente usa una chiamata di sistema (per esempio per eseguire un’operazione di i/o) e fornisce un indirizzo come parametro (per esempio l’indirizzo di un buffer), si deve tradurre questo indirizzo nell’indirizzo fisico corretto. Il sistema operativo conserva una copia della tabella delle pagine per ciascun processo, così come conserva una copia dei valori contenuti nel contatore di programma e nei registri. Questa copia si usa per tradurre gli indirizzi logici in indirizzi fisici ogni volta che il sistema operativo deve associare esplicitamente un indirizzo fisico a un indirizzo logico. La stessa copia è usata anche dal dispatcher della cpu per impostare l’hardware di paginazione quando a un processo sta per essere assegnata la cpu. La paginazione fa quindi aumentare la durata dei cambi di contesto.
Ottenere la dimensione della pagina su sistemi Linux
Su un sistema Linux la dimensione della pagina varia a seconda dell’architettura. Vi sono diversi modi per ottenere le dimensioni della pagina. Un approccio è quello di utilizzare la chiamata di sistema getpagesize(). In alternativa è possibile eseguire da riga di comando:
getconf PAGESIZE
Ciascuna di queste tecniche restituisce la dimensione della pagina espressa in byte.
Supporto hardware alla paginazione
Poiché ogni processo ha la sua tabella delle pagine, un puntatore alla tabella di pagina viene memorizzato insieme ai valori di altri registri (come il puntatore alle istruzioni) nel process control block di ciascun processo. Quando lo scheduler della cpu seleziona un processo per l’esecuzione, deve ricaricare i registri utente e i valori appropriati della tabella delle pagine hardware dalla tabella delle pagine utente memorizzata.
L’implementazione hardware della tabella delle pagine si può realizzare in modi diversi. Nel caso più semplice è implementata come un insieme di registri hardware dedicati ad alta velocità, così da rendere la traduzione dell’indirizzo molto efficiente. Tuttavia, questo approccio aumenta il tempo dei cambi di contesto, poiché durante un cambio di contesto ogni registro dovrà essere scambiato.
L’uso di registri per la tabella delle pagine è efficiente se la tabella stessa è ragionevolmente piccola, nell’ordine, per esempio, di 256 elementi. Però la maggior parte dei calcolatori contemporanei usa tabelle molto grandi, per esempio di un milione di elementi, quindi non si possono impiegare i registri veloci per realizzare la tabella delle pagine; quest’ultima viene invece mantenuta nella memoria principale e un registro di base della tabella delle pagine (page-table base register, ptbr) punta alla tabella stessa. Il cambio della tabelle delle pagine richiede soltanto di modificare questo registro, riducendo considerevolmente il tempo dei cambi di contesto.
Translation Look-aside Buffer (TLB)
La memorizzazione della tabella delle pagine nella memoria principale può favorire cambi di contesto più rapidi, ma può anche comportare tempi di accesso alla memoria più lenti. Supponiamo di voler accedere alla posizione i. Per farlo, occorre far riferimento alla tabella delle pagine usando il valore contenuto nel ptbr aumentato dell’offset relativo alla pagina di i, perciò si deve accedere alla memoria. Si ottiene il numero del frame che, associato all’offset rispetto all’inizio della pagina, produce l’indirizzo cercato; a questo punto è possibile accedere alla posizione di memoria desiderata. Con questo metodo sono necessari due accessi alla memoria per accedere ai dati (uno per l’elemento della tabella delle pagine e uno per il dato effettivo). L’accesso alla memoria è quindi rallentato di un fattore 2, un ritardo considerato intollerabile nella maggior parte delle circostanze.
La soluzione tipica a questo problema consiste nell’impiego del tlb (translation look-aside buffer), una speciale, piccola cache hardware. Il tlb è una memoria associativa ad alta velocità in cui ogni elemento consiste di due parti: una chiave (o tag) e un valore. Quando si presenta un elemento, la memoria associativa lo confronta contemporaneamente con tutte le chiavi; se trova una corrispondenza, riporta il valore correlato. La ricerca è molto rapida e in un hardware moderno è parte della pipeline delle istruzioni: non induce dunque nessuna penalizzazione in termini di prestazioni. Per poter eseguire la ricerca in uno stadio della pipeline, tuttavia, il tlb deve essere di dimensioni ridotte, in genere contenute tra le 32 e le 1.024 voci. Alcune cpu implementano tlb separate per istruzioni e dati, in modo da poter raddoppiare il numero di voci tlb disponibili, poiché le due ricerche vengono effettuate in diversi stadi della pipeline. Questo sviluppo rappresenta un esempio di evoluzione della tecnologia delle cpu: i sistemi si sono evoluti passando dall’assenza di tlb fino ad avere più livelli di tlb, proprio come nel caso delle cache.
Il tlb si usa insieme con le tabelle delle pagine nel modo seguente: il tlb contiene una piccola parte degli elementi della tabella delle pagine; quando la cpu genera un indirizzo logico, si presenta il suo numero di pagina al tlb; se tale numero è presente, il corrispondente numero del frame è immediatamente disponibile e si usa per accedere alla memoria. Come abbiamo appena menzionato, queste operazioni vengono eseguite come parte della pipeline delle istruzioni all’interno della cpu, senza penalizzare il sistema rispetto ad altri sistemi che non implementano la paginazione.
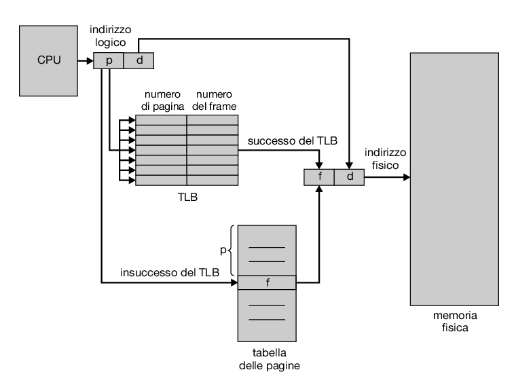
Se nel tlb non è presente il numero di pagina, situazione nota come insuccesso del tlb (tlb miss), si deve consultare la tabella delle pagine in memoria (i passi da seguire sono illustrati nel Paragrafo 9.3.1). A seconda della cpu, questa operazione può essere effettuata automaticamente a livello hardware oppure per mezzo di un interrupt al sistema operativo. Il numero del frame così ottenuto viene usato per accedere alla memoria (Figura 9.12). Inoltre, i numeri della pagina e del frame vengono inseriti nel tlb, e al riferimento successivo la ricerca sarà molto più rapida.
Se il tlb è già pieno d’elementi, occorre sceglierne uno per sostituirlo. I criteri di sostituzione variano dalla scelta dell’elemento usato meno recentemente (lru), a una politica round-robin, fino alla scelta casuale. Alcune cpu permettono al sistema operativo di partecipare alla sostituzione lru di elementi, mentre altre gestiscono in autonomia questa operazione. Inoltre alcuni tlb consentono che certi elementi siano vincolati (wired down), cioè non si possano rimuovere dal tlb; in genere si vincolano gli elementi per il codice chiave del kernel.
Alcuni tlb memorizzano gli identificatori dello spazio d’indirizzi (address-space identifier, asid) in ciascun elemento del tlb. Un asid identifica in modo univoco ciascun processo e si usa per fornire al processo corrispondente la protezione del suo spazio d’indirizzi. Quando tenta di trovare i valori corrispondenti ai numeri delle pagine virtuali, il tlb si assicura che l’asid per il processo attualmente in esecuzione corrisponda all’asid associato alla pagina virtuale. La mancata corrispondenza dell’asid viene trattata come un tlb miss. Oltre a fornire la protezione dello spazio d’indirizzi, l’asid consente che il tlb contenga nello stesso istante elementi di diversi processi. Se il tlb non permette l’uso di asid distinti, ogni volta che si seleziona una nuova tabella delle pagine, per esempio a ogni cambio di contesto, si deve cancellare (flush) il tlb, in modo da assicurare che il successivo processo in esecuzione non faccia uso di errate informazioni di traduzione. Potrebbero altrimenti esserci vecchi elementi del tlb contenenti indirizzi virtuali validi, ma con indirizzi fisici corrispondenti sbagliati o non validi, lasciati dal precedente processo.
La percentuale di volte che il numero di pagina di interesse si trova nel tlb è detta tasso di successi (hit ratio). Un tasso di successi dell’80 per cento significa che il numero di pagina desiderato si trova nel tlb nell’80 per cento dei casi. Se sono necessari 10 nanosecondi per accedere alla memoria, allora un accesso alla memoria mappata nel tlb richiede 10 nanosecondi. Se, invece, il numero non è contenuto nel tlb, occorre accedere alla memoria per arrivare alla tabella delle pagine e al numero del frame (10 nanosecondi), quindi accedere al byte desiderato in memoria (10 nanosecondi); in totale sono necessari 20 nanosecondi. Stiamo in questo caso supponendo che una ricerca nella tabella delle pagine richieda un solo accesso alla memoria, ma, come vedremo in seguito, potrebbero talvolta essere necessari più accessi. Per calcolare il tempo effettivo d’accesso alla memoria occorre tener conto della probabilità dei due casi:
- tempo effettivo d’accesso = 0,80 × 10 + 0,20 × 20 = 12 nanosecondi In questo esempio si verifica un rallentamento del 20 per cento nel tempo medio d’accesso alla memoria (da 10 a 12 nanosecondi). Per un tasso di successi del 99 per cento, molto più realistico, si ottiene il seguente risultato:
- tempo effettivo d’accesso = 0,99 × 10 + 0,01 × 20 = 10,1 nanosecondi Con questo tasso di successi, il rallentamento del tempo d’accesso alla memoria scende all’1 per cento.
Come abbiamo osservato in precedenza, le cpu di oggi possono fornire più livelli di tlb. Il calcolo dei tempi di accesso alla memoria nelle cpu moderne diventa quindi molto più complicato di quanto illustrato nell’esempio precedente. Per esempio, la cpu Intel Core i7 ha un tlb L1 da 128 elementi per le istruzioni e un tlb L1 da 64 elementi per i dati. In caso di insuccesso sul tlb L1, sono necessari sei cicli di cpu per cercare la voce sul tlb L2 da 512 elementi. Un insuccesso sul tlb L2 significa che la cpu deve attraversare le voci della tabella delle pagine in memoria per trovare l’indirizzo del frame associato, il che può richiedere centinaia di cicli, oppure generare un’interruzione per il sistema operativo affinché esegua lo stesso lavoro.
Un’analisi completa delle prestazioni in un tale sistema richiederebbe informazioni sul tasso di insuccesso di ogni livello di tlb. Da quanto abbiamo detto possiamo tuttavia dedurre che le caratteristiche hardware possono condizionare in maniera significativa le prestazioni della memoria e che le migliorie al sistema operativo (come la paginazione) possono indurre modifiche hardware e, a loro volta, essere da queste influenzate (come nel caso del tlb). L’impatto del tasso di successi nel tlb è ulteriormente analizzato nel Capitolo 10.
I tlb sono una caratteristica hardware e in quanto tali potrebbero sembrare di scarso interesse per i sistemi operativi e i loro progettisti. I progettisti, tuttavia, hanno bisogno di capire la funzione e le caratteristiche dei tlb, che variano a seconda della piattaforma hardware. Per un funzionamento ottimale, il progetto di un sistema operativo per una data piattaforma deve implementare la paginazione basandosi sul progetto dei tlb della piattaforma. Analogamente, un cambiamento nel progetto del tlb (per esempio, tra generazioni diverse di cpu Intel) può rendere necessaria una modifica nell’implementazione della paginazione dei sistemi operativi che utilizzano questa tecnica.
Protezione
In un ambiente paginato, la protezione della memoria è assicurata dai bit di protezione associati a ogni frame; normalmente tali bit si trovano nella tabella delle pagine.
Un bit può determinare se una pagina si può leggere e scrivere oppure soltanto leggere. Tutti i riferimenti alla memoria passano attraverso la tabella delle pagine per trovare il numero corretto del frame; quindi mentre si calcola l’indirizzo fisico, si possono controllare i bit di protezione per verificare che non si scriva in una pagina di sola lettura. Un tale tentativo causerebbe la generazione di un’eccezione hardware per il sistema operativo, si avrebbe cioè una violazione della protezione della memoria.
Questo metodo si può facilmente estendere per fornire un livello di protezione più perfezionato. Si può progettare un hardware che fornisca la protezione di sola lettura, di sola scrittura o di sola esecuzione. In alternativa, con bit di protezione distinti per ogni tipo d’accesso, si può ottenere una qualsiasi combinazione di tali tipi d’accesso; i tentativi illegali causano la generazione di un’eccezione per il sistema operativo.
Di solito si associa a ciascun elemento della tabella delle pagine un ulteriore bit, detto bit di validità. Tale bit, impostato a valido, indica che la pagina corrispondente è nello spazio d’indirizzi logici del processo, quindi è una pagina valida; impostato a non valido, indica che la pagina non è nello spazio d’indirizzi logici del processo. Il bit di validità consente quindi di riconoscere gli indirizzi illegali e di notificarne la presenza attraverso un’eccezione. Il sistema operativo concede o impedisce l’accesso a una pagina impostando in modo appropriato tale bit.
Per esempio, supponiamo che in un sistema con uno spazio di indirizzi di 14 bit (da 0 a 16.383) si abbia un programma che deve usare soltanto gli indirizzi da 0 a 10.468. Con una dimensione delle pagine di 2 kb si ha la situazione mostrata nella Figura 9.13. Gli indirizzi nelle pagine 0, 1, 2, 3, 4 e 5 sono tradotti normalmente tramite la tabella delle pagine. D’altra parte, ogni tentativo di generare un indirizzo nelle pagine 6 o 7 trova non valido il bit di validità; in questo caso il calcolatore invia un’eccezione al sistema operativo (riferimento di pagina non valido).
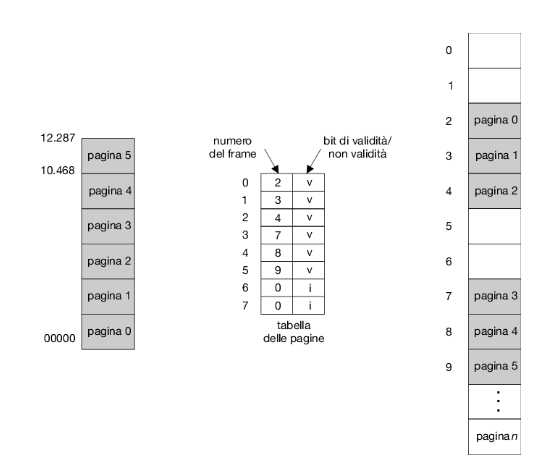
Questo schema ha creato un problema: poiché il programma si estende solo fino all’indirizzo 10.468, ogni riferimento oltre tale indirizzo è illegale; i riferimenti alla pagina 5 sono tuttavia classificati come validi, e ciò rende validi gli accessi sino all’indirizzo 12.287; solo gli indirizzi da 12.288 a 16.383 sono non validi. Tale problema è dovuto alla dimensione delle pagine di 2 kb e corrisponde alla frammentazione interna della paginazione.
Capita raramente che un processo faccia uso di tutto il suo intervallo di indirizzi, infatti molti processi utilizzano solo una piccola frazione dello spazio d’indirizzi di cui dispongono. In questi casi è un inutile spreco creare una tabella di pagine con elementi per ogni pagina dell’intervallo di indirizzi, poiché una gran parte di questa tabella resta inutilizzata e occupa prezioso spazio di memoria. Alcune architetture dispongono di registri, detti registri di lunghezza della tabella delle pagine (page-table length register, ptlr), per indicare le dimensioni della tabella. Questo valore si controlla rispetto a ogni indirizzo logico per verificare che quest’ultimo si trovi nell’intervallo valido per il processo. Un errore causa la generazione di un’eccezione per il sistema operativo.
Pagine condivise
Un vantaggio della paginazione risiede nella possibilità di condividere codice comune, il che è particolarmente importante in un ambiente con più processi. Si consideri la libreria standard del C, che fornisce parte dell’interfaccia alla chiamata di sistema in molte versioni di unix e Linux. Su un tipico sistema Linux, la maggior parte dei processi utente richiede la libreria standard del C libc. Un’opzione percorribile è che ogni processo carichi la propria copia di libc nel proprio spazio di indirizzamento. Se un sistema ha 40 processi utente e la libreria libc è di 2 mb, ciò richiederebbe 80 mb di memoria.
Se il codice è rientrante può però essere condiviso, come illustrato nella Figura 9.14, dove si osservano tre processi che condividono le pagine della libreria libc (anche se la figura mostra che la libreria libc occupa quattro pagine, nella realtà ne occuperebbe di più). Il codice rientrante è un codice non auto-modificante: non cambia mai durante l’esecuzione. Due o più processi possono quindi eseguire lo stesso codice allo stesso tempo. Ogni processo dispone di una propria copia dei registri e di una memoria dove conserva i dati necessari per la propria esecuzione. I dati per due diversi processi saranno, ovviamente, diversi. Solo una copia della libreria standard del C deve essere conservata nella memoria fisica e la tabella delle pagine di ogni processo utente viene mappata sulla stessa copia fisica di libc. Quindi, per supportare 40 processi, abbiamo bisogno di una sola copia della libreria, e lo spazio totale ora richiesto è di 2 mb anziché di 80 mb: un risparmio significativo!
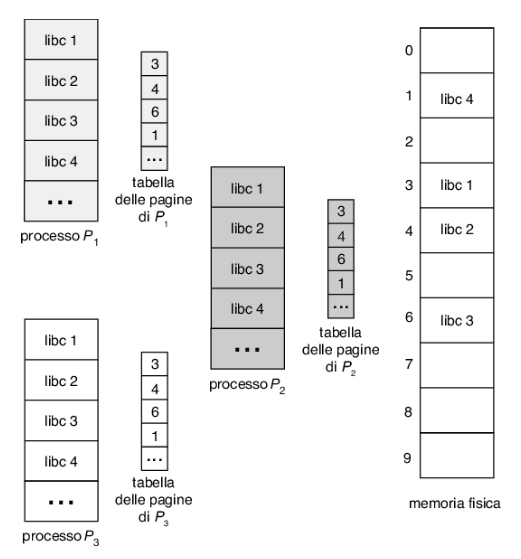
Oltre alle librerie di run-time come libc, altri programmi d’uso frequente possono essere condivisi: compilatori, interfacce a finestre, sistemi di database e così via. Le librerie condivise discusse nel Paragrafo 9.1.5 sono in genere implementate con pagine condivise. Per poter essere condiviso, il codice deve essere rientrante. La natura di sola lettura del codice condiviso non deve essere lasciata alla correttezza intrinseca del codice, ma deve essere fatta rispettare dal sistema operativo.
La condivisione della memoria tra processi di un sistema è simile al modo in cui i thread condividono lo spazio d’indirizzi di un task (Capitolo 4). Inoltre con riferimento al Capitolo 3, dove si descrive la memoria condivisa come un metodo di comunicazione tra processi, alcuni sistemi operativi realizzano la memoria condivisa impiegando le pagine condivise.
Oltre a permettere che più processi condividano le stesse pagine fisiche, l’organizzazione della memoria in pagine offre numerosi altri vantaggi; ne vedremo alcuni nel Capitolo 10.
Struttura della tabella delle pagine
In questo paragrafo si descrivono alcune tra le tecniche più comuni per strutturare la tabella delle pagine: la paginazione gerarchica, la tabella delle pagine di tipo hash e la tabella delle pagine invertita.
Paginazione gerarchica
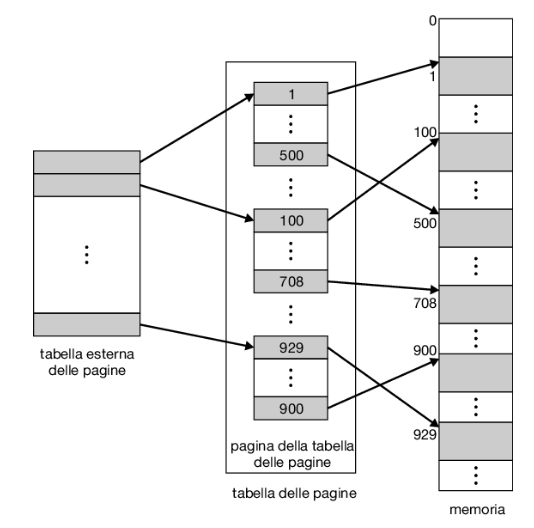
La maggior parte dei moderni calcolatori dispone di uno spazio d’indirizzi logici molto grande (da 2^32 a 2^64 elementi). In un ambiente di questo tipo la stessa tabella delle pagine diventa eccessivamente grande. Si consideri, per esempio, un sistema con uno spazio d’indirizzi logici a 32 bit. Se la dimensione di ciascuna pagina è di 4 kb (2^12), la tabella delle pagine potrebbe arrivare a contenere fino a 1 milione di elementi (2^32/2^12). Se ogni elemento consiste di 4 byte, ciascun processo potrebbe richiedere fino a 4 mb di spazio fisico d’indirizzi solo per la tabella delle pagine. Chiaramente, sarebbe meglio evitare di collocare la tabella delle pagine in modo contiguo in memoria centrale. Una semplice soluzione a questo problema consiste nel suddividere la tabella delle pagine in parti più piccole; questo risultato si può ottenere in molti modi.
Un metodo consiste nell’adottare un algoritmo di paginazione a due livelli, in cui la tabella stessa è paginata (Figura 9.15). Si consideri il precedente esempio di macchina a 32 bit con dimensione delle pagine di 4 kb. Ciascun indirizzo logico è suddiviso in un numero di pagina di 20 bit e in un offset di pagina di 12 bit. Paginando la tabella delle pagine, anche il numero di pagina è a sua volta suddiviso in un numero di pagina di 10 bit e un offset di pagina di 10 bit. Quindi, l’indirizzo logico è strutturato come segue:
| Numero di pagina (p1 p2) | Offset di pagina (d) |
|---|---|
| 10 10 | 12 |
dove p1 è un indice della tabella delle pagine di primo livello, o tabella esterna delle pagine, e p2 è l’offset all’interno della pagina indicata dalla tabella esterna delle pagine. Il metodo di traduzione degli indirizzi seguito da questa architettura è mostrato nella Figura 9.16. Poiché la traduzione degli indirizzi si svolge dalla tabella esterna delle pagine verso l’interno, questo metodo è anche noto come tabella delle pagine ad associazione diretta (forward-mapped page table).
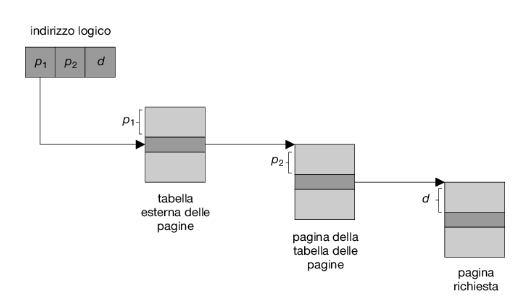
Lo schema di paginazione a due livelli non è più adatto nel caso di sistemi con uno spazio di indirizzi logici a 64 bit. Per spiegare questo aspetto, si supponga che la dimensione delle pagine di questo sistema sia di 4 kb (2^12). In questo caso, la tabella delle pagine conterrà fino a 2^52 elementi. Adottando uno schema di paginazione a due livelli, le tabelle interne delle pagine possono occupare convenientemente una pagina, o contenere 2^10 elementi di 4 byte. Gli indirizzi si presentano come segue:
| Pagina esterna (p1) | Pagina interna (p2) | Offset |
|---|---|---|
| 42 | 10 | 12 |
La tabella esterna delle pagine consiste di 2^42 elementi, o 2^44 byte. La soluzione ovvia per evitare una tabella tanto grande consiste nel suddividere la tabella in parti più piccole. Questo metodo si adotta anche in alcuni processori a 32 bit allo scopo di fornire una maggiore flessibilità ed efficienza.
La tabella esterna delle pagine si può suddividere in vari modi. Per esempio, si può paginare la tabella esterna delle pagine, ottenendo uno schema di paginazione a tre livelli. Si supponga che la tabella esterna delle pagine sia costituita di pagine di dimensione ordinaria (2^10 elementi, o 2^12 byte); uno spazio d’indirizzi a 64 bit è ancora enorme:
| Seconda pagina esterna p1 | Pagina esterna p2 | Pagina interna p3 | Offset |
|---|---|---|---|
| 32 | 10 | 10 | 12 |
La tabella esterna delle pagine è ancora di 2^34 byte (16 gb).
Il passo successivo sarebbe uno schema di paginazione a quattro livelli, in cui si pagina anche la tabella esterna di secondo livello delle pagine, e così via. L’Ultrasparc a 64 bit richiederebbe sette livelli di paginazione – con un numero proibitivo di accessi alla memoria – per tradurre ciascun indirizzo logico. Da questo esempio è possibile capire perché, per le architetture a 64 bit, le page table gerarchiche sono in genere considerate inappropriate.
Tabelle delle pagine di tipo hash
Un metodo di gestione molto comune degli spazi d’indirizzi oltre i 32 bit consiste nell’impiego di una tabella delle pagine di tipo hash, in cui l’argomento della funzione hash è il numero della pagina virtuale. Per la gestione delle collisioni, ogni elemento della tabella hash contiene una lista concatenata di elementi che la funzione hash fa corrispondere alla stessa locazione. Ciascun elemento è composto da tre campi: (1) il numero della pagina virtuale; (2) l’indirizzo del frame corrispondente alla pagina virtuale; (3) un puntatore al successivo elemento della lista.
L’algoritmo opera come segue: si applica la funzione hash al numero della pagina virtuale contenuto nell’indirizzo virtuale, identificando un elemento della tabella. Si confronta il numero di pagina virtuale con il campo (1) del primo elemento della lista concatenata corrispondente. Se i valori coincidono, si usa l’indirizzo del relativo frame (campo 2) per generare l’indirizzo fisico desiderato. Altrimenti, l’algoritmo esamina allo stesso modo gli elementi successivi della lista concatenata:
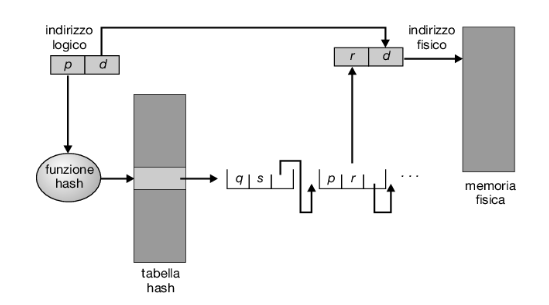
Per questo schema è stata proposta una variante, adatta a spazi di indirizzamento a 64 bit. Si tratta della tabella delle pagine a gruppi (clustered page table), simile alla tabella delle pagine di tipo hash; la differenza è che ciascun elemento della tabella hash contiene i riferimenti alle pagine fisiche corrispondenti a un gruppo di pagine virtuali contigue (per esempio 16). Le tabelle delle pagine a gruppi sono particolarmente utili per gli spazi d’indirizzi sparsi, in cui i riferimenti alla memoria non sono contigui ma distribuiti per tutto lo spazio d’indirizzi.
Tabella delle pagine invertita
Generalmente, si associa una tabella delle pagine a ogni processo e tale tabella contiene un elemento per ogni pagina virtuale che il processo sta utilizzando, ossia vi sono elementi corrispondenti a ogni indirizzo virtuale a prescindere dalla validità di quest’ultimo. Questa rappresentazione tabellare è naturale, poiché i processi fanno riferimento alle pagine tramite gli indirizzi virtuali delle pagine stesse, che il sistema operativo deve poi tradurre in indirizzi di memoria fisica. Poiché la tabella è ordinata per indirizzi virtuali, il sistema operativo può calcolare in che punto della tabella si trova l’indirizzo fisico associato, e usare direttamente tale valore. Uno degli inconvenienti insiti in questo metodo è che ciascuna tabella delle pagine può contenere milioni di elementi e occupare grandi quantità di memoria fisica, necessaria solo per sapere com’è impiegata la rimanente memoria fisica.
Per risolvere questo problema si può fare uso della tabella delle pagine invertita. Una tabella delle pagine invertita ha un elemento per ogni pagina reale (o frame). Ciascun elemento è quindi costituito dell’indirizzo virtuale della pagina memorizzata in quella reale locazione di memoria, con informazioni sul processo che possiede tale pagina. Quindi, nel sistema esiste una sola tabella delle pagine che ha un solo elemento per ciascuna pagina di memoria fisica. Nella Figura 9.18 sono mostrate le operazioni di una tabella delle pagine invertita; si confronti questa figura con la Figura 9.8, che illustra il modo di operare per una tabella delle pagine ordinaria. Le tabelle invertite richiedono spesso la memorizzazione di un identificatore dello spazio d’indirizzi (Paragrafo 9.3.2) in ciascun elemento della tabella delle pagine, perché essa contiene di solito molti spazi d’indirizzi diversi associati alla memoria fisica; l’identificatore garantisce che una data pagina logica relativa a un certo processo sia associata alla pagina fisica corrispondente. Esempi di sistemi che usano le tabelle delle pagine invertite sono l’Ultrasparc a 64 bit e il Powerpc.
Oracle SPARC Solaris
Consideriamo come ultimo esempio una moderna cpu a 64 bit e un sistema operativo strettamente integrati tra loro per fornire una memoria virtuale a basso overhead. Il sistema Solaris in esecuzione sulla cpu sparc è un sistema operativo completamente a 64 bit e come tale deve risolvere il problema della memoria virtuale senza esaurire tutta la sua memoria fisica, mantenendo livelli multipli di tabelle delle pagine. L’approccio di Solaris è piuttosto complesso, ma risolve il problema in modo efficiente utilizzando tabelle delle pagine di tipo hash. Vi sono due tabelle hash, una per il kernel e una per tutti i processi utente. Ogni tabella mappa indirizzi di memoria virtuale nella memoria fisica. Ogni elemento della tabella hash rappresenta un’area contigua di memoria virtuale mappata, il che è più efficiente rispetto ad avere voci separate per ciascuna pagina. Ogni voce ha un indirizzo di base e un intervallo (span) che indica il numero di pagine rappresentate da quella voce.
La traduzione da virtuale a fisico impiegherebbe troppo tempo se ogni indirizzo richiedesse la ricerca attraverso una tabella hash, quindi la cpu implementa un tlb che contiene le voci della tabella di traduzione (tte), in modo da offrire ricerche hardware rapide. Una cache di queste tte risiede in un buffer di memoria di traduzione (tsb), che include una voce per ogni pagina di recente accesso. In caso di riferimento a un indirizzo virtuale, l’hardware interroga il tlb per una traduzione. Se non vengono trovate traduzioni, l’hardware scorre il buffer tsb in cerca della tte che corrisponde all’indirizzo virtuale che ha causato la ricerca. Questa funzionalità, chiamata tlb walk, è presente su molte cpu moderne. Se viene trovata una corrispondenza nel tsb, la cpu copia la voce tsb nel tlb, e la traduzione viene completata. Se invece non viene trovata alcuna corrispondenza, viene interrotto il kernel per effettuare una ricerca nella tabella hash. Il kernel crea quindi una tte dalla tabella hash appropriata e la memorizza nel tsb affinché l’unità di gestione della memoria della cpu possa effettuare il caricamento automatico nel tlb. Infine, il gestore di interrupt restituisce il controllo alla mmu, che completa la conversione dell’indirizzo e recupera il byte o la parola richiesta dalla memoria principale.
Swapping dei processi
Le istruzioni di un processo e i dati su cui operano per essere eseguiti devono essere in memoria. Tuttavia, un processo, o una sua parte, può essere rimosso temporaneamente dalla memoria centrale (mediante un’operazione detta di swap out, scaricamento), spostato in una memoria ausiliaria (backing store) e in seguito riportato in memoria (swap in, caricamento) per continuare la sua esecuzione (Figura 9.19). Grazie a questo procedimento, detto avvicendamento dei processi o swapping, lo spazio totale degli indirizzi fisici di tutti i processi può eccedere la reale dimensione della memoria fisica del sistema, aumentando così il grado di multiprogrammazione possibile.
Swapping standard
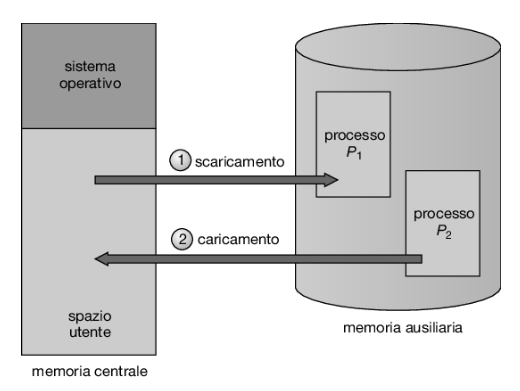
L’avvicendamento standard riguarda lo spostamento di interi processi tra la memoria centrale e una memoria ausiliaria solitamente costituita da un veloce dispositivo di memorizzazione secondaria. Tale memoria deve essere abbastanza ampia da contenere tutte le porzioni dei processi che devono essere memorizzate e recuperate, e deve fornire accesso diretto alle immagini dei processi memorizzati. Quando un processo, o una sua parte, viene spostato nella memoria ausiliaria, devono essere scritte in tale memoria anche le strutture dati associate al processo. In un processo multithread devono essere spostate anche tutte le strutture dati relative a ogni thread. Il sistema operativo deve inoltre conservare i metadati relativi ai processi che sono stati spostati, in modo da poterli ripristinare quando i processi vengono reinseriti nella memoria.
Il vantaggio dell’avvicendamento standard è che consente di sovrascrivere la memoria fisica, in modo che il sistema possa ospitare più processi rispetto alla quantità di memoria fisica effettivamente a disposizione. I processi inattivi o raramente attivi sono buoni candidati per l’avvicendamento e la memoria allocata a questi processi inattivi può quindi essere destinata ai processi attivi. Se un processo inattivo che è stato rimosso dalla memoria centrale diventa di nuovo attivo, deve essere riportato in memoria e ripristinato.
Avvicendamento con paginazione
L’avvicendamento standard è stato utilizzato nei sistemi unix tradizionali, ma in genere non è più utilizzato nei sistemi operativi contemporanei, poiché la quantità di tempo necessaria per spostare interi processi tra la memoria centrale e la memoria ausiliaria è proibitiva (un’eccezione è costituita da Solaris, che usa ancora l’avvicendamento standard, anche se solo in circostanze estreme in cui la memoria disponibile è estremamente bassa).
La maggior parte dei sistemi, inclusi Linux e Windows, usa ora una variante dell’avvicendamento standard in cui è possibile spostare solo alcune pagine di un processo, piuttosto che l’intero processo. Questa strategia consente tuttavia di sovrascrivere la memoria fisica, ma non comporta il costo dello spostamento di interi processi, poiché presumibilmente solo un numero limitato di pagine sarà coinvolto nello scambio. Al giorno d’oggi, generalmente, si utilizza il termine avvicendamento (o swapping) per riferirsi all’avvicendamento standard, mentre quando si parla di paginazione (o paging) si fa riferimento all’avvicendamento con paginazione.
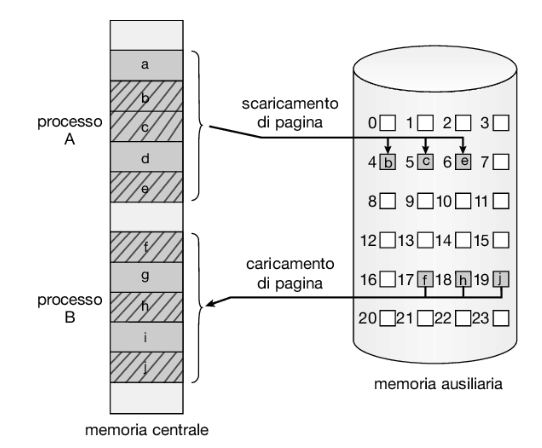
Un’operazione di page out (scaricamento della pagina) sposta una pagina dalla memoria centrale alla memoria ausiliaria, mentre il processo inverso è noto come page in (caricamento della pagina). L’avvicendamento con paginazione è illustrato nella Figura 9.20, dove su un sottoinsieme delle pagine dei processi A e B viene effettuata un’operazione, rispettivamente, di page out e page in. Come vedremo nel Capitolo 10, l’avvicendamento con paginazione funziona bene in abbinamento alla memoria virtuale.
Avvicendamento di processi nei sistemi mobili
La maggior parte dei sistemi operativi per pc e server supporta l’avvicendamento con paginazione. Al contrario, i sistemi mobili in genere non supportano alcuna forma di avvicendamento. I dispositivi mobili utilizzano infatti solitamente la memoria flash per la memorizzazione non volatile, anziché i più capienti dischi rigidi: il vincolo di spazio che ne risulta è uno dei motivi per cui i progettisti di sistemi operativi mobili evitano l’avvicendamento. Altri motivi includono il numero limitato di scritture che la memoria flash può tollerare prima di diventare inaffidabile e la scarsa velocità di trasferimento tra la memoria principale e la memoria flash su quel tipo di dispositivo.
Invece di usare l’avvicendamento dei processi, se la memoria disponibile scende al di sotto di una certa soglia, ios di Apple chiede alle applicazioni di rinunciare volontariamente alla memoria allocata. I dati di sola lettura (come il codice) vengono rimossi dal sistema e successivamente ricaricati dalla memoria flash, se necessario. I dati che sono stati modificati (per esempio lo stack) non vengono rimossi. Tuttavia, tutte le applicazioni che non riescono a liberare memoria a sufficienza possono essere terminate dal sistema operativo.
Android non supporta l’avvicendamento e adotta una strategia simile a quella utilizzata da ios. Anche Android può terminare un processo qualora la memoria libera disponibile non sia sufficiente. Tuttavia, prima di terminarlo, scrive lo stato dell’applicazione (application state) nella memoria flash, in modo che il processo possa essere rapidamente riavviato.
A causa di queste limitazioni, gli sviluppatori per dispositivi mobili devono allocare e rilasciare memoria con molta cura, in modo da garantire che le loro applicazioni non utilizzino troppa memoria e non soffrano di memory leak (“perdite di memoria”).
Prestazioni di un sistema in caso di avvicendamento
Anche se l’avvicendamento di pagine è più efficiente dell’avvicendamento di interi processi, quando un sistema è sottoposto a qualsiasi forma di avvicendamento è spesso segno che ci sono più processi attivi rispetto alla memoria fisica disponibile. Esistono generalmente due approcci per gestire questa situazione: (1) terminare alcuni processi o (2) acquistare più memoria fisica!
Esempio: architetture Intel a 32 e 64 bit
L’architettura Intel ha dominato il mondo dei personal computer per diversi anni. Il processore Intel 8086, a 16 bit, apparve alla fine degli anni ’70 e fu presto seguito da un altro chip a 16 bit, l’Intel 8088, noto per essere stato il chip utilizzato nel pc ibm originale. Sia il chip 8086 che il chip 8088 erano basati su una architettura segmentata. Più tardi Intel iniziò la produzione di una serie di chip a 32 bit, ia-32, che includeva la famiglia di processori Pentium. L’architettura ia-32 supportava paginazione e segmentazione. Più di recente Intel ha prodotto una serie di chip a 64 bit basati sull’architettura x86-64. Attualmente tutti i più popolari sistemi operativi per pc, tra cui Windows, macos e Linux (anche se Linux, ovviamente, gira su diverse altre architetture), vengono eseguiti su chip Intel. Va notato tuttavia che la posizione dominante di Intel non si è propagata ai sistemi mobili, su cui attualmente gode di notevole successo l’architettura arm (si veda il Paragrafo 9.7).
In questo paragrafo esaminiamo la traduzione degli indirizzi nelle architetture ia-32 e x86-64. Prima di procedere è importante osservare che, poiché Intel ha rilasciato diverse versioni e diverse varianti delle sue architetture nel corso degli anni, non possiamo fornire una descrizione completa della struttura di gestione della memoria per tutti i suoi chip. Non è nemmeno nostra intenzione fornire tutti i dettagli della cpu, perché questi argomenti vengono trattati nei libri di architettura degli elaboratori. Quello che faremo, piuttosto, è di presentare i principali concetti della gestione della memoria di queste cpu Intel.
Architettura IA-32
La gestione della memoria nei sistemi ia-32 è suddivisa in due componenti: segmentazione e paginazione. La cpu genera indirizzi logici che vengono passati all’unità di segmentazione. L’unità di segmentazione produce un indirizzo lineare per ogni indirizzo logico. L’indirizzo lineare viene quindi passato all’unità di paginazione, che genera l’indirizzo fisico nella memoria principale. Dunque, l’unità di segmentazione e l’unità di paginazione formano insieme l’equivalente dell’unità di gestione della memoria (mmu).

Segmentazione in IA-32
Nell’architettura ia-32 un segmento può raggiungere la dimensione massima di 4 gb; il numero massimo di segmenti per processo è pari a 16 k. Lo spazio degli indirizzi logici di un processo è composto da due partizioni: la prima contiene fino a 8 k segmenti riservati al processo; la seconda contiene fino a 8 k segmenti condivisi fra tutti i processi. Le informazioni riguardanti la prima partizione sono contenute nella tabella locale dei descrittori (local descriptor table, ldt), quelle relative alla seconda partizione sono memorizzate nella tabella globale dei descrittori (global descriptor table, gdt). Ciascun elemento nella ldt e nella gdt è lungo 8 byte e contiene informazioni dettagliate riguardanti uno specifico segmento, oltre agli indirizzi base e limite.
Un indirizzo logico è una coppia (selettore, offset), dove il selettore è un numero di 16 bit:
- s: 13 bit
- 8: 1 bit
- p: 2 bit in cui s indica il numero del segmento, g indica se il segmento si trova nella gdt o nella ldt e p contiene informazioni relative alla protezione. L’offset è un numero di 32 bit che indica la posizione del byte (o della parola) all’interno del segmento in questione.
La macchina ha sei registri di segmento che consentono a un processo di far riferimento contemporaneamente a sei segmenti; inoltre possiede sei registri di microprogramma di 8 byte per i corrispondenti descrittori prelevati dalla ldt o dalla gdt. Questa cache evita alla macchina di dover prelevare dalla memoria i descrittori per ogni riferimento alla memoria.
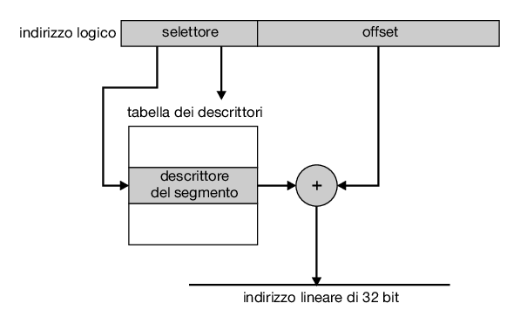
Un indirizzo lineare di ia-32 è lungo 32 bit e si genera come segue. Il registro di segmento punta all’elemento appropriato all’interno della ldt o della gdt; le informazioni relative alla base e al limite di tale segmento si usano per generare un indirizzo lineare. Innanzi tutto si usa il valore del limite per controllare la validità dell’indirizzo; se non è valido, si ha un errore di riferimento alla memoria che causa la generazione di un’eccezione e la restituzione del controllo al sistema operativo; altrimenti, si somma il valore dell’offset al valore della base, ottenendo un indirizzo lineare di 32 bit. La Figura 9.22 illustra tale processo. Nel paragrafo successivo si considera come l’unità di paginazione trasforma questo indirizzo lineare in un indirizzo fisico.
Paginazione in IA-32
L’architettura ia-32 prevede che le pagine abbiano una misura di 4 kb oppure di 4 mb. Per le pagine di 4 kb, in ia-32 vige uno schema di paginazione a due livelli che prevede la seguente scomposizione degli indirizzi lineari a 32 bit:
- Numero di pagina p1: 10 bit
- Numero di pagina p2: 10 bit
- Offset di pagina d: 12
Lo schema di traduzione degli indirizzi per questa architettura, simile a quello rappresentato nella Figura 9.16, è mostrato in dettaglio nella Figura 9.23. I dieci bit più significativi puntano a un elemento nella tabella delle pagine più esterna, detta in ia-32 directory delle pagine. (Il registro cr3 punta alla directory delle pagine del processo corrente.) Gli elementi della directory delle pagine puntano a una tabella delle pagine interne, indicizzata da dieci bit intermedi dell’indirizzo lineare. Infine, i bit meno significativi in posizione 0-11 contengono l’offset da applicare all’interno della pagina di 4 kb cui si fa riferimento nella tabella delle pagine.
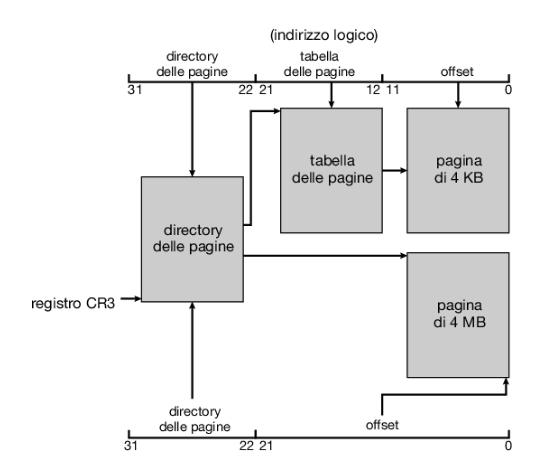
Un elemento appartenente alla directory delle pagine è il flag Page_Size; se impostato, indica che il frame non ha la dimensione standard di 4 mb, ma misura invece 4 kb. In questo caso, la directory di pagina punta direttamente al frame di 4 mb, scavalcando la tabella delle pagine interna; i 22 bit meno significativi nell’indirizzo lineare indicano l’offset nella pagina di 4 mb.
Per migliorare l’efficienza d’uso della memoria fisica, le tabelle delle pagine in ia-32 possono essere trasferite sul disco. In questo caso, si ricorre a un bit invalid in ciascun elemento della directory di pagina, per indicare se la tabella a cui l’elemento punta sia in memoria o sul disco. Se è su disco, il sistema operativo può usare i 31 bit rimanenti per specificare la collocazione della tabella sul disco; in questo modo, si può richiamare la tabella in memoria su richiesta.
Non appena gli sviluppatori di software hanno iniziato a soffrire della limitazione della memoria a 4 gb imposta dall’architettura a 32 bit, Intel ha introdotto l’estensione di indirizzo della pagina (pae, page address extension), che consente ai processori a 32 bit di accedere a uno spazio di indirizzamento fisico più grande di 4 gb. La differenza fondamentale introdotta dal supporto pae era il passaggio della paginazione da una schema a due livelli (come mostrato nella Figura 9.23) a uno schema a tre livelli, in cui i primi due bit fanno riferimento a una tabella di puntatori alle directory di pagina. La Figura 9.24 illustra un sistema pae con pagine di 4 kb. pae supporta anche pagine di 2 mb.
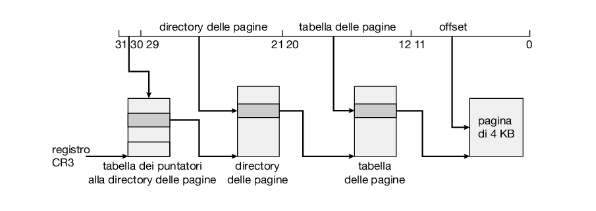
Con pae è stata inoltre aumentata la dimensione degli elementi della directory delle pagine e della tabella delle pagine, che passa da 32 a 64 bit, permettendo di estendere l’indirizzo di base delle tabelle delle pagine e dei frame da 20 a 24 bit. In combinazione con i 12 bit di offset, l’aggiunta del supporto pae a ia-32 ha aumentato lo spazio di indirizzamento a 36 bit, garantendo il supporto di un massimo di 64 gb di memoria fisica. È importante notare che per utilizzare pae è necessario il supporto del sistema operativo. Linux e macos supportano pae. Tuttavia, le versioni a 32 bit dei sistemi operativi Windows per desktop supportano soltanto 4 gb di memoria fisica, anche se pae è abilitato.
Architettura x86-64
Lo sviluppo di architetture Intel a 64 bit ha avuto una storia curiosa. La prima di queste architetture era ia-64 (in seguito denominata Itanium), ma questa architettura non ha avuto un’ampia diffusione. Nel frattempo, un altro produttore di chip – amd – ha iniziato a sviluppare un’architettura a 64 bit nota come x86-64, basata sull’estensione del set di istruzioni ia-32 esistente. L’architettura x86-64 supportava spazi di indirizzamento logico e fisico molto più grandi e introduceva diverse altre novità architetturali. Storicamente amd aveva spesso sviluppato chip basati sull’architettura Intel, ma in questo caso i ruoli si sono invertiti e Intel ha adottato l’architettura x86-64 di amd. Nel discutere questa architettura, piuttosto che utilizzare le denominazioni commerciali amd64 e Intel 64, useremo il termine più generale x86-64.
Il supporto a uno spazio di indirizzamento a 64 bit permette di indirizzare la straordinaria quantità di 2 byte di memoria – un numero superiore a 16 miliardi di miliardi (o 16 exabyte). Tuttavia, anche se i sistemi a 64 bit possono potenzialmente indirizzare una tale quantità di memoria, nella pratica vengono utilizzati nei progetti attuali assai meno di 64 bit per la rappresentazione di un indirizzo. L’architettura x86-64 utilizza attualmente un indirizzo virtuale di 48 bit con supporto ai formati di pagina di 4 kb, 2 mb o 1 gb utilizzando una paginazione a quattro livelli. La rappresentazione dell’indirizzo lineare è mostrata nella Figura 9.25. Poiché questo schema di indirizzamento può usare pae, gli indirizzi virtuali sono di 48 bit, ma supportano indirizzi fisici a 52 bit (4096 terabyte).
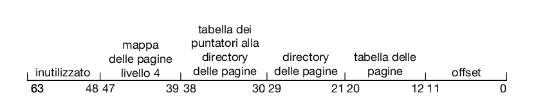
Esempio: architettura ARMv8
Anche se i chip Intel hanno dominato il mercato dei personal computer per oltre 30 anni, i dispositivi mobili come smartphone e tablet montano spesso processori arm a 32 bit. È interessante notare che mentre Intel progetta e produce i chip, arm li progetta soltanto, concedendo poi in licenza i suoi progetti ai produttori di chip. Apple ha adottato arm per i suoi dispositivi mobili iPhone e iPad e anche diversi smartphone basati su Android utilizzano processori arm. Oltre ai dispositivi mobili, arm progetta architetture per sistemi embedded real-time. Grazie alla grande varietà di dispositivi che utilizzano un’architettura arm, sono stati prodotti oltre 100 miliardi di processori arm, rendendo così questa architettura la più utilizzata in termini della quantità di chip prodotti. In questo paragrafo descriviamo l’architettura armv8 a 64 bit.
armv8 supporta tre diverse granularità di traduzione (translation granule): 4 kb, 16 kb e 64 kb. Per ogni diversa granularità sono fornite diverse dimensioni di pagina, oltre a sezioni più grandi di memoria contigua, note come regioni. Di seguito sono riportate le dimensioni di pagina e di regione per le diverse granularità di traduzione:
| Granularità | Dimensione della pagina | Dimensione della regione |
|---|---|---|
| 4 kb | 4 kb | 2 mb, 1 gb |
| 16 kb | 16 kb | 32 mb |
| 64 kb | 64 kb | 512 mb |
Con granularità di 4 kb e 16 kb è possibile utilizzare fino a quattro livelli di paginazione, mentre con granularità di 64 kb sono possibili fino a tre livelli di paginazione. La Figura 9.26 illustra la struttura degli indirizzi armv8 con una granularità di 4 kb, con un massimo di quattro livelli di paginazione. Si noti che, sebbene armv8 sia un’architettura a 64 bit, vengono attualmente utilizzati solo 48 bit. La struttura di paginazione gerarchica a quattro livelli per una granularità di traduzione di 4 kb è illustrata nella Figura 9.27, dove il registro ttbr è il registro di base della tabella di traduzione e punta alla tabella del livello 0 per il thread corrente.
Indirizzo in ARM con granularità di 4 KB:

Paginazione gerarchica su 4 livelli in ARM:
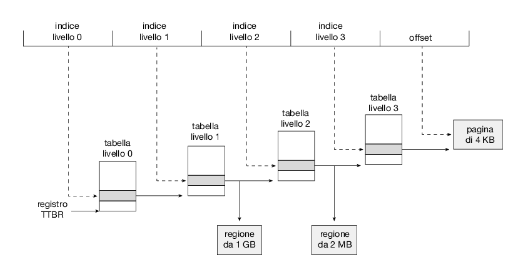
Se sono utilizzati tutti e quattro i livelli, l’offset (bit 0-11 nella Figura 9.26) si riferisce a una pagina di 4 kb. Tuttavia, si noti che gli elementi della tabella nei livelli 1 e 2 possono fare riferimento a un’altra tabella o a una regione da 1 gb (per la tabella livello 1) o da 2 mb (per la tabella livello 2). Per esempio, se la tabella di livello 1 fa riferimento a una regione da 1 gb anziché a una tabella di livello 2, i 30 bit meno significativi (bit 0-29 nella Figura 9.26) vengono utilizzati come offset per questa regione. Allo stesso modo, se la tabella di livello 2 fa riferimento a una regione da 2 mb anziché a una tabella di livello 3, i 21 bit meno significativi (bit 0-20 nella Figura 9.26) fanno riferimento all’offset all’interno di questa regione da 2 mb.
L’architettura arm supporta inoltre due livelli di tlb. A livello interno vi sono due micro tlb separati, uno per i dati e uno per le istruzioni. Il micro tlb supporta gli asid. A livello esterno vi è un unico tlb principale. La traduzione di un indirizzo inizia a livello micro tlb: in caso di insuccesso viene controllato il tlb principale. In caso di ulteriore insuccesso, ci si rivolge, via hardware, alla tabella delle pagine.
Elaborazione a 46-bit: La storia ci insegna che anche quando la capacità di memoria, la velocità della cpu e altre caratteristiche simili sembrano sufficienti a soddisfare la domanda futura, il progresso tecnologico riesce alla fine ad assorbire tutte le risorse disponibili. Ci si ritrova dunque ad aver bisogno di più memoria o di una maggior capacità di elaborazione e spesso ciò avviene prima del previsto. Che cosa ci porteranno le future tecnologie per far sembrare troppo piccoli gli indirizzi di 64 bit?